假設我們有一個這樣的資料框,并希望在滿足某些條件時洗掉列。
df = pd.DataFrame(
np.arange(2, 14).reshape(-1, 4),
index=list('ABC'),
columns=pd.MultiIndex.from_arrays([
['data1', 'data2','data1','data2'],
['F', 'K','R','X'],
['C', 'D','E','E']
], names=['meter', 'Sleeper','sweeper'])
)
df
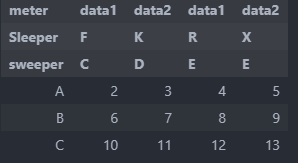
然后讓說,我們只想洗掉的cols時meter == data1和sweeper == E
,所以我嘗試
df = df.drop(('data1','E'),axis = 1)
密鑰錯誤:'E'
第二次嘗試
df.drop(('data1','E'), axis = 1, level = 2)
KeyError:“在關卡中找不到標簽 [('data1', 'E')]”
Pandas:從多級列索引中洗掉一個級別?
uj5u.com熱心網友回復:
似乎drop不支持選擇拆分級別([0,2]此處)。我們可以使用條件創建一個掩碼,而不是使用get_level_values:
# keep where not ((level0 is 'data1') and (level2 is 'E'))
col_mask = ~((df.columns.get_level_values(0) == 'data1')
& (df.columns.get_level_values(2) == 'E'))
df = df.loc[:, col_mask]
我們也可以通過排除特定索引切片中的 locs 來通過整數位置來做到這一點,但是,這總體上不太清晰且不太靈活:
idx = pd.IndexSlice['data1', :, 'E']
cols = [i for i in range(len(df.columns))
if i not in df.columns.get_locs(idx)]
df = df.iloc[:, cols]
兩種方法都會產生df:
meter data1 data2
Sleeper F K X
sweeper C D E
A 2 3 5
B 6 7 9
C 10 11 13
uj5u.com熱心網友回復:
您必須單獨執行它們,因為它們處于不同的級別:
df.drop('data1', axis=1, level='meter').drop('E', axis = 1, level='sweeper')
Out[833]:
meter data2
Sleeper K
sweeper D
A 3
B 7
C 11
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/325897.html