一、字符指標
字符指標即指向字符型別的指標char*;
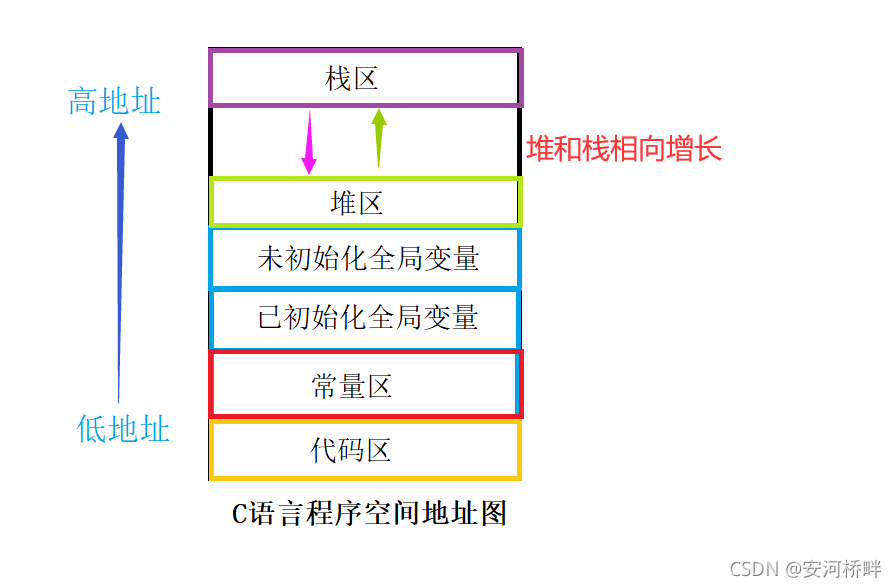
我們知道C語言中字串有兩種保存方式:陣列保存和指標保存,這兩種方式從本質上來說有著很大的區別,
如圖所示:陣列保存時,在堆疊上開辟空間,字串可以被訪問修改;指標保存時,字串保存在常量區,只可被訪問,不能修改,
看下面這個程式:
#include <stdio.h>
int main()
{
char str1[] = "hello world!";
char str2[] = "hello world!";
char *str3 = "hello world!";
char *str4 = "hello world!";
if(str1 ==str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if(str3 ==str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
運行結果:
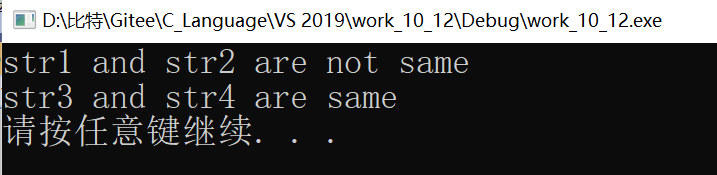
str1和str2代表的是陣列首元素的地址,而str1和str2是兩個不同的陣列,所以首元素地址不相同,str3和str4是兩個指標,都指向保存在字符常量區的同一個字串,所以地址值相同,
二、陣列指標和指標陣列
(一)區分
初學時容易混淆,所以先區分這兩個概念,
1.從語言描述上
根據漢語定語修飾詞在前,主語在后的習慣,“陣列指標”中的“陣列”是定語,“指標”是主語,所以陣列指標是指標,而對于指標,我們第一反應就是這個指標指向什么,顯然,陣列指標是指向陣列的,“指標陣列”剛好相反,所以指標陣列是陣列,且存放的內容是指標,
2.從書寫形式
看運算子的優先級
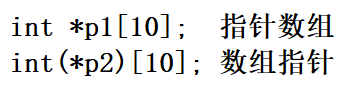
由于 [ ] 的優先級比*高,所以p1先和 [ ] 結合,必然是陣列;p2有圓括號,所以先和*結合,構成指標,
(二)指標陣列
1.定義
指標陣列是一個存放指標的陣列,如:
int *p[10];//一個陣列,存放的內容是整型指標
int **p2[10];//存放二級整型指標的陣列
2.指標陣列的使用
整型指標陣列
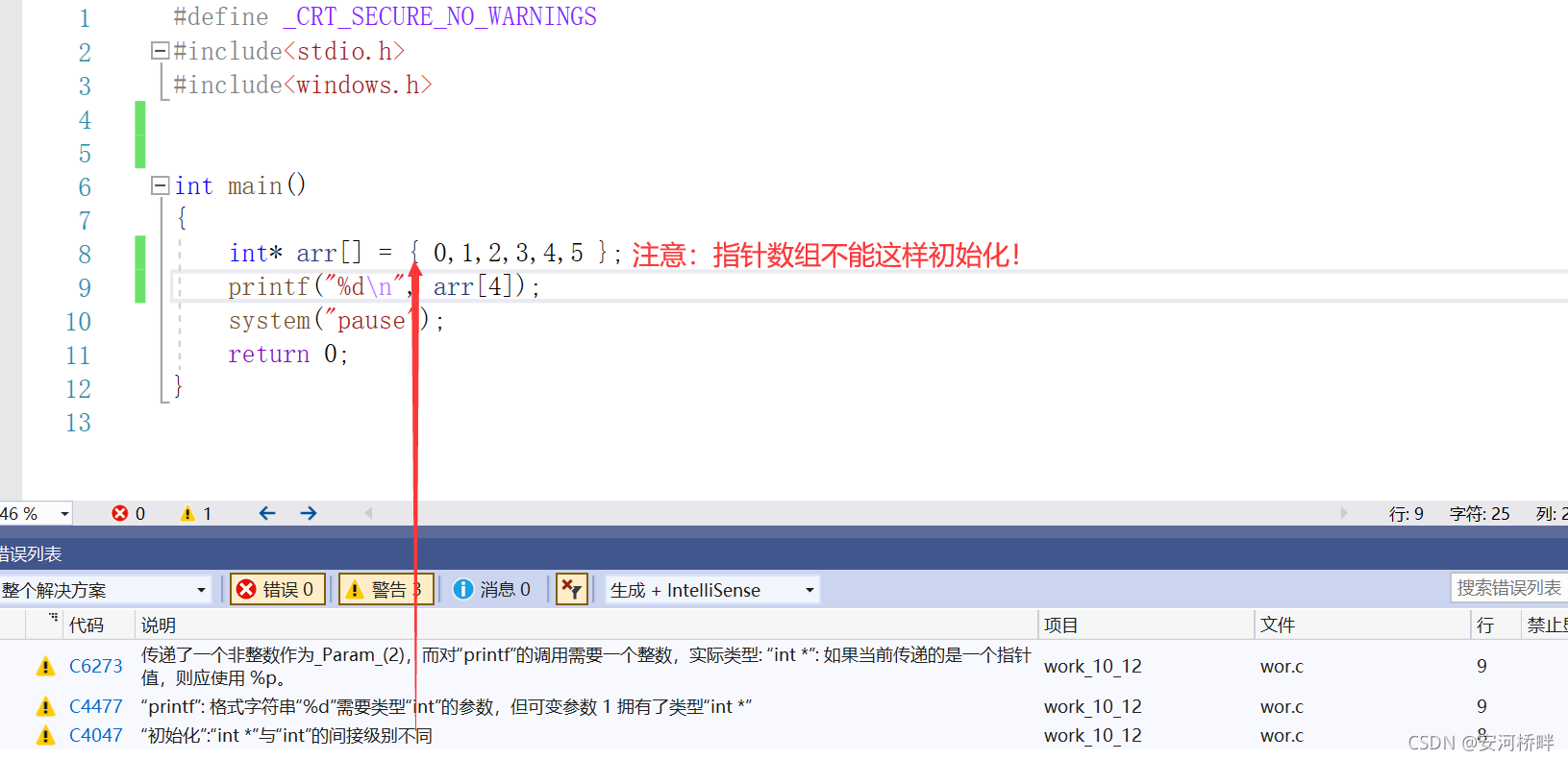
在使用整型陣列指標時,要注意,不能直接將整型變數賦值給指標陣列,因為指標陣列的元素型別時int*,而賦予的變數型別是int型,型別不匹配,
如圖:定義了一個整型指標陣列并初始化,編譯以后會發現程式有告警,
字符指標陣列
字符指標陣列可以直接賦值:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<windows.h>
int main()
{
char* arr[] = { "I","am ","gonna"," make"," the",\
" world"," a", "better"," place" };
printf("%s\n",arr[5]);//列印陣列的第五個元素
system("pause");
return 0;
}
程式運行結果:

在這里,一個容易犯的錯誤就是列印輸出時加上*解參考,導致程式崩潰:
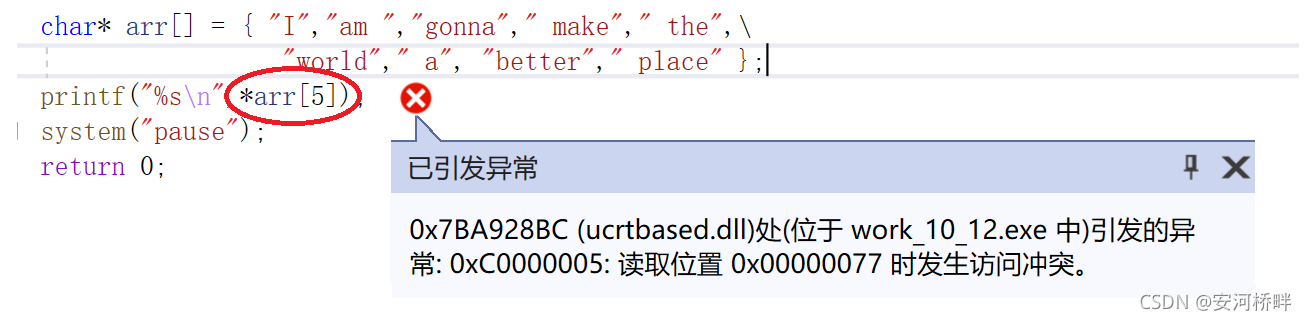
arr[5]本質上是一個指向指向字串"world"的首元素的指標,對其解參考得到的是字符’w’,而如果以s%的形式列印輸入,便會引起程式崩潰,
補充:陣列下標訪問和指標訪問
定義一個陣列:
int num=0;
int arr[5][5]={};
下面這兩種方式訪問的是同一個元素:
num=arr[3][3];
num=*(*(arr+3)+3);
陣列訪問的方式很容易理解,下面對指標訪問的方式進行分析:
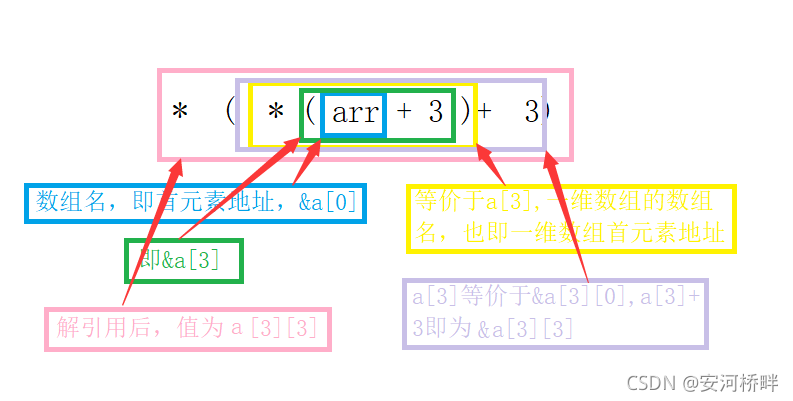
arr是陣列名,在這里代表首元素地址,即arr[0]的地址,arr[0]的地址+3表示陣列第四個元素的地址,即a[3],而C語言中,a[3]表示一維陣列的陣列名,根據前面的結論,陣列名即首元素地址,所以a[3]表示a[3][0] 的地址,&a[3][0]+3即為a[3][3]的地址,再解參考便是a[3][3],
(三)陣列指標
1.定義
int(*p)[10];//因為[]優先級比*高,所以要加括號
需要注意的是,陣列的型別不僅指元素型別,還包括陣列元素的個數,所以陣列指標的型別也包括陣列元素的個數,這里p指標指向的是一有10個整型元素的陣列,
2.陣列名與&陣列名的區別
定義一個指標陣列arr,分給列印arr和&arr:
int*arr[10]={0};
printf("%p\n ",arr);
printf("%p\n ",&arr);

列印結果相同,但是他們真的完全按一樣嗎?
通過下面這程式可以深刻理解數字名與&陣列名的區別:
#include <stdio.h>
#include<Windows.h>
int main()
{
int arr[10] = { 0 };
printf("arr = %p\n", arr);
printf("&arr= %p\n", &arr);
printf("arr+1 = %p\n", arr + 1);
printf("&arr+1= %p\n", &arr + 1);
system("pause");
return 0;
}
運行結果:

可見,arr+1是首元素地址加1,加上其所指向內容的大小,即4個位元組;而&arr+1加上的是40個位元組,是整個陣列的大小,
對程式稍作更改,陣列第一個和第二個元素分別賦值為1和2,查看記憶體,得到下面的結果:

很明顯,對arr解參考得到的是陣列第一個元素的值,所以arr代表的是陣列首元素的地址;而對&arr解參考得到的是一個陣列,所以從&arr是整個陣列的地址,從本質上來說,&arr是陣列指標型別,
結論:陣列名在&后面和單組在sizeof中出現時表示整個陣列,其余所有情況都表示陣列首元素的地址,
3.陣列指標的使用
陣列指標主要在函式傳參時使用,用于接收二維陣列,
三、陣列和指標的傳參問題
一維陣列傳參
一維陣列作函式實參時,形參可以是一維陣列或者指標,
定義一個一維陣列,讓其作實參:
int arr[10];
Sort(arr);//呼叫sort函式
引數arr的型別是一個指向整型的指標,形參可以是下面任意一個:
void Sort(int *arr);//整型指標
void Sort(int arr[]);//整型陣列
二維和多維陣列
多維陣列名作為函式引數傳遞的方式本質和一維陣列相同——傳遞一個指向陣列第一個元素的指標,但是,區別就是,多維陣列的每個元素本身是另外一個陣列,編譯器需要知道它的維數,以便于為函式形參的下標運算式求值,
二維陣列做實參,形參可以是二維陣列或一個陣列指標,且這個陣列指標必須是指向二維陣列的元素型別的指標,如:
int arr[3][10];//定義一個二維陣列
Sort(arr);//呼叫Sort函式,arr作形參
形參可以是以下型別:
void Sort(int (*arr)[10]);//定義一個指向10個整型變數的陣列指標
void Sort(int arr[][10]);//定義一個陣列(二維),其元素型別是有10個整型變數的一維陣列
這里的關鍵是編譯器必須知道第2個及以后各維的長度才能對各下標進行求值,因此形參必須宣告這些維度的長度,
比如,下面的這一組不能作為形參接收二維陣列:
void Sort(int **arr);//定義了一個二級指標,即指向整型指標的指標
void Sort(int *arr[10])//指標陣列
這兩個都和實參arr的型別不匹配,所以不能作形參,
多維陣列傳參和二維陣列原理相同,只有第一個維度可以省略,二維及以上都不能省,用陣列指標時,型別也必須是指向陣列元素型別的指標,
一級指標傳參
一級指標作實參,形參可以是一維陣列或者一級指標,
二級指標傳參
二級指標作傳參,形參可以是二級指標、指標陣列,
傳參規則總結
- 當二級指標作為函式形參時,能作為函式實參的是二級指標,指標陣列,一級指標的地址
- 當陣列指標作為函式形參時,能作為函式實參的是二維陣列,陣列指標
- 當二維陣列作為函式形參時,能作為函式實參的是二維陣列,陣列指標
- 當指標陣列作為函式形參時,能作為函式實參的是指標陣列,二級指標,一級指標的地址
對于二維陣列和陣列指標,有一個共同點,在定義時二維陣列必須定義第二維的大小,而陣列指標也必須指定其所指向的陣列的大小,所以他們可以互相作為引數,
而對于指標陣列,其陣列名本質上是一個指向陣列第一個元素的指標,即二級指標,型別匹配,所以可以作為形參接收二級指標,并被二級指標接收,
四、函式指標及其應用
(一)函式指標
定義
指向函式地址的指標
int fun();//函式宣告
int (*pf)()=&fun//定義一個函式指標,指向fun函式
上面程式中,便是函式指標,定義函式指標時需注意優先級,變數名后面的()優先級比*高,所以要加(),
另外,函式名在使用時編譯器會自動將其轉換為函式指標,所以單目運算子&可以省略,即&fun和fun等價,函式名實際存放的是函式入口的地址,
使用
對函式指標定義并初始化以后,便可以使用,看下面三種方式:
int num=0;
num=fun(10);//1
num=(*pf)(10);//2
num=pf(10);//3
第一種:如上所述,函式名存放的是函式入口的地址,所以使用函式名呼叫函式的具體執行程序是,函式名fun首先被轉換成一個函式指標,這個指標指向函式在記憶體中的存放位置,然后執行指標所指向位置的代碼,
第二種:對pf進行解參考操作,指向函式名,在執行與第一種相同的步驟,
第三種:與第二種相同,運算子*在實際使用中可以被省略,
代碼決議
- First
//代碼1
(*(void (*)())0)();
結論:這是一個從0地址處開始的函式呼叫
決議:
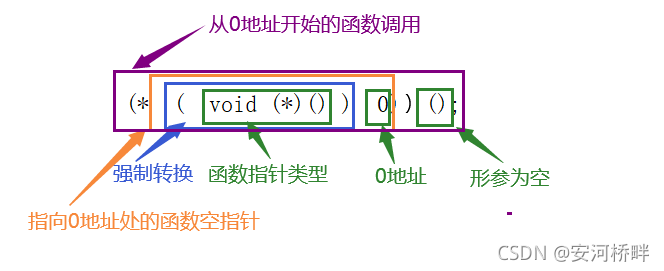
這里需要注意的是,0是一個常數,可以被當作地址來看待,也可以被強制轉換為其他型別的指標,比如函式指標,然后只需要從里向外層層分解就可以理解這個陳述句的含義,
- Second
//代碼2
void (*signal(int , void(*)(int)))(int);
結論:這是一個回傳型別是函式指標的函式宣告,該函式的引數是一個int型別和一個函式指標
決議:
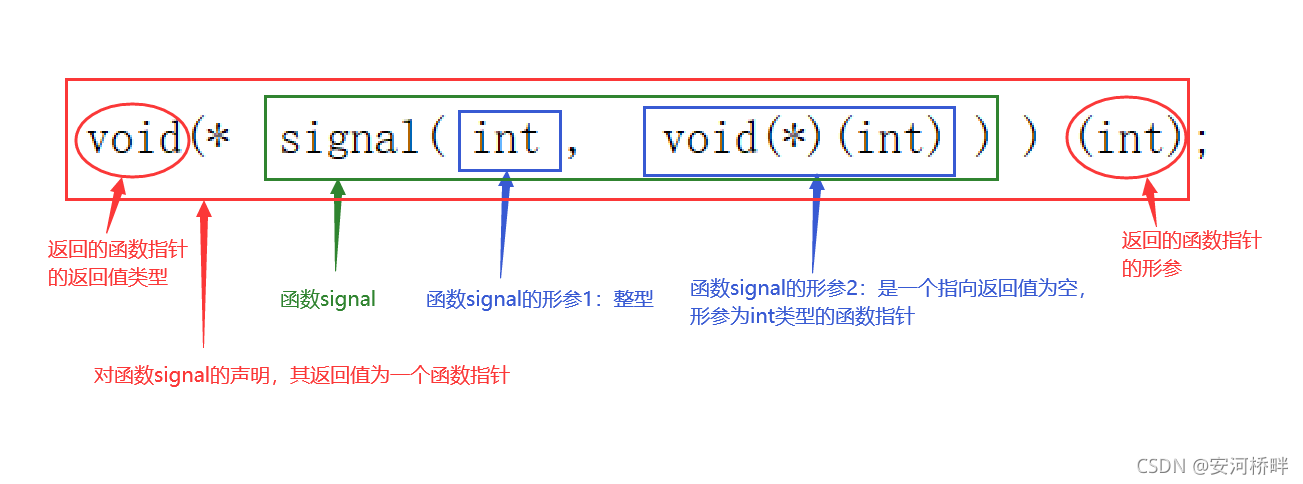
這里要理解的關鍵是signal函式的回傳值型別是一個函式指標,可以把綠色方框內整體看作一個函式如:signal(),忽略其形參,而該函式的回傳值是一個函式指標:void(*)int,便可以得到:void (*signal() ) (int),最后將函式的形參填入即可,
(二)函式指標陣列
定義
把函式的地址存放到陣列中,即為函式指標陣列,如:
int (*arr[10])(int);
arr是一個函式指標陣列,陣列記憶體放的是指向回傳值為int,形參也為int的函式指標,
應用:轉移表
使用函式指標陣列設計一個計算器,程式如下:
#include<stdio.h>
#include<windows.h>
#include<stdlib.h>//exit函式頭檔案
void Menu()//選單
{
printf("#####################################\n");
printf("###### 1.Add 2.Sub ######\n");
printf("###### 3.Mul 4.Div ######\n");
printf("###### 0.Exit ######\n");
printf("#####################################\n");
}
int MyExit(int x,int y)//退出函式
{
exit(0);//exit函式需要有引數,可以設為0
}
int Add(int x,int y)
{
return x + y;
}
int Sub(int x,int y)
{
return x - y;
}
int Mul(int x,int y)
{
return x * y;
}
int Div(int x,int y)
{
//除法要先判斷被除數不能為0
if (y == 0) {
printf("Warning:Div zero!\n");
return -1;
}
return x / y;
}
int main()
{
int x = 0;
int y = 0;
int select = 0;//接收選項
int ret = 0;//運算結果
int (*p[])(int, int) = { MyExit,Add,Sub,Mul,Div };//轉移表
char* operators = "+-*/";//將符號保存在字串中
while (1)
{
Menu();
printf("Please select:");
scanf_s("%d", &select);
if (select >= 1 && select <= 4) {
printf("Please enter the number:");
scanf_s("%d %d", &x, &y);
ret = p[select](x, y);//通過函式指標陣列呼叫函式
printf("%d %c %d=%d \n", x, operators[select - 1], y, ret);//下標方式訪問operators
}
else if (select == 0) {
printf("Bye-bye!\n");
p[0](0, 0);//0為占位符,沒有實際意義
}
else
printf("Enter error!\n");
}
system("pause");
return 0;
}
這里之所以能使用函式指標陣列,是因為四則運算的每個函式型別相似,都有兩個型別相同的引數,回傳值型別也相同,這樣用函式指標陣列呼叫的方式,減少了很多重復代碼,
(三)指向函式指標陣列的指標
指向函式指標陣列的指標是一個指標,它指向的是一個陣列,這個陣列保存的是函式指標,
int fun(int x)
{
return x;
}
int (*pfun)(int)=&test;//函式指標,&可以不寫
int (*pfun_arr[])(int);//函式指標陣列
int (*(*p_pfun_arr)[])(int)=&(*pfun[])(int);//指向函式指標陣列的指標
▲(四)回呼函式
1. 概念
回呼函式就是一個通過函式指標呼叫的函式,如果你把函式的指標(地址)作為引數傳遞給另一個函式,當這個指標被用來呼叫其所指向的函式時,我們就說這是回呼函式,回呼函式不是由該函式的實作方直接呼叫,而是在特定的事件或條件發生時由另外的一方呼叫的,用于對該事件或條件進行回應,
2.應用——qsort函式
qsort是C語言的庫函式,包含在<stdlib.h>頭檔案下,可以對任意資料型別進行排序

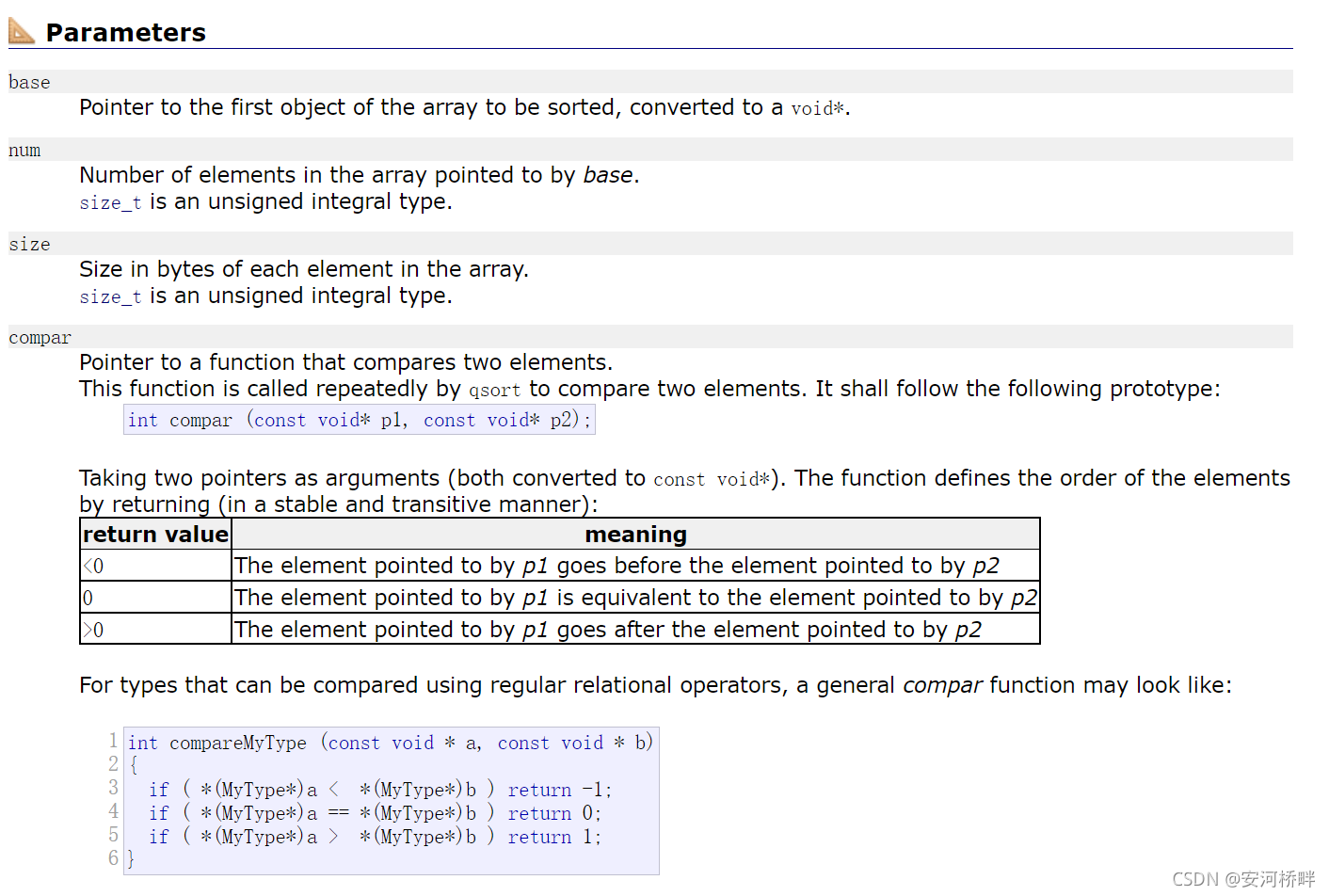
這個函式共有4個引數:
- base:void*型別,指向要排序的資料的起始地址處,
- num:unsigned int型別,要進行比較的資料個數,
- size:資料的大小,
- compar:函式指標型別,它指向一個用于比較指定型別的兩個資料大小的函式,這個函式由使用者自己寫出,它傳入的引數是進行比較的兩個資料的地址,回傳值為正數、負數、或者0,回傳值決定排序按升序還是降序進行,
int型資料qsort排序
#include<stdio.h>
#include<Windows.h>
#include<assert.h>
int int_compare(const void* x, const void* y)
{
assert(x);//判斷指標合法性
assert(y);
const int* x_ = (const int*)x;//將函式引數強轉成int*型別并賦值給x_
const int* y_ = (const int*)y;
if (*x_ > *y_) {
return 1;
}
else if (*x_ == *y_) {
return 0;
}
else {
return -1;
}
}
int main()
{
int arr[] = { 10,24,98,19,2,8 };
int num = sizeof(arr) / sizeof(arr[0]);
qsort(arr, num, sizeof(int), int_compare);
for (int i = 0; i < num; i++) {
printf("%d ", arr[i]);
}
system("pause");
return 0;
}
double型qsort排序
double型別的資料比較大小,原理與int相同,區別就是compare函式的寫法,有一點需要注意,double型資料不能用‘==’比較,
#include<stdio.h>
#include<Windows.h>
#include<assert.h>
int double_compare(const void* x, const void* y)
{
assert(x);//判斷指標合法性
assert(y);
const double* x_ = (const double*)x;//將函式引數強轉成double*型別并賦值給x_
const double* y_ = (const double*)y;
if (*x_ > *y_) {
return 1;
}
else if (*x_< *y_) {
return -1;
}
else {
return 0;
}
}
void Print(double arr[],int num)
{
for (int i = 0; i < num; i++) {
printf("%.3f ", arr[i]);
}
printf("\n");
}
int main()
{
double arr[] = { 9.84,6.200,6.52,4.21,48.25,58.666,98593.55 };
int num = sizeof(arr) / sizeof(arr[0]);
Print(arr, num);
qsort(arr, num, sizeof(double), double_compare);
Print(arr, num);
system("pause");
return 0;
}
字串使用qsort排序
字串比較大小的規則是:從起始位置開始進行字符的ASCII值比較,遇到第一個不相同的字符,ASCII值大的字串大,
#include<stdio.h>
#include<Windows.h>
#include<assert.h>
#include<string.h>
int String_compare(const void* x, const void* y)
{
assert(x);//判斷指標合法性
assert(y);
//因為函式的引數是進行比較的變數的地址而此處要比較的\
兩個變數是char*型別,所以這里要用二級指標char**
const char ** x_ = (const char**)x;
const char ** y_ = (const char**)y;
//strcmp的引數是字串起始地址,所以此處要對*x_和*y_進行解參考
return strcmp(*x_, *y_);
}
int main()
{
//定義一個指標陣列,陣列元素指向要進行比較的字串
char *arr[] = {
"abcd1234",
"alkjgllkgj",
"sdagfsagf",
"agsafidfk",
"sagjsdakjd"
};
int num = sizeof(arr) / sizeof(arr[0]);
qsort(arr, num, sizeof(char*), String_compare);
for (int i = 0; i < num; i++) {
printf("%s\n", arr[i]);
}
system("pause");
return 0;
}
3.qsort函式模擬
用冒泡排序法模擬實作qsort函式
#include<stdio.h>
#include<Windows.h>
#include<assert.h>
#include<string.h>
int String_compare(const void* x, const void* y)
{
assert(x);//判斷指標合法性
assert(y);
//因為函式的引數是進行比較的變數的地址而此處要比較的\
兩個變數是char*型別,所以這里要用二級指標char**
const char** x_ = (const char**)x;
const char** y_ = (const char**)y;
//strcmp的引數是字串起始地址,所以此處要對*x_和*y_進行解參考
return strcmp(*x_, *y_);
}
void Swap(void* x, void* y,size_t size)
{
char* x_ = (char*)x;
char* y_ = (char*)y;
//逐位元位交換兩個變數,這種方式可以交換任意型別變數的值
for (size_t j=0; j < size; j++) {
*x_ ^= *y_;
*y_ ^= *x_;
*x_ ^= *y_;
x_++, y_++;
}
}
void MyQsort(void* base, size_t num, size_t sz, int(*compare)(const void* x, const void* y))
{
assert(base);
assert(compare);
for (size_t i = 0; i < num-1; i++) {
int flag = 1;
for (size_t j = 0; j < num - i - 1; j++) {
//因為要排序的資料型別是不確定的,所以用char*來指向
//通過起始地址+元素大小*所經歷元素個數的方式,可以確定資料的地址\
將資料地址傳遞給compare指向的函式,確定型別后可以比較兩個資料的大小
if (compare((char*)base + j * sz, (char*)base + (j + 1) * sz) > 0) {
Swap((char*)base + j * sz, (char*)base + (j + 1) * sz, sz);
flag = 0;
}
}
if (flag)
{
break;
}
}
}
int main()
{
//定義一個指標陣列,陣列元素指向要進行比較的字串
char* arr[] = {
"nbcd1234",
"jlkjgllkgj",
"xdagfsagf",
"ygsafidfk",
"xagjsdakjd"
};
int num = sizeof(arr) / sizeof(arr[0]);
MyQsort(arr, num, sizeof(char*), String_compare);//自定義函式MyQsort
for (int i = 0; i < num; i++) {
printf("%s\n", arr[i]);
}
system("pause");
return 0;
}
程式的內核是一個冒泡排序演算法,而由于資料型別不能確定,與普通冒泡排序略有區別區別,首先,無法直接比較兩個資料的大小,所以函式的形參中有個函式指標,在該函式中呼叫另一個函式,即回呼函式,用于比較某一確定的資料型別的值的大小;其次,確定資料在記憶體中的地址方式也不一樣,將起始地址強轉成char*型別,加上型別大小乘以跨度確定地址;最后,交換兩個變數的值時,逐位元位交換內容,
五、試題決議
(一)指標和陣列試題
第一組 整型陣列
ps:注釋中“下一個陣列的地址”這樣的描述不準確,只是為了便于理解,其實際指的是陣列最后一個元素下一個位置的地址,是一個指標陣列,其指向與已經定義的陣列型別相同,
//一維陣列
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));//整個陣列大小,16
printf("%d\n", sizeof(a + 0));//陣列名不是單獨出現,首元素地址,4
printf("%d\n", sizeof(*a));//首元素 4
printf("%d\n", sizeof(a + 1));//第二個元素地址,4
printf("%d\n", sizeof(a[1]));//第二個元素,4
printf("%d\n", sizeof(&a));//整個陣列的地址,4
printf("%d\n", sizeof(*&a));//整個陣列,16
printf("%d\n", sizeof(&a + 1));//下一個陣列的地址,4
printf("%d\n", sizeof(&a[0]));//第一個元素的地址,4
printf("%d\n", sizeof(&a[0] + 1));//第二個元素的地址,4
第二組 陣列保存的單個字符
先了解strlen函式

C 字串的長度等于字串開頭和終止空字符之間的字符數(不包括終止空字符本身),
//字符陣列
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
printf("%d\n", sizeof(arr));//整個陣列,6
printf("%d\n", sizeof(arr + 0));//第一個元素的地址,4
printf("%d\n", sizeof(*arr));//首元素,1
printf("%d\n", sizeof(arr[1]));//第二個元素,1
printf("%d\n", sizeof(&arr));//整個陣列的地址,4
printf("%d\n", sizeof(&arr + 1));//下一個陣列的地址,4
printf("%d\n", sizeof(&arr[0] + 1));//第二個元素的地址,4
printf("%d\n", strlen(arr));//首元素地址,沒有'\0',所以結果為隨機值
printf("%d\n", strlen(arr + 0));//首元素地址,隨機值
printf("%d\n", strlen(*arr));//首元素,報錯
printf("%d\n", strlen(arr[1]));//第一個元素,報錯
printf("%d\n", strlen(&arr));//整個陣列的地址,陣列指標型別,隨機值,有告警
printf("%d\n", strlen(&arr + 1));//下一個陣列的地址,陣列指標型別,隨機值,有告警
printf("%d\n", strlen(&arr[0] + 1));//第二個元素的地址,隨機值
第三組 陣列保存的字串
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));//整個陣列,7
printf("%d\n", sizeof(arr + 0));//字符指標,4
printf("%d\n", sizeof(*arr));//字符型,1
printf("%d\n", sizeof(arr[1]));//第二個元素,字符型,1
printf("%d\n", sizeof(&arr));//陣列指標,4
printf("%d\n", sizeof(&arr + 1));//陣列指標,4
printf("%d\n", sizeof(&arr[0] + 1));//字符指標,第二個元素的地址,4
printf("%d\n", strlen(arr));//首地址開始,6
printf("%d\n", strlen(arr + 0));//首地址開始,6
//printf("%d\n", strlen(*arr));//首元素,報錯
//printf("%d\n", strlen(arr[1]));//首元素,報錯
printf("%d\n", strlen(&arr));//整個陣列的地址開始,型別不匹配告警,6
printf("%d\n", strlen(&arr + 1));//下一個陣列的地址開始,型別不匹配告警,隨機值
printf("%d\n", strlen(&arr[0] + 1));//第二個元素的地址開始,5
第四組 char*指向的字串
char *p = "abcdef";
printf("%d\n", sizeof(p));//指標,4
printf("%d\n", sizeof(p + 1));//指標,4
printf("%d\n", sizeof(*p));//字符a,1
printf("%d\n", sizeof(p[0]));//下標參考,字符a,1
printf("%d\n", sizeof(&p));//二級指標,4
printf("%d\n", sizeof(&p + 1));//4
printf("%d\n", sizeof(&p[0] + 1));//字符b的地址,4
printf("%d\n", strlen(p));//首地址開始,6
printf("%d\n", strlen(p + 1));//第二個元素的地址開始,5
printf("%d\n", strlen(*p));//第一個元素,報錯
printf("%d\n", strlen(p[0]));//第一個元素,報錯
printf("%d\n", strlen(&p));//二級指標,隨機值
printf("%d\n", strlen(&p + 1));//二級指標,隨機值
printf("%d\n", strlen(&p[0] + 1));//第二個元素地址開始,5
▲第五組 二維陣列
//二維陣列
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));//整個陣列,48
printf("%d\n", sizeof(a[0][0]));//第一個元素,4
printf("%d\n", sizeof(a[0]));//第一個陣列的陣列名,單組在sizeof中,表示整個陣列,16
printf("%d\n", sizeof(a[0] + 1));//沒有單獨放在sizeof內,第一個一維陣列的第二的元素的地址,4
printf("%d\n", sizeof(*(a[0] + 1)));//第一個一維陣列的第二個元素,4
printf("%d\n", sizeof(a + 1));//a是首元素地址,即第一個一位陣列的地址,加一表示第二個一維陣列的地址,4
printf("%d\n", sizeof(*(a + 1)));//第二個一維陣列的地址解參考,即第二個一維陣列,16
printf("%d\n", sizeof(&a[0] + 1));//第二個一維陣列的地址,4
printf("%d\n", sizeof(*(&a[0] + 1)));//對第二個一維陣列的地址解參考,表示第二個一維陣列,16
printf("%d\n", sizeof(*a));//a是第一行地址,第一個一維陣列的地址解參考,表示第一個一維陣列,16
printf("%d\n", sizeof(a[3]));//sizeof不會訪問目標,只根據型別來計算大小,故無報錯,a[3]是一個包含四個整形的一維陣列,16
二維陣列的題要抓住幾點:
- 陣列名大部分情況都表示首元素地址,而對于二維陣列來說,首元素就是一個一維陣列,
- 陣列名只有單獨出現在sizeof內部和&符號后表示整個陣列,
- 二維陣列的每一個一維陣列名的表示方法
(二)筆試題
第一題
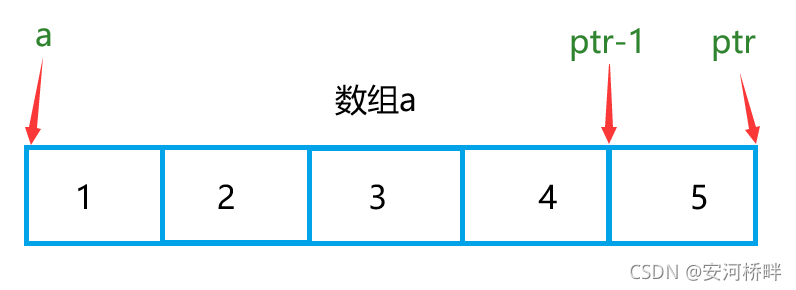
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
運行結果: 2,5
分析:&a表示整個陣列的地址,加一指向陣列后下一個位置,由于ptr型別是int*,減一實際減去所指向型別的大小,指向5的前面;a表示首元素地址,加一為第二個元素的地址,解參考后表示第二個元素,
如圖:
第二題
//由于還沒學習結構體,這里告知結構體的大小是20個位元組
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假設p 的值為0x100000, 如下表運算式的值分別為多少?
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
運行結果: 0x100014,0x100001,0x100004
分析: 結構體的大小為20個位元組,所以指標加一,加上的是20,轉換成16進制即為14;將p強制轉換成無符號長整型后,對其加一,實際值也加一;將p強轉成unsigned int *型別,加一,實際值加四,因為指標的大小為四位元組,
第三題
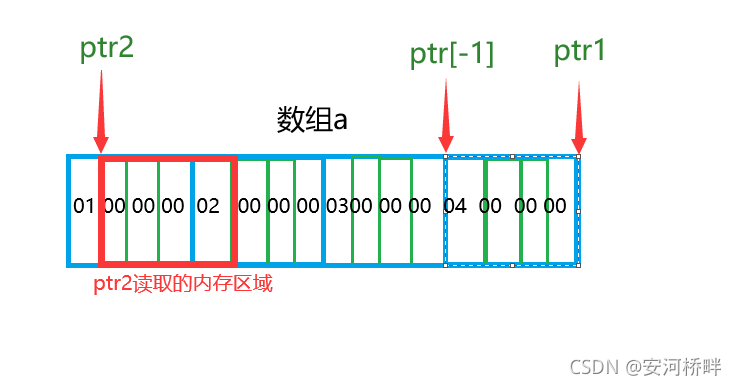
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}
運行結果: 4,2000000
分析: ‘%p’格式與’%x’格式都是按十六進制輸出,區別是 ‘%p’格式會輸出八位,不夠八位的補零,’%x’格式不會補0,
這里指標ptr指向的是陣列最后一個元素的下一個位置,因其被強轉成int*型別,ptr[-4]指向的是原來位置往前四個位元組的位置,即指向4的最前面;
a強制轉換為int型后值加1,再強為int *型別,指向的位置如下圖所示,資料在記憶體中的存盤遵從大小端原則,小端存盤轉低權值位在低地址處,讀取時同樣遵從小端的規律,高地址處的資料放在高權值位,所以讀取順序為02 00 00 00,最終結果為2000000,
第四題
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}
運行結果: 1
分析: 陣列在記憶體中的存盤如圖所示,圓括號中是逗號運算式,最終陣列元素的值是逗號右邊的值;a[0]是第一個一維陣列的陣列名,表示首元素地址,即a[0][0]的地址,賦值給p后,p指向首元素的位置,p[0]陣列下標參考,表示偏移量為0,仍然指向原來1的位置,
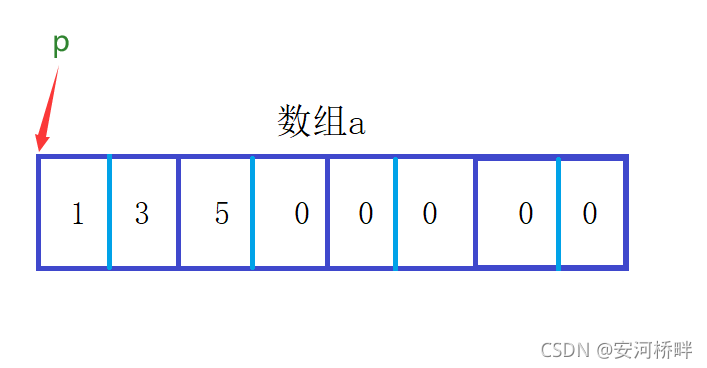
第五題
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
運行結果: FFFFFFFC,-4
分析: 記憶體布局如下圖所示,指標p跨度為4,最終與 &p[4][2] 與 &a[4][2]之間差4個位元組,結果為-4,以%p列印輸出結果則為FFFFFFFC,
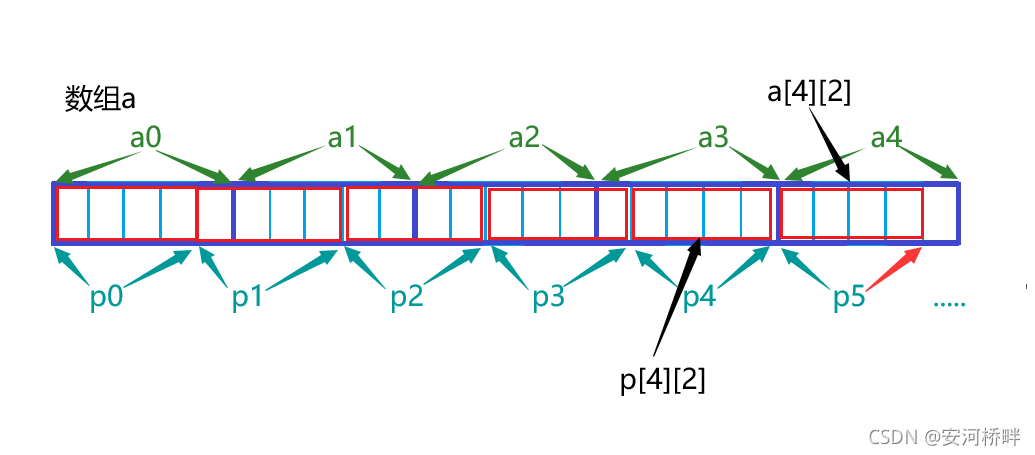
第六題
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
運行結果:10,5
分析:&aa+1指向二維陣列最后一個元素后面的位置;aa+1是指向第二個一維陣列的陣列指標,解參考后表示整個陣列,等價于aa[1],即第個二維陣列的陣列名,表示第二個二維陣列首元素的地址,即a[1][0]的地址,強轉后減一,指向a[0][4],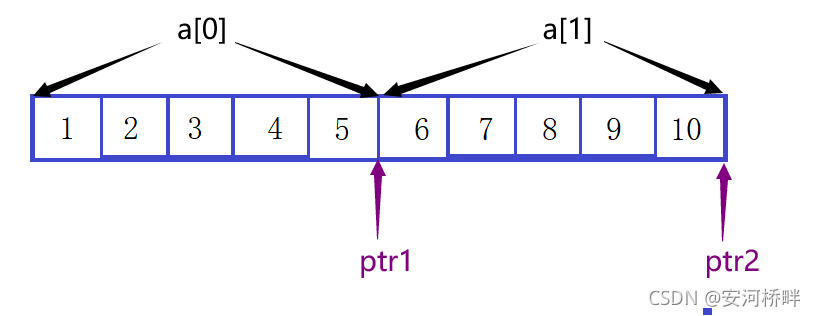
第七題
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
運行結果: at
分析: 字符指標陣列的寫法并不是把字串放保存在陣列里,字串是保存在記憶體中的靜態字符常量區,這里只是用指標指向每個字串第一個字符的地址,將這樣的指標保存在陣列中,與定義指標指向字串原理相同,如:
char *pc="hello world";
這里的pc指向字串的第一個字符’h’,并不是把字串保存在pc中,
本題的陣列a,是一個指標陣列,保存了3個指向字串的指標,如圖:
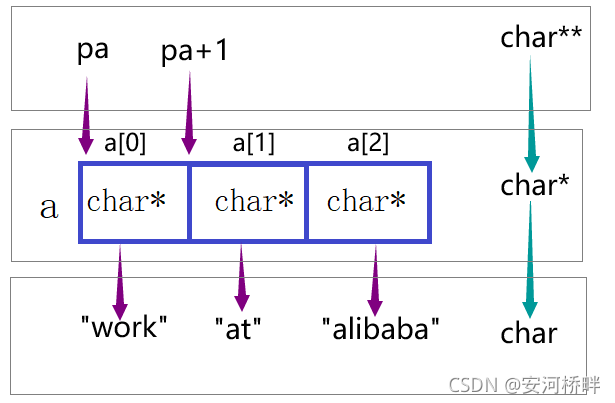
pa是一個二級指標,指向a[0]這個一級指標,對pa自增后,其指向下一個一級指標a[1],pa解參考得到一個字符指標,%s列印輸出,結果則為’at’,
第八題
int main()
{
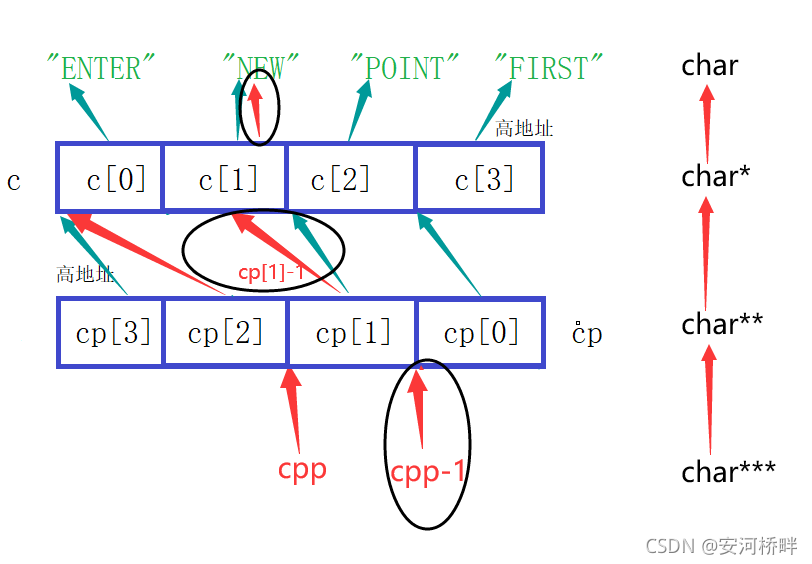
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
“ENTER” “NEW” “POINT” “FIRST”
運行結果:
POINT
ER
ST
EW
分析: 記憶體分布圖如下:
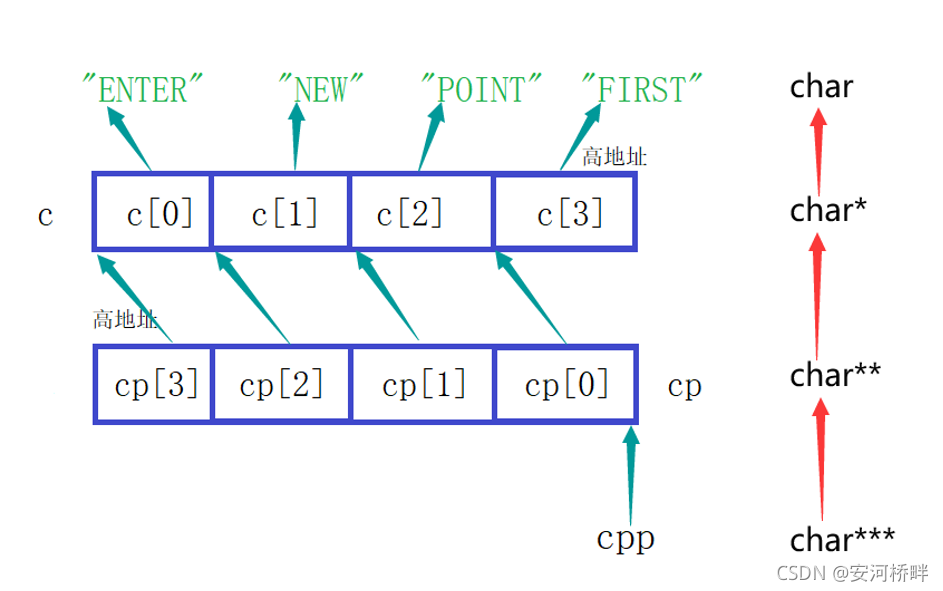
1.printf("%s\n", **++cpp);
++cpp對cpp進行自增,需要注意,cpp的指向會發生改變,且對后面都有影響,
所以結果為POINT,
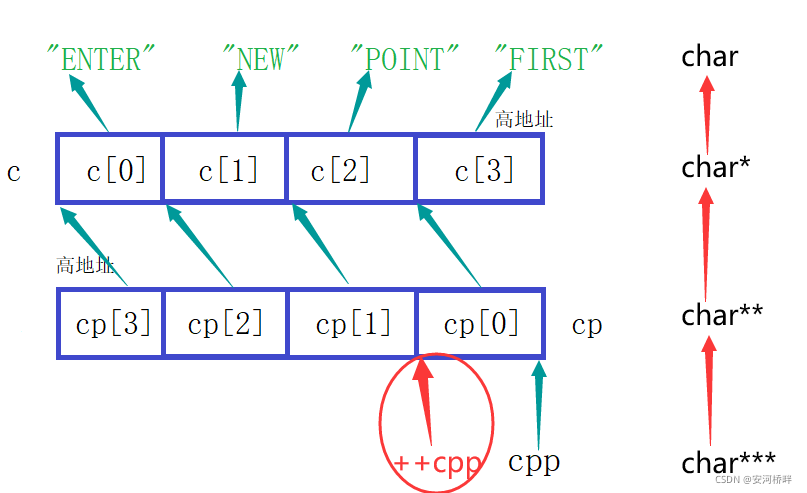
2.printf("%s\n", *--*++cpp+3);
需要注意此時的cpp要用第一次自增后的指向;此時的cpp指向cp[1],自增后則指向產品[2],對cp[2]自減,其指向由cp[1]變為c[0],解參考則得到c[0]原來指向字符第一個字符’E’,c[0]+3指向第二個字符’E’,但是從[0]的指向只是臨時改變,并沒有賦值保存,如圖:
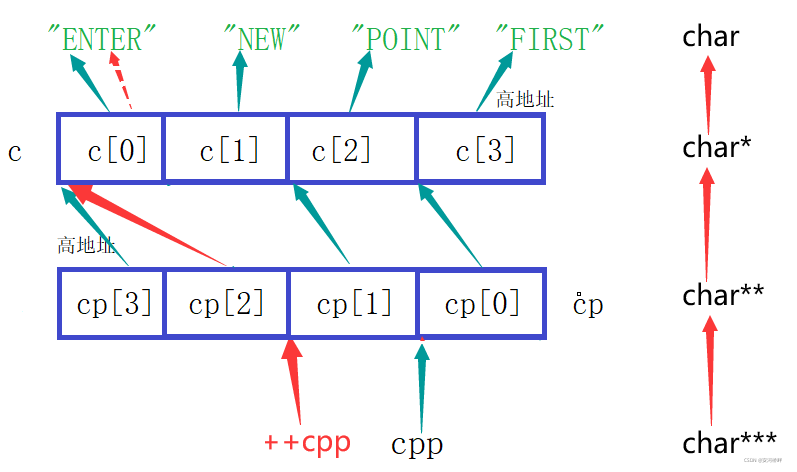
3.printf("%s\n", *cpp[-2]+3);
cpp[-2]為陣列下標參考,表示cp[0],其指向c[3],所以*cpp[-2]表示c[3],c[3]指向字符’F’,所以c[3]+3指向字符’S’,列印結果為’ST’,注意cpp[-2]與cpp-2的區別,cpp[-2]等價于*(cpp-2),
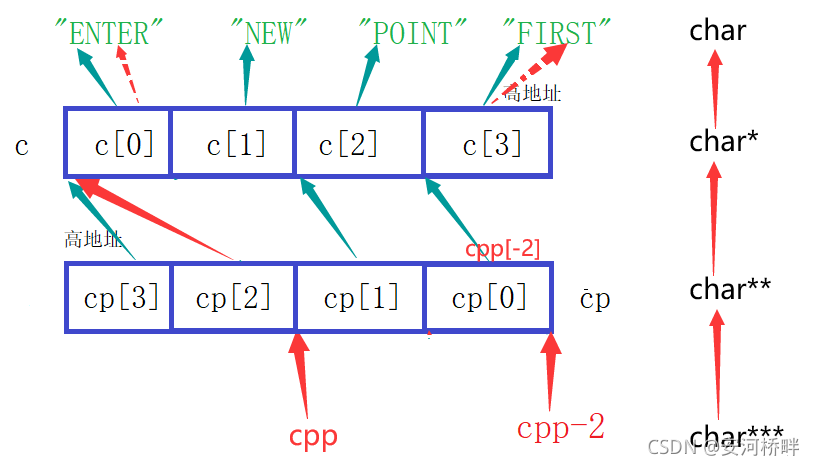
4.printf("%s\n", cpp[-1][-1]+1);
等價于*(*(cpp-1)-1),cpp[-1][-1]表示c[2],c[2]是一個字符指標,指向字符’N’,加1后指向字符’E’,如圖所示:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/341932.html
標籤:其他
上一篇:常考排序演算法之歸并排序