一 序列化組件
首先按照restful規范咱們創建一些api介面,按照下面這些形式寫吧:
Courses --- GET ---> 查看資料----->回傳所有資料串列[{},{},]
Courses--- POST --->添加資料 -----> 回傳添加的資料{ }
courses/1 ---PUT---> 更新pk=1的資料 ----->回傳更新后的資料{ }
courses/1 --- DELETE---> 洗掉pk=1的資料 -----> 回傳空
courses/1 --- GET --->查看單條資料 -----> 回傳單條資料 { }
這樣,我們先看一個drf給我們提供的一個類似于Postman功能的頁面,首先我們創建一個django專案,創建一個Course表,然后添加一些資料,然后按照下面的步驟操作,
第一步:引入drf的Response物件
from django.shortcuts import render,HttpResponse,redirect
import json
from django.views import View
from app01 import models
from rest_framework.views import APIView
#參考drf提供的Response物件
from rest_framework.response import Response
#寫我們的CBV視圖
class CourseView(APIView):
#回傳所有的Course資料
def get(self,request):
course_obj_list = models.Course.objects.all()
ret = []
for course_obj in course_obj_list:
ret.append({
"title":course_obj.title,
"desc":course_obj.desc,
})
# return HttpResponse(json.dumps(ret, ensure_ascii=False))
return Response(json.dumps(ret, ensure_ascii=False)) #這里使用Response來回傳訊息
def post(self,request):
print(request.data)
return HttpResponse('POST')
第二步:配置App,在我們的settings組態檔中配置
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'rest_framework', #將它注冊成App
]
第三步,配置我們的路由
"""
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^courses/', views.CourseView.as_view(),name='courses'),
]
第四步:啟動專案,通過瀏覽器訪問我們的路由(必須是瀏覽器訪問才能看到對應的功能),看效果:
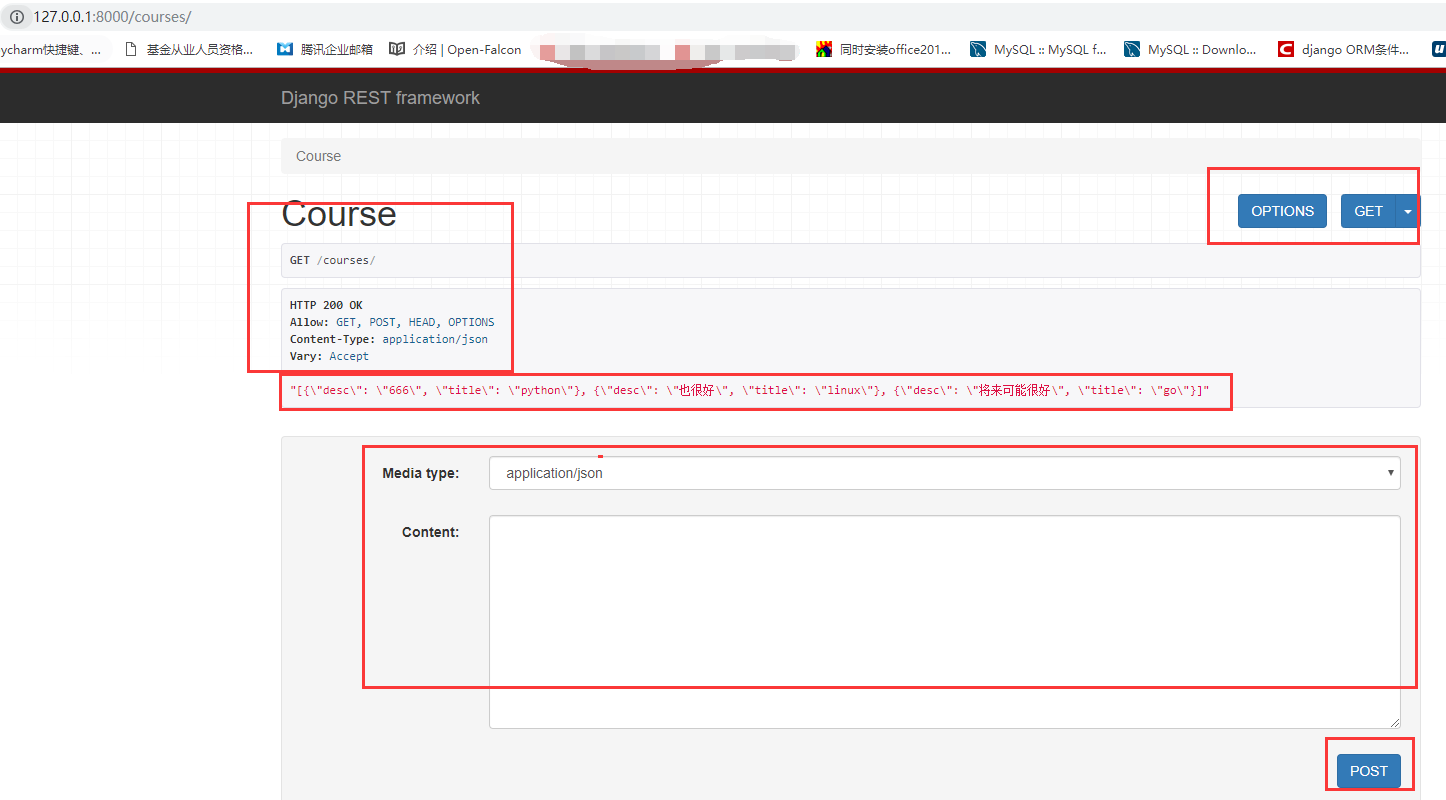
這里面我們可以發送不同型別的請求,看到對應的回傳資料,類似于Postman,但是沒有Postman好用,所以以后除錯我們還是用Postman工具,但是我們知道一下昂,
上面的資料,我們通過json自己進行的序列化,其實django也給我們提供了一個簡單的序列化組件,看用法:
from django.shortcuts import render,HttpResponse,redirect
import json
from django.views import View
from app01 import models
from rest_framework.views import APIView
from django.core.serializers import serialize #django的序列化組件,不是我們要學的drf的序列化組件昂
#不用json自己來序列化了,太麻煩,我們使用drf提供的序列化組件
from rest_framework.response import Response
class CourseView(APIView):
def get(self,request):
course_obj_list = models.Course.objects.all()
# ret = []
# for course_obj in course_obj_list:
# ret.append({
# "title":course_obj.title,
# "desc":course_obj.desc,
# })
# return HttpResponse(json.dumps(ret, ensure_ascii=False))
# return Response(json.dumps(ret, ensure_ascii=False)
se_data = https://www.cnblogs.com/changxin7/p/serialize('json',course_obj_list,ensure_ascii=False)
print(se_data)#也拿到了序列化之后的資料,簡潔很多
#[{"model": "app01.course", "pk": 1, "fields": {"title": "python", "desc": "666"}}, {"model": "app01.course", "pk": 2, "fields": {"title": "linux", "desc": "\u4e5f\u5f88\u597d"}}, {"model": "app01.course", "pk": 3, "fields": {"title": "go", "desc": "\u5c06\u6765\u53ef\u80fd\u5f88\u597d"}}]
return Response(se_data)
那么我們知道了兩個序列化方式了,這個序列化是不是就簡單很多啊,但是drf給我們做了一個更牛逼的序列化組件,功能更強大,而且不僅僅能做序列化,還能做其他的事情,所以呢,做api的時候,我們還是用drf提供的序列化組件,
import json
from datetime import datetime
from datetime import date
#對含有日期格式資料的json資料進行轉換
class JsonCustomEncoder(json.JSONEncoder):
def default(self, field):
if isinstance(field,datetime):
return field.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(field,date):
return field.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self,field)
d1 = datetime.now()
dd = json.dumps(d1,cls=JsonCustomEncoder)
print(dd)
接下來重點到了,我們玩一下drf提供的資料序列化組件:
1.我們通過GET方法,來查看所有的Course資料,
from django.shortcuts import render,HttpResponse,redirect
import json
from django.views import View
from app01 import models
from rest_framework.views import APIView
from django.core.serializers import serialize #django的序列化組件,不是我們要學的drf的序列化組件昂
#from rest_framework import status #回傳指定狀態碼的時候會用到
#return Response(se_data,status=status=HTTP_400_BAD_REQUEST)
#或者這種方式回傳來指定狀態碼:return JsonResponse(serializer.data, status=201)
from rest_framework.response import Response
# 序列化方式3,1.引入drf序列化組件
from rest_framework import serializers
# 2.首先實體化一個類,繼承drf的serializers.Serializer,類似于我們的form組件和models的用法
class CourseSerializers(serializers.Serializer):
#這里面也要寫對應的欄位,你寫了哪些欄位,就會對哪些欄位的資料進行序列化,沒有被序列化的欄位,不會有回傳資料,你可以注釋掉一個,然后看回傳的資料是啥
title = serializers.CharField(max_length=32,required=False) #序列化的時候還能校驗欄位
desc = serializers.CharField(max_length=32)
class CourseView(APIView):
def get(self,request):
course_obj_list = models.Course.objects.all()
# 3.使用我們創建的序列化類
cs = CourseSerializers(course_obj_list, many=True) # 序列化多個物件的時候,需要些many=True引數
#4.通過回傳物件的data屬性就能拿到序列化之后的資料
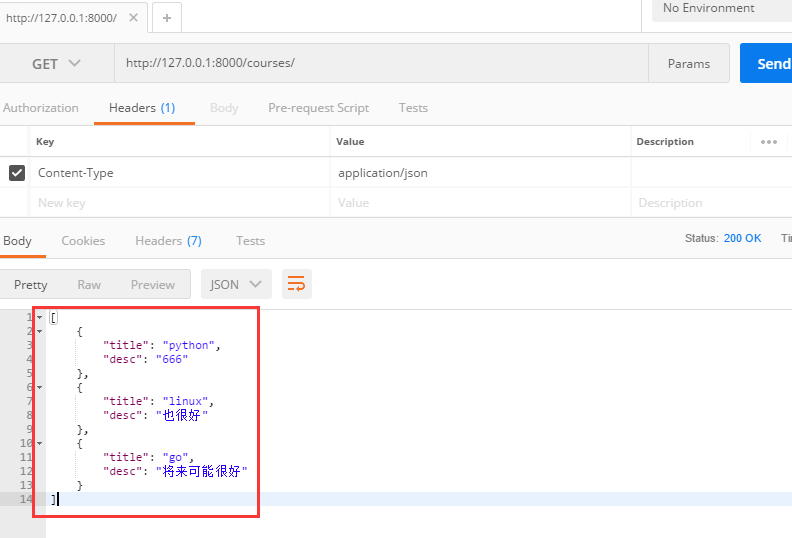
se_data = https://www.cnblogs.com/changxin7/p/cs.data
print(se_data) #[OrderedDict([('title', 'python'), ('desc', '666')]), OrderedDict([('title', 'linux'), ('desc', '也很好')]), OrderedDict([('title', 'go'), ('desc', '將來可能很好')])] 串列嵌套的有序字典,
#還記得創建字典的另外一種寫法嗎?這個沒啥用昂,給大家回顧一下之前的知識
# d1 = {'name':'chao'}
# d2 = dict([('name','chao'),('age',18)])
# print(d1) #{'name': 'chao'}
# print(d2) #{'age': 18, 'name': 'chao'}
# # 有序字典
# from collections import OrderedDict
# d3 = OrderedDict([('name','Jaden'),('age',22)])
# print(d3) #OrderedDict([('name', 'Jaden'), ('age', 22)])
return Response(se_data) #drf的Response如果回傳的是drf序列化之后的資料,那么客戶端拿到的是一個有格式的資料,不再是一行顯示了
看效果:
2.通過POST方法來添加一條資料:
from django.shortcuts import render,HttpResponse,redirect
from django.views import View
from app01 import models
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
class CourseSerializers(serializers.Serializer):
title = serializers.CharField(max_length=32)
desc = serializers.CharField(max_length=32)
class CourseView(APIView):
def get(self,request):
course_obj_list = models.Course.objects.all()
cs = CourseSerializers(course_obj_list, many=True)
se_data = https://www.cnblogs.com/changxin7/p/cs.data
return Response(se_data)
def post(self,request):
# print(request.data) #{'desc': 'java也挺好', 'title': 'java'}
#發送過來的資料是不是要進行驗證啊,drf的序列化組件還能校驗資料
cs = CourseSerializers(data=https://www.cnblogs.com/changxin7/p/request.data,many=False) #注意必須是data=這種關鍵字引數,注意,驗證單條資料的時候寫上many=False引數,而且我們還要序列化這個資料,因為我們要給客戶端回傳這個資料
# print(cs.is_valid()) #True ,如果少資料,得到的是False
if cs.is_valid():
print(cs.data)
models.Course.objects.create(**cs.data)#添加資料
return Response(cs.data) #按照post添加資料的api規則,咱們要回傳正確的資料
else:
# 假如客戶端發送過來的資料是這樣的,少title的資料
# {
# "desc": "java也挺好"
# }
cs_errors = cs.errors
# print(cs_errors) #{'title': ['This field is required.']}
return Response(cs_errors)
# postman上我們看到的效果是下面這樣的
# {
# "title": [
# "This field is required."
# ]
# }
然后添加一些資料,好,接下來我們玩一些有關聯關系的表
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField()
class AuthorDetail(models.Model):
nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField()
class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) #多對一到Publish表
authors=models.ManyToManyField(to='Author',) #多對多到Author表
看序列化代碼:
from django.shortcuts import render,HttpResponse,redirect
from django.views import View
from app01 import models
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
class BookSerializers(serializers.Serializer):
#我們先序列化寫兩個欄位的資料,別忘了這里面的欄位和model表中的欄位變數名要一樣
title = serializers.CharField(max_length=32)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
#一對多的處理
# publish = serializers.CharField(max_length=32) #回傳物件
publish_email = serializers.CharField(max_length=32, source='publish.email') # source指定回傳的多對一的那個publish物件的email資料,并且我們現在找到書籍的email,所以前面的欄位名稱就可以不和你的publish對應好了,隨便取名字
publish_name = serializers.CharField(max_length=32, source='publish.name') # source指定回傳的多對一的那個publish物件的其他欄位資料,可以接著寫欄位,也就是說關聯的所有的欄位的資料都可以寫在這里進行序列化
#對多對的處理
# authors = serializers.CharField(max_length=32) #bookobj.authors拿到的類似于一個models.Authors.object,列印的時候這是個None
# authors = serializers.CharField(max_length=32,source="authors.all") #這樣寫回傳的是queryset型別的資料,這樣給前端肯定是不行的,所以按照下面的方法寫
authors = serializers.SerializerMethodField() #序列化方法欄位,專門給多對多欄位用的,然后下面定義一個方法,方法名稱寫法是這樣的get_欄位名,名字必須是這樣
def get_authors(self,obj): #引數寫一個obj,這個obj是一個一個的書籍物件,然后我們通過書籍物件來回傳對應的資料
# author_list_values = obj.authors.all().values() #回傳這樣型別的資料也行,那么具體你要回傳什么結構的資料,需要和前端人員溝通清楚,然后這里對資料進行加工
#假如加工成的資料是這種型別的[ {},{} ],就可以按照下面的邏輯來寫,我簡單寫的,肯定有更好的邏輯來加工這些資料
author_list_values = []
author_dict = {}
author_list = obj.authors.all()
for i in author_list:
author_dict['name'] = i.name
author_list_values.append(author_dict)
return author_list_values
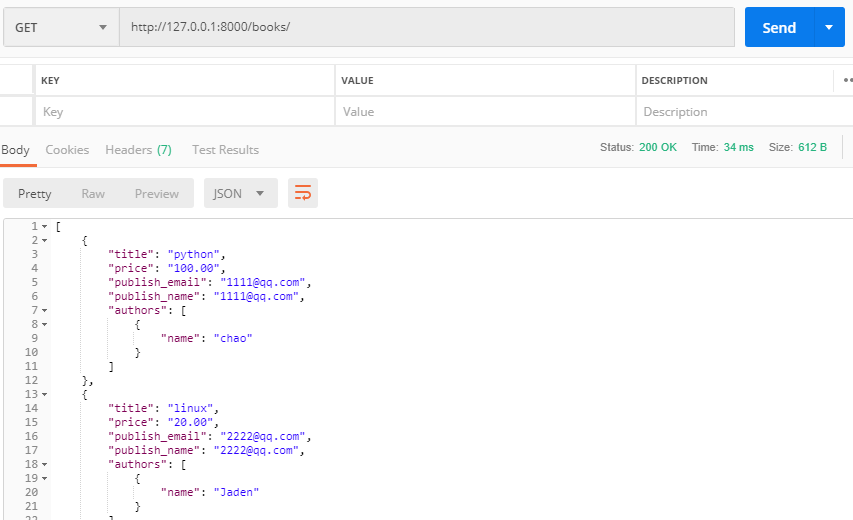
class BookView(APIView):
def get(self,request):
book_obj_list = models.Book.objects.all()
s_books = BookSerializers(book_obj_list,many=True)
return Response(s_books.data)
def post(self,request):
pass
其實serializer在內部就做了這點事兒,偽代碼昂,
urls.py是這樣寫的:
urlpatterns = [
#url(r'^admin/', admin.site.urls),
#做一些針對書籍表的介面
url(r'^books/', views.BookView.as_view(),),
]
然后看Postman回傳的資料:
那么我們就能夠完成各種資料的序列化了,但是你會發現,這樣寫太累啦,這只是一張表啊,要是上百張表咋整啊,所以還有一個更簡單的方式(類似于form和modelform的區別),
我們使用ModelSerializer,看代碼:
#ModelSerializer
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=models.Book
# fields=['title','price','publish','authors']
fields = "__all__"
# 如果直接寫all,你拿到的資料是下面這樣的,但是如果人家前端和你要的作者的id和名字,你是不是要處理一下啦
# [
# {
# "nid": 3,
# "title": "go",
# "publishDate": null,
# "price": "122.00",
# "publish": 2,
# "authors": [
# 2,
# 1
# ]
# }
# ]
#那么沒辦法,只能自己再進行加工處理了,按照之前的方式
authors = serializers.SerializerMethodField()
def get_authors(self,obj):
author_list_values = []
author_dict = {}
author_list = obj.authors.all()
for i in author_list:
author_dict['id'] = i.pk
author_dict['name'] = i.name
author_list_values.append(author_dict)
return author_list_values #這個資料就會覆寫上面的序列化的authors欄位的資料
# 那么前端拿到的資料就這樣了
# [
# {
# "nid": 3,
# "authors": [
# {
# "name": "chao",
# "id": 1
# },
# {
# "name": "chao",
# "id": 1
# }
# ],
# "title": "go",
# "publishDate": null,
# "price": "122.00",
# "publish": 2
# }
# ]
# 那如果一對多關系的那個publish,前端想要的資料是名字怎么辦呢?還是老辦法,source
# publish_name = serializers.CharField(max_length=32, source='publish.name')#但是你會發現序列化之后的資料有個publish:1對應個id值,如果我不想要他怎么辦,那么可以起個相同的變數名來覆寫它,比如下面的寫法
publish = serializers.CharField(max_length=32, source='publish.name')
class BookView(APIView):
def get(self,request):
book_obj_list = models.Book.objects.all()
s_books = BookSerializers(book_obj_list,many=True)
return Response(s_books.data)
def post(self,request):
pass
上面我們完成了get請求來查看所有的書籍資訊,接下來我們玩一個post請求添加一條book資料,直接上代碼吧:
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=models.Book
fields = "__all__"
# 注意先把下面這些注釋掉,不然由于get和post請求我們用的都是這個序列化組件,會出現多對多變數沖突的問題,所以一般都將讀操作和寫操作分成兩個序列化組件來寫
# authors = serializers.SerializerMethodField() #也可以用來處理一對多的關系欄位
# def get_authors(self,obj):
# author_list_values = []
# author_dict = {}
# author_list = obj.authors.all()
# for i in author_list:
# author_dict['id'] = i.pk
# author_dict['name'] = i.name
# author_list_values.append(author_dict)
# return author_list_values
# publish = serializers.CharField(max_length=32, source='publish.name')
class BookView(APIView):
def get(self,request):
book_obj_list = models.Book.objects.all()
s_books = BookSerializers(book_obj_list,many=True)
return Response(s_books.data)
def post(self,request):
b_serializer = BookSerializers(data=https://www.cnblogs.com/changxin7/p/request.data,many=False)
if b_serializer.is_valid():
print('xxxx')
b_serializer.save() #因為這個序列化器我們用的ModelSerializer,并且在BookSerializers類中我們指定了序列化的哪個表,所以直接save,它就知道我們要將資料保存到哪張表中,其實這句話執行的就是個create操作,
return Response(b_serializer.data) #b_serializer.data這就是個字典資料
else:
return Response(b_serializer.errors)
上面我們完成了GET和POST請求的介面寫法,下面我們來完成PUT、DELETE、GET查看單條資料的幾個介面,
#一個讀序列化組件,一個寫序列化組件
class BookSerializers1(serializers.ModelSerializer):
class Meta:
model=models.Book
fields = "__all__"
def create(self, validated_data):
print(validated_data)
#{'publishDate': datetime.date(2012, 12, 12), 'publish': <Publish: Publish object>, 'authors': [<Author: Author object>, <Author: Author object>], 'title': '老酒3', 'price': Decimal('15.00')}
authors = validated_data.pop('authors')
obj = models.Book.objects.create(**validated_data)
obj.authors.add(*authors)
return obj
class BookSerializers2(serializers.ModelSerializer):
class Meta:
model=models.Book
fields = "__all__"
authors = serializers.SerializerMethodField()
def get_authors(self,obj):
print('sssss')
author_list_values = []
author_dict = {}
author_list = obj.authors.all()
for i in author_list:
author_dict['id'] = i.pk
author_dict['name'] = i.name
author_list_values.append(author_dict)
return author_list_values
publish = serializers.CharField(max_length=32, source='publish.name')
class BookView(APIView):
def get(self,request):
book_obj_list = models.Book.objects.all()
s_books = BookSerializers2(book_obj_list,many=True)
return Response(s_books.data)
def post(self,request):
b_serializer = BookSerializers1(data=https://www.cnblogs.com/changxin7/p/request.data,many=False)
if b_serializer.is_valid():
print('xxxx')
b_serializer.save()
return Response(b_serializer.data)
else:
return Response(b_serializer.errors)
urls.py內容如下:
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# url(r'^courses/', views.CourseView.as_view()),
#做一些針對書籍表的介面
#GET和POST介面的url
url(r'^books/$', views.BookView.as_view(),), #別忘了$符號結尾
#PUT、DELETE、GET請求介面
url(r'^books/(\d+)/', views.SBookView.as_view(),),
]
views.py代碼如下:
from django.shortcuts import render,HttpResponse,redirect
from django.views import View
from app01 import models
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=models.Book
fields = "__all__"
class BookView(APIView):
def get(self,request):
'''
查看所有書籍
:param request:
:return:
'''
book_obj_list = models.Book.objects.all()
s_books = BookSerializers(book_obj_list,many=True)
return Response(s_books.data)
def post(self,request):
'''
添加一條資料
:param request:
:return:
'''
b_serializer = BookSerializers(data=https://www.cnblogs.com/changxin7/p/request.data,many=False)
if b_serializer.is_valid():
b_serializer.save()
return Response(b_serializer.data)
else:
return Response(b_serializer.errors)
#因為更新一條資料,洗掉一條資料,獲取一條資料,都有個單獨的引數(獲取一條資料的,一般是id,所以我將put、delete、get寫到了一個視圖類里面,也就是說結合上面那個BookView視圖類,完成了我們的那些介面)
class SBookView(APIView):
def get(self,request,id):'''
獲取單條資料
:param request:
:param id:
:return:
'''
book_obj = models.Book.objects.get(pk=id)#獲取這條資料物件
#接下來序列化單個model物件,序列化單個物件回傳的是一個字典結構 {},序列化多個物件回傳的是[{},{}]這種結構
book_serializer = BookSerializers(book_obj,many=False)
return Response(book_serializer.data)
def put(self,request,id):
'''
更新一條資料
:param request:request.data更新提交過來的資料
:param id:
:return:
'''
book_obj = models.Book.objects.get(pk=id)
b_s = BookSerializers(data=https://www.cnblogs.com/changxin7/p/request.data,instance=book_obj,many=False) #別忘了寫instance,由于我們使用的ModelSerializer,所以前端提交過來的資料必須是所有欄位的資料,當然id欄位不用
if b_s.is_valid():
b_s.save() #翻譯成的就是update操作
return Response(b_s.data) #介面規范要求咱們要回傳更新后的資料
else:
return Response(b_s.errors)
def delete(self,request,id):'''
洗掉一條資料
:param request:
:param id:
:return:
'''
book_obj = models.Book.objects.get(pk=id).delete()
return Response("") #別忘了介面規范說最好回傳一個空
好,五個介面寫完,咱們的序列化組件就算是講完了,別忘了看這一節最后的那個坑,
重寫save的create方法
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
# exclude = ['authors',]
# depth=1
def create(self, validated_data):
authors = validated_data.pop('authors')
obj = Book.objects.create(**validated_data)
obj.authors.add(*authors)
return obj
超鏈接API,Hyperlinked
class BookSerializers(serializers.ModelSerializer):
publish= serializers.HyperlinkedIdentityField(
view_name='publish_detail',
lookup_field="publish_id",
lookup_url_kwarg="pk")
class Meta:
model=Book
fields="__all__"
#depth=1
serializer的屬性和方法:
1.save()
在呼叫serializer.save()時,會創建或者更新一個Model實體(呼叫create()或update()創建),具體根據序列化類的實作而定,如:
2.create()、update()
Serializer中的create()和update()方法用于創建生成一個Model實體,在使用Serializer時,如果要保存反序列化后的實體到資料庫,則必須要實作這兩方法之一,生成的實體則作為save()回傳值回傳,方法屬性validated_data表示校驗的傳入資料,可以在自己定義的序列化類中重寫這兩個方法,
3. is_valid()
當反序列化時,在呼叫Serializer.save()之前必須要使用is_valid()方法進行校驗,如果校驗成功回傳True,失敗則回傳False,同時會將錯誤資訊保存到serializer.errors屬性中,
4.data
serializer.data中保存了序列化后的資料,
5.errors
當serializer.is_valid()進行校驗后,如果校驗失敗,則將錯誤資訊保存到serializer.errors屬性中,
serializer的Field:
1.CharField
對應models.CharField,同時如果指定長度,還會負責校驗文本長度,
max_length:最大長度;
min_length:最小長度;
allow_blank=True:表示允許將空串做為有效值,默認False;
2.EmailField
對應models.EmailField,驗證是否是有效email地址,
3.IntegerField
對應models.IntegerField,代表整數型別
4.FloatField
對應models.FloatField,代表浮點數型別
5.DateTimeField
對應models.DateTimeField,代表時間和日期型別,
format='YYYY-MM-DD hh:mm':指定datetime輸出格式,默認為DATETIME_FORMAT值,
需要注意,如果在 ModelSerializer 和HyperlinkedModelSerializer中如果models.DateTimeField帶有auto_now=True或者auto_add_now=True,則對應的serializers.DateTimeField中將默認使用屬性read_only=True,如果不想使用此行為,需要顯示對該欄位進行宣告:
class CommentSerializer(serializers.ModelSerializer):
created = serializers.DateTimeField()
class Meta:
model = Comment
6.FileField
對應models.FileField,代表一個檔案,負責檔案校驗,
max_length:檔案名最大長度;
allow_empty_file:是否允許為空檔案;
7.ImageField
對應models.ImageField,代表一個圖片,負責校驗圖片格式是否正確,
max_length:圖片名最大長度;
allow_empty_file:是否允許為空檔案;
如果要進行圖片處理,推薦安裝Pillow: pip install Pillow
8.HiddenField
這是serializers中特有的Field,它不根據用戶提交獲取值,而是從默認值或可呼叫的值中獲取其值,一種常見的使用場景就是在Model中存在user_id作為外鍵,在用戶提交時,不允許提交user_id,但user_id在定義Model時又是必須欄位,這種情況下就可以使用HiddenField提供一個默認值:
class LeavingMessageSerializer(serializers.Serializer):
user = serializers.HiddenField(
default=serializers.CurrentUserDefault()
)
serializer的公共引數:
所謂公共引數,是指對于所有的serializers.<FieldName>都可以接受的引數,以下是常見的一些公共引數,
1.read_only
read_only=True表示該欄位為只讀欄位,即對應欄位只用于序列化時(輸出),而在反序列化時(創建物件)不使用該欄位,默認值為False,
2.write_only
write_only=True表示該欄位為只寫欄位,和read_only相反,即對應欄位只用于更新或創建新的Model時,而在序列化時不使用,即不會輸出給用戶,默認值為False,
3.required
required=False表示對應欄位在反序列化時是非必需的,在正常情況下,如果反序列化時缺少欄位,則會拋出例外,默認值為True,
4.default
給欄位指定一個默認值,需要注意,如果欄位設定了default,則隱式地表示該欄位已包含required=False,如果同時指定default和required,則會拋出例外,
5.allow_null
allow_null=True表示在序列化時允許None作為有效值,需要注意,如果沒有顯式使用default引數,則當指定allow_null=True時,在序列化程序中將會默認default=None,但并不會在反序列化時也默認,
6.validators
一個應用于傳入欄位的驗證函式串列,如果驗證失敗,會引發驗證錯誤,否則直接是回傳,用于驗證欄位,如:
username = serializers.CharField(max_length=16, required=True, label='用戶名',
validators=[validators.UniqueValidator(queryset=User.objects.all(),message='用戶已經存在')])
7.error_message
驗證時錯誤碼和錯誤資訊的一個dict,可以指定一些驗證欄位時的錯誤資訊,如:
mobile= serializers.CharField(max_length=4, required=True, write_only=True, min_length=4,
label='電話', error_messages={
'blank': '請輸入驗證碼',
'required': '該欄位必填項',
'max_length': '驗證碼格式錯誤',
'min_length': '驗證碼格式錯誤',
})
7.style
一個鍵值對,用于控制欄位如何渲染,最常用于對密碼進行密文輸入,如:
password = serializers.CharField(max_length=16, min_length=6, required=True, label='密碼',
error_messages={
'blank': '請輸入密碼',
'required': '該欄位必填',
'max_length': '密碼長度不超過16',
'min_length': '密碼長度不小于6',
},
style={'input_type': 'password'}, write_only=True)
9.label
一個簡短的文本字串,用來描述該欄位,
10.help_text
一個文本字串,可用作HTML表單欄位或其他描述性元素中欄位的描述,
11.allow_blank
allow_blank=True 可以為空 設定False則不能為空
12.source
source='user.email'(user表的email欄位的值給這值) 設定欄位值 類似default 通常這個值有外鍵關聯屬性可以用source設定
13.validators
驗證該欄位跟 單獨的validate很像
UniqueValidator 單獨唯一
validators=[UniqueValidator(queryset=UserProfile.objects.all())
UniqueTogetherValidator: 多欄位聯合唯一,這個時候就不能單獨作用于某個欄位,我們在Meta中設定,
validators = [UniqueTogetherValidator(queryset=UserFav.objects.all(),fields=('user', 'course'),message='已經收藏')]
14.error_messages
錯誤訊息提示
error_messages={
"min_value": "商品數量不能小于一",
"required": "請選擇購買數量"
})
7.ModelSerializers
ModelSerializers繼承于Serializer,相比其父類,ModelSerializer自動實作了以下三個步驟:
1.根據指定的Model自動檢測并生成序列化的欄位,不需要提前定義;
2.自動為序列化生成校驗器;
3.自動實作了create()方法和update()方法,
使用ModelSerializer方式如下:
class StudentSerializer(serializers.ModelSerializer):
class Meta:
# 指定一個Model,自動檢測序列化的欄位
model = StudentSerializer
fields = ('id', 'name', 'age', 'birthday')
相比于Serializer,可以說是簡單了不少,當然,有時根據專案要求,可能也會在ModelSerializer中顯示宣告欄位,這些在后面總結,
model
該屬性指定一個Model類,ModelSerializer會根據提供的Model類自動檢測出需要序列化的欄位,默認情況下,所有Model類中的欄位將會映射到ModelSerializer類中相應的欄位,
關于同一個序列化組件在做get(獲取資料)和post(添加資料)時候的一些坑,直接上代碼吧(等我再深入研究一下,再給出更好的答案~~):
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=models.Book
fields = "__all__"
# 下面這個extra_kwargs暫時忽略
# extra_kwargs = {
# # 'publish': {'write_only': True}, #讓publish和authors欄位的資料只往資料庫里面寫,但是查詢展示的時候,不顯示這兩個欄位,因為我們下面配置了publish要回傳的資料叫做publish_name
# # 'authors': {'write_only': True}
# } #read_only屬性的意思是,這個欄位名稱的資料只能查看,不保存,如果用戶提交的資料中有這個欄位的資料,將會被剔除,
#在我們的BookSerializers類下面可以重寫create和update方法,但是validated_data這個資料是在用戶提交完資料過來,并且經過序列化校驗之后的資料,序列化校驗除了一些required等基礎校驗之外,還會會根據咱們寫的這個序列化組件中設定的欄位中有read_only=True屬性的欄位排除掉,這也是為什么我們在面寫多對多和一對多欄位時,如果欄位名稱和model表中多對多或者一對多的欄位名稱相同,那么用戶提交過來的資料中以這個欄位命名的資料會被剔除,那么validated_data里面就沒有多對多和一對多欄位的資料了,那么再執行create方法的時候validated_data.pop('authors')這里就會報錯,說找不到authors屬性,
# def create(self, validated_data):
# print(validated_data)
# authors = validated_data.pop('authors')
# for i in authors:
# print(i.pk)
# obj = models.Book.objects.create(**validated_data)
# obj.authors.add(*authors)
# return obj
authors_list = serializers.SerializerMethodField() #注意,當你用這個序列化組件既做查詢操作,又做添加資料的操作,那么這個欄位的名字不能和你models中多對多欄位的名字相同,這里也就不能叫做authors
# authors = serializers.SerializerMethodField()
# authors_list = A() #報錯:{"authors_list": ["This field is required."]},也就是說,如果我們將SerializerMethodField中的read_only改成False,那么在進行欄位驗證的時候,這個欄位就沒有被排除,也就是說,必須傳給我這個authors_list名字的資料,但是如果我們前端給的資料中添加了這么一個資料authors_list:[1,2]的話,你會發現還是會報錯,.is_valid()這里報錯了,為什么呢,因為,序列化組件校驗的時候,在model表中找不到一個叫做authors_list的欄位,所以還是報錯,所以,在這里有個辦法就是將這個序列化組件中的這個欄位改個名字,不能和authors名字一樣,并且使用默認配置(也就是read_only=true)
# def get_authors_list(self,obj):
def get_authors_list(self,obj):
author_list_values = []
author_list = obj.authors.all()
for i in author_list:
author_dict = {}
author_dict['id'] = i.pk
author_dict['name'] = i.name
author_list_values.append(author_dict)
return author_list_values
# publish = serializers.CharField(max_length=32, source='publish.name',read_only=True) #如果這個欄位名字和資料表中外鍵欄位名稱相同,并且設定了read_only=True屬性,那么當用戶提交資料到后端保存的時候,就會報錯NOT NULL constraint failed: app01_book.publish_id,1.要么你將這個名字改成別的名字,2.要么去資料庫表中將這個欄位設定一個null=True,但是第二種方式肯定是不太好的,記住,當你獲取資料時,使用這個序列化組件,即便是這個欄位的名字和資料表中欄位名字相同,也是沒有問題的,只有在用戶提交資料保存的時候才會有問題,所以最好的解決方式就是加read_only屬性,并且改一下欄位名字,不要和資料表中這個欄位的名字相同
publish_name = serializers.CharField(max_length=32, source='publish.name',read_only=True)
二 視圖組件(Mixin混合類)
按照我們上面的序列化組件的視圖,接著寫,我們上面只說了一個Book表的幾個介面操作,但是我們是不是還有其他表呢啊,如果我們將上面的四個表都做一些序列化的介面操作,我們是不是按照下面的方式寫啊
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import *
from django.shortcuts import HttpResponse
from django.core import serializers
from rest_framework import serializers
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
#depth=1
class PublshSerializers(serializers.ModelSerializer):
class Meta:
model=Publish
fields="__all__"
depth=1
class BookViewSet(APIView):
def get(self,request,*args,**kwargs):
book_list=Book.objects.all()
bs=BookSerializers(book_list,many=True,context={'request': request})
return Response(bs.data)
def post(self,request,*args,**kwargs):
print(request.data)
bs=BookSerializers(data=https://www.cnblogs.com/changxin7/p/request.data,many=False)
if bs.is_valid():
print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
class BookDetailViewSet(APIView):
def get(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,context={'request': request})
return Response(bs.data)
def put(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,data=https://www.cnblogs.com/changxin7/p/request.data,context={'request': request})
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
class PublishViewSet(APIView):
def get(self,request,*args,**kwargs):
publish_list=Publish.objects.all()
bs=PublshSerializers(publish_list,many=True,context={'request': request})
return Response(bs.data)
def post(self,request,*args,**kwargs):
bs=PublshSerializers(data=https://www.cnblogs.com/changxin7/p/request.data,many=False)
if bs.is_valid():
# print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
class PublishDetailViewSet(APIView):
def get(self,request,pk):
publish_obj=Publish.objects.filter(pk=pk).first()
bs=PublshSerializers(publish_obj,context={'request': request})
return Response(bs.data)
def put(self,request,pk):
publish_obj=Publish.objects.filter(pk=pk).first()
bs=PublshSerializers(publish_obj,data=https://www.cnblogs.com/changxin7/p/request.data,context={'request': request})
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
好,這樣,我們看一下面向物件多繼承的用法:
class Animal:
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print('吃')
def drink(self):
print('喝')
#eat和drink才是動物共有的,下面三個不是共有的,所以直接這么些就不合適了,所以看下面的寫法,單獨寫一些類,其他一部分動物有的,放到一個類里面,在多繼承
# def eatshit(self):
# print('吃s')
# def zhiwang(self):
# print('織網')
# def flying(self):
# print('飛')
class Eatshit:
def eatshit(self):
print('吃s')
class Zhiwang:
def zhiwang(self):
print('織網')
class Flying:
def zhiwang(self):
print('織網')
class Jumping:
def zhiwang(self):
print('跳')
class Dog(Animal,Eatshit):pass
class Spider(Animal,Zhiwang):pass
class Bird(Animal,Flying):pass
class Daishu(Animal,Flying,Jumping):pass
那好,基于這種繼承形式,我們是不是就要考慮了,我們上面對每個表的那幾個介面操作,大家的處理資料的邏輯都差不多啊,而且你會發現,這么多表,我每個表的GET、PUT、DELETE、POST操作其實都差不多,基本上就兩個地方再發生變化,這里我們稱為兩個變數,
publish_list=Publish.objects.all() #表所有的資料
bs=PublshSerializers(publish_list,many=True,context={'request': request}) #序列化組件
Mixin混合類
關于資料邏輯處理的操作,drf幫我們封裝好了幾個Mixin類,我們來玩一下就行了,看代碼:
from django.shortcuts import render,HttpResponse,redirect
from django.views import View
from app01 import models
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
#將序列化組件都放到一個單獨的檔案里面,然后引入進來
from app01.serializer import BookSerializers,PublishSerializers
from rest_framework import generics
from rest_framework.mixins import ListModelMixin,CreateModelMixin,UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin
# ListModelMixin 查看所有資料,對應著咱們上面的get查看所有資料的介面
# CreateModelMixin 添加資料的操作,封裝了一個create操作,對應著上面的POST添加資料的幾口
# UpdateModelMixin 更新
# DestroyModelMixin 銷毀(洗掉)
# RetrieveModelMixin 獲取單條資料
# 我們自己提煉出,說,每個表的操作基本都是上面的get、post、delete、put操作,所以我們想將這幾個方法提煉出來,將來供其他類來繼承使用,那么drf幫我們封裝好了,就是這幾個Minin類
class PublishView(ListModelMixin,CreateModelMixin,generics.GenericAPIView):
'''
GenericAPIView肯定繼承了APIView,因為APIView里面的功能是我們必須的,而這個GenericAPIView是幫我們做銜接用的,把你的APIView的功能和我們的Minin類的功能銜接、調度起來的
'''
#繼承完了之后,我們需要將我們前面各個表的序列化中提煉的兩個不同的變數告訴咱的類,注意,下面的兩個變數名就是他們倆,不能改,并且必須給
queryset = models.Publish.objects.all()
serializer_class = PublishSerializers
def get(self,request):
'''
分發找到對應的請求方法,就是咱的get方法,而處理資料的邏輯是繼承的那個ListModelMixin類里面的list方法做了,所以我們只需要return self.list(request方法就行了,處理資料的邏輯就不要我們自己再寫了
:param request:
:return:
'''
return self.list(request) #list方法幫我們做了序列化
#post方法添加一條資料,我們只需要執行一下CreateModelMixin類中的create方法就行了
def post(self,request):
return self.create(request)
class SPublishView(UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin,generics.GenericAPIView):
#下面這兩個變數和對應資料是必須給的
queryset = models.Publish.objects.all()
serializer_class = PublishSerializers
# def get(self,request,id):#id就不需要傳了,因為人家要求在url中添加的命名分組的pk引數自動來做了
def get(self,request, *args, **kwargs): #*args, **kwargs是為了接收url的那些引數的,咱們寫的有個pk引數,
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
序列化組件的類我們放到了一個單獨的檔案中,名字叫做serializer.py,內容如下
from app01 import models
from rest_framework import serializers
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=models.Book
fields = "__all__"
class PublishSerializers(serializers.ModelSerializer):
class Meta:
model=models.Publish
fields = "__all__"
urls.py內容如下:
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [#publish表的介面
url(r'^publishs/$', views.PublishView.as_view(),),
# url(r'^publishs/(\d+)/', views.SPublishView.as_view(),),
#使用UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin這類Mixin類的時候,人家要求必須有個命名分組引數,名字叫做pk,名字可以改,但是先這樣用昂
url(r'^publishs/(?P<pk>\d+)/', views.SPublishView.as_view(),),
]
玩了這些drf混合類之后,你會發現,處理資料的相同的邏輯部分被省略了,代碼簡化了不少,
但是你看,我們上面只是寫了一個publish表的操作,咱們還有好多其他表呢,他們的操作是不是也是GET、POST、DELETE、PUT等操作啊,所以你想想有沒有優化的地方
####################Author表操作##########################
ListCreateAPIView類就幫我們封裝了get和create方法
class AuthorView(generics.ListCreateAPIView):
queryset = models.Author.objects.all()
serializer_class = AuthorSerializers
#RetrieveUpdateDestroyAPIView這個類封裝了put、get、patch、delete方法
class SAuthorView(generics.RetrieveUpdateDestroyAPIView):
queryset = models.Author.objects.all()
serializer_class = AuthorSerializers
然后你再看,還有優化的地方,上面這兩個類里面的東西是一樣的啊,能不能去重呢,當然可以了,一個類搞定,看寫法
#####################再次封裝的Author表操作##########################
from rest_framework.viewsets import ModelViewSet #繼承這個模塊
class AuthorView(ModelViewSet):
queryset = models.Author.objects.all()
serializer_class = AuthorSerializers
但是url要改一改了,看url的寫法:
#這兩個url用的都是上面的一個類url(r'^authors/$', views.AuthorView.as_view({"get":"list","post":"create"}),),
url(r'^authors/(?P<pk>\d+)/', views.AuthorView.as_view({
'get': 'retrieve',
'put': 'update',
'patch': 'partial_update',
'delete': 'destroy'
}),),
然后大家重啟一下自己的程式,通過postman測一下,肯定可以的,
好,那這個東西怎么玩呢?有興趣的,可以去看看原始碼~~~
其實原始碼中最關鍵的點是這個:
def view(request, *args, **kwargs):
self = cls(**initkwargs)
# We also store the mapping of request methods to actions,
# so that we can later set the action attribute.
# eg. `self.action = 'list'` on an incoming GET request.
self.action_map = actions
# Bind methods to actions
# This is the bit that's different to a standard view #就下面這三句,非常巧妙
for method, action in actions.items(): {'get':'list',}
handler = getattr(self, action) #肯定能找到對應的方法list handler = self.list
setattr(self, method, handler) #self.get = self.list 后面再執行dispatch方法之后,那個handler = getattr(self,request.method.lower()) #找到的是list方法去執行的,因為self.get等于self.list了,然后執行list方法,回傳對應的內容
咱們上面做的都是資料介面,但是還有邏輯介面,比如登陸,像這種資料介面就直接寫個 class Login(APIView):pass這樣來搞就行了,封裝的越簡單,內部邏輯越復雜,自定制來就越復雜,所以關于不同的邏輯,我們就自己單寫,
注意1:
#通過self在繼承類之間呼叫變數,現在是我們通過Dog類繼承的Animal類中呼叫了Running類中的變數,也就是說如果你在某個類中找不到對應的屬性,有可能在其他類里面放著了
class Animal:
x=10
def foo(self):
print(self.x)
class Running:
x = 20
#在Animal類中加一個類變數x,然后把下面繼承的兩個類的順序發生一下變化,你看看會出現什么情況
class Dog(Animal,Running):
# class Dog(Running, Animal):
pass
d = Dog()
d.foo() #20
注意2:給函式傳一個字典資料進去,到底這個字典給了下面哪個形參,
def f1(action,**kwargs):
print(action)
print(kwargs)
f1({'name':'chao'}) #結果:{'name': 'chao'} {}
# f1(x=1) #報錯:TypeError: f1() missing 1 required positional argument: 'action'
f1(1,x=1) #結果: 1 {'x': 1}
然后大家好奇嗎,想不想去看看put\get\delete的操作中,url里面的那個pk命名路由,到底為啥叫pk,并且,它自己在內部怎么通過pk值找到對應的那個更新之前的原來的model物件的啊?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/32430.html
標籤:架構設計
上一篇:分布式事務,解決方案
下一篇:什么是微服務,微服務簡介