文章目錄
- 引入包
- 一、資料預處理
- 二、按月對資料分析
- 三、用戶個體消費資料分析
- 四、用戶消費行為分析
- 五、用戶的生命周期
引入包
本專案所用資料為【密碼:pfj6】:CDNOW_master.txt
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
import matplotlib.pyplot as plt
# CDNOW_master.txt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
一、資料預處理
- 本階段需求

- 讀取資料集
df = pd.read_csv('./CDNOW_master.txt')
df.head()
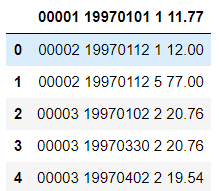
消除列的索引,使用指定索引
# "\s+"則表示匹配任意多個上面的字符 ?
df = pd.read_csv('./CDNOW_master.txt',header=None,sep='\s+',names=['user_id','order_dt','order_product','order_amount'])
df.head()
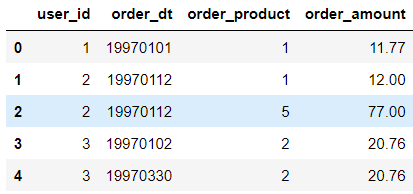
- 查看資料型別
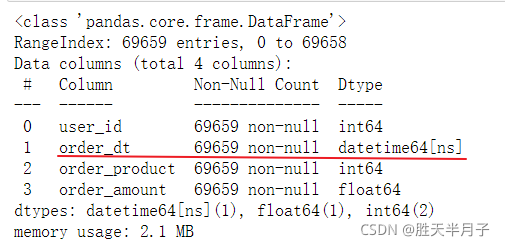
df.info()

- 將order_dt轉換成時間序列
df['order_dt'] = pd.to_datetime(df['order_dt'],format='%Y%m%d')
df.info()
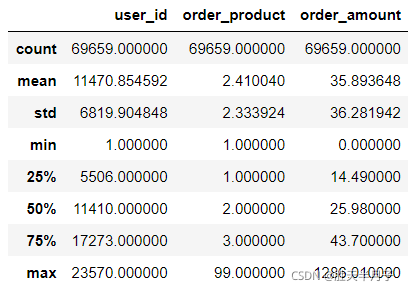
- 查看資料的統計描述
df.describe()
- 在源資料中添加一串列示月份:astype(datetime64[‘M’])
df['month'] = df['order_dt'].astype('datetime64[M]')
df.head()
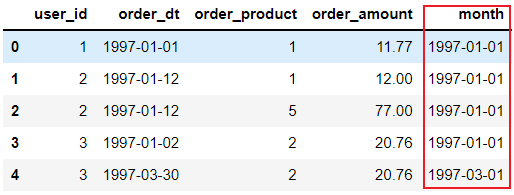
astype的用法:np.astype()
Python中與資料型別相關函式及屬性有如下三個:type/dtype/astype
- type() 回傳引數的資料型別
- dtype 回傳陣列中元素的資料型別
- astype() 對資料型別進行轉換
二、按月對資料分析

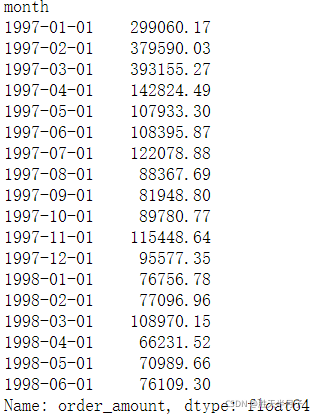
- 用戶每月花費的總金額
df.groupby(by='month')['order_amount'].sum()
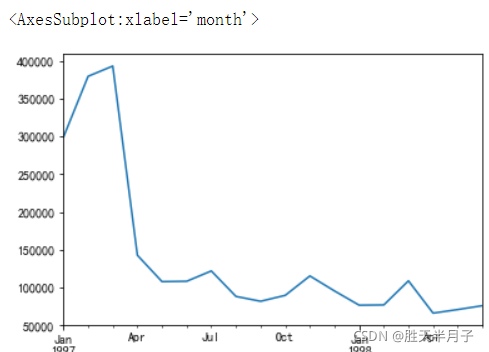
- 繪制曲線圖
df.groupby(by='month')['order_amount'].sum().plot()
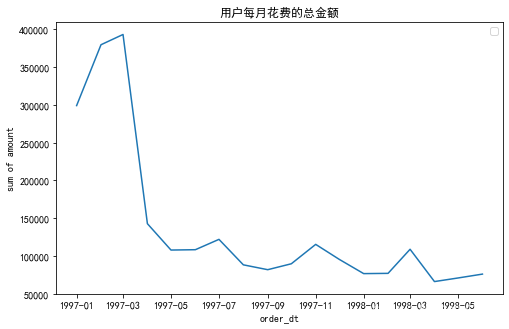
- 對上圖進行細化
plt.figure(figsize=(8,5))
plt.plot(df.groupby(by='month')['order_amount'].sum())
plt.xlabel('order_dt')
plt.ylabel('sum of amount')
plt.title('用戶每月花費的總金額')
plt.legend()
- 所有用戶每月的產品購買數量
df.groupby(by='month')['order_product'].sum()
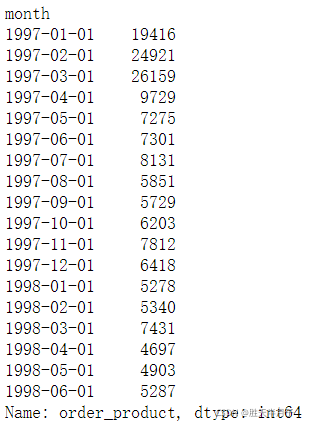
df.groupby(by='month')['order_product'].sum().plot()
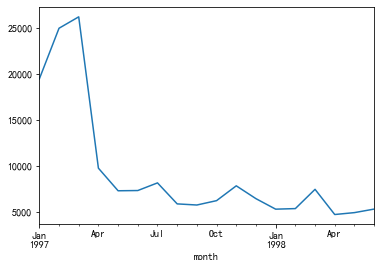
- 所有用戶每月消費的總次數
df.groupby(by='month')['user_id'].count()
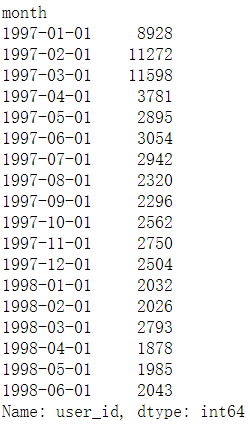
- 統計每月消費的人數 【有人會在同一天消費多次】
- unique():去重
- nunique():去重并統計個數
df.groupby(by='month')['user_id'].nunique()
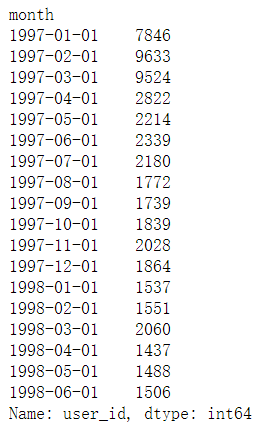
三、用戶個體消費資料分析

- 所有用戶消費總金額和消費總購買量的統計描述
df['order_product'].sum()
167881
df['order_amount'].sum()
2500315.6300000004
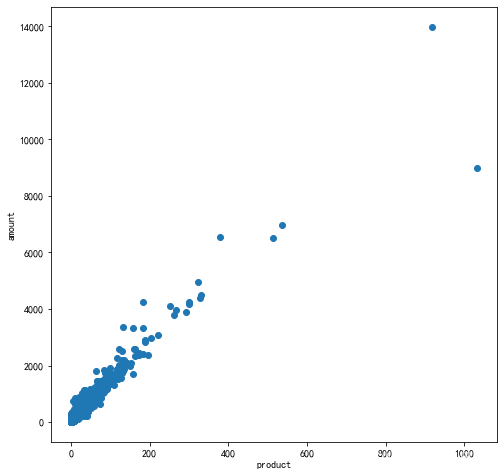
- 各個用戶消費金額和香消費產品數量的散點圖
user_amount = df.groupby(by='user_id')['order_amount'].sum()
user_product = df.groupby(by='user_id')['order_product'].sum()
plt.figure(figsize=(8,8))
plt.scatter(user_product,user_amount)
plt.xlabel('product')
plt.ylabel('amount')
- 各個用戶消費總金額的分布直方圖(amount在1000之內)
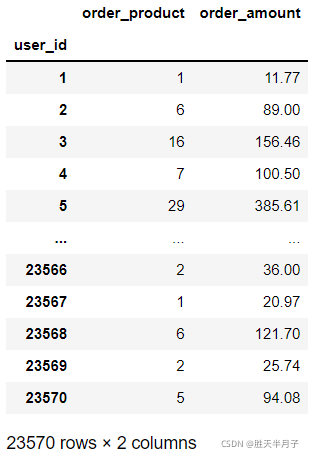
df.groupby(by='user_id').sum()
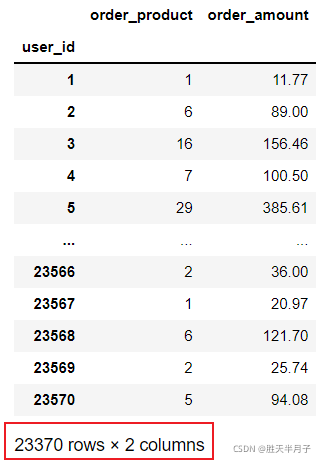
df.groupby(by='user_id').sum().query('order_amount <= 1000')
query的使用方法
- pandas 查詢函式query的用法說明
- Pandas query 的用法, df.query
- panda 中query 的用法
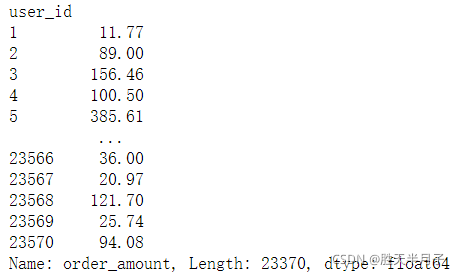
order_amount_1000 = df.groupby(by='user_id').sum().query('order_amount <= 1000')['order_amount']
order_amount_1000
- 繪出直方圖
plt.hist(order_amount_1000,bins=50)
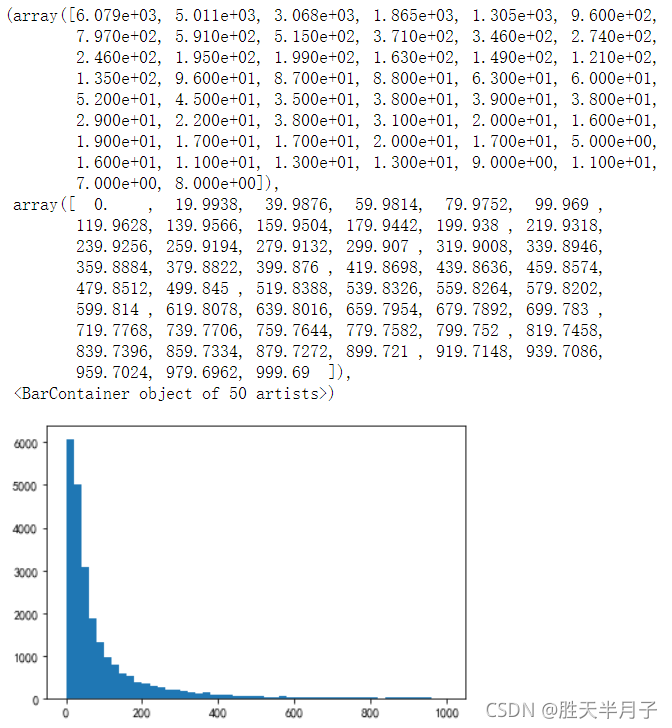
上述結果大部分的消費在(0. , 19.9938)之間,有6.079e+03個人
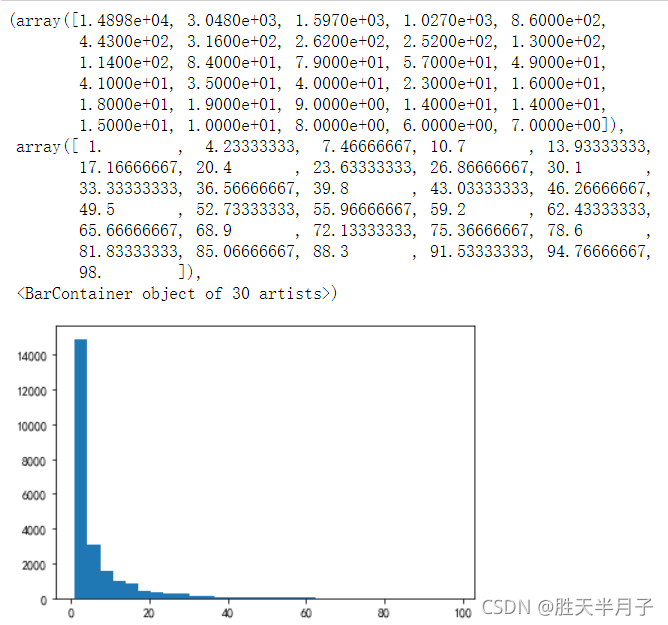
- 各個用戶消費的總數量的分布直方圖(消費商品的數量在100次之內的分布)
user_product_100 = df.groupby(by='user_id').sum().query('order_product <= 100')['order_product']
plt.hist(user_product_100,bins=30)
四、用戶消費行為分析

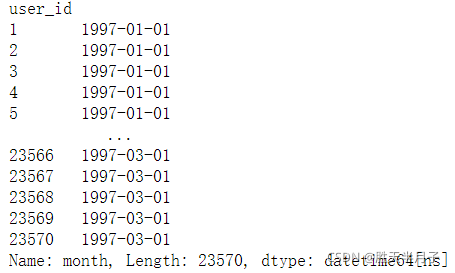
- 用戶第一次消費的月份分布,和人數統計
如何判定用戶第一次消費的月份?
- 用戶消費的最小值就是用戶首次消費的月份
# 月份分布
df.groupby(by='user_id')['month'].min()
人數統計
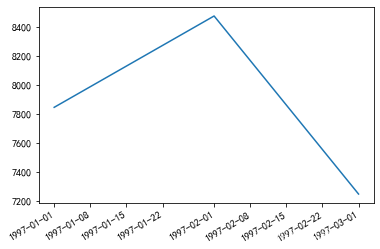
# value_counts() 用來統計Seris中不同人數出現的次數
df.groupby(by='user_id')['month'].min().value_counts()

df.groupby(by='user_id')['month'].min().value_counts().plot()
- 用戶最后一次消費的時間分布和認數統計
df.groupby(by='user_id')['month'].max().value_counts()
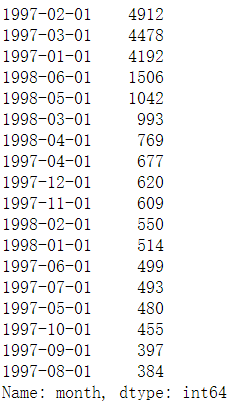
df.groupby(by='user_id')['month'].max().value_counts().plot()
- 新老客戶的占比
- 消費一次為新用戶
- 消費多次為老用戶
- 判定用戶消費的次數(1次還是多次)
- 求出用戶第一次和最后一次消費的時間,若時間相同,則表示用戶只消費了一次,否則表示消費多次
# agg用于將分組后的結果進行多種不同形式的聚合操作
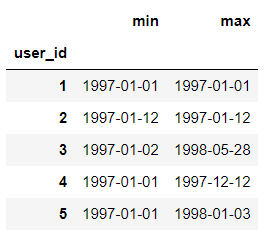
first_last_order_dt = df.groupby(by='user_id')['order_dt'].agg(['min','max'])
first_last_order_dt.head()
agg函式的使用:
- 【Python】Pandas中的寶藏函式-agg()
- Python - Pandas系列-最強的agg解釋!??
(first_last_order_dt['min'] == first_last_order_dt['max']).value_counts()
# True:只消費一次--新用戶 False:消費多次--老用戶
True 12054
False 11516
dtype: int64
- 求出每個用戶的總購買量和總消費金額and最后一次消費的時間的表格rfm
rfm = df.groupby(by='user_id').sum()
rfm.head()

# 最后消費一次的時間
user_recently_order_dt = df.groupby(by='user_id')['order_dt'].max()
rfm['R']=user_recently_order_dt
rfm.head()
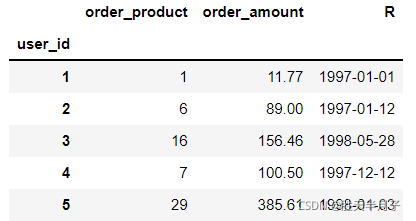
- R表示客戶最近一次交易的時間間隔
- /np.timedelta64(1,‘D’):去除days
- F表示客戶購買的商品數量 F越大,表示客戶交易越頻繁,反之表示客戶交易不夠活躍
- M表示客戶交易的金額 M越大,表示客戶價值越高,反之價值越低
- 將R,F, M,作用到rfm中
rfm.columns = ['F','M','R']
rfm
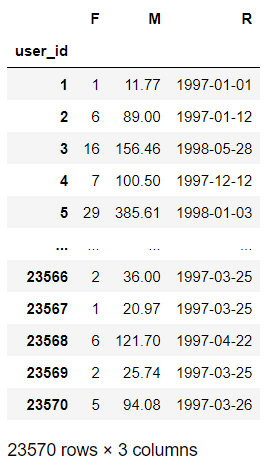
# R : 表示客戶最近一次交易的時間間隔
# 時間間隔 = 所有時間的最大值 - 客戶最后一次交易的最大值
rfm['R'] = df['order_dt'].max() - rfm['R']
rfm
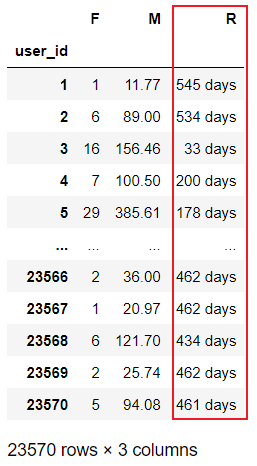
# / np.timedelta64(1,'D'):取出days
rfm['R'] = rfm['R'] / np.timedelta64(1,'D')
rfm.head()
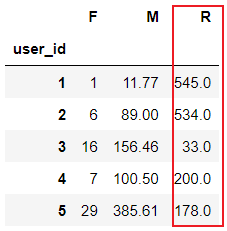
- 劃分客戶型別??
# rfm分層演算法
def rfm_func(x):
# 存盤的是三個字串形式的0或者1
# -6.122656 -94.310426 177.778362 ==》 '0' '0' '1'
level = x.map(lambda x:'1' if x >= 0 else '0')
label = level['R'] + level.F + level.M # '100'
d = {
'111':'重要價值客戶',
'011':'重要保持客戶',
'101':'重要挽留客戶',
'001':'重要發展客戶',
'110':'一般價值客戶',
'010':'一般保持客戶',
'100':'一般挽留客戶',
'000':'一般發展客戶',
}
result = d[label] # d['100']
# result ==》 '一般挽留客戶'
return result
# df.apply(func) :apply是DataFrame的運算工具 可以對df中的行或列進行某種func形式的運算
rfm['label'] = rfm.apply(lambda x:x-x.mean(),axis=0).apply(rfm_func,axis=1)
rfm.head()
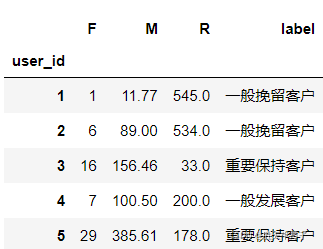
五、用戶的生命周期

- 統計每個用戶每個月的消費次數
# 每個用戶消費在所有時間內的消費次數
df.pivot_table(index='user_id',values='order_dt',aggfunc='count').head()

df.pivot_table(index='user_id',values='order_dt',aggfunc='count',columns='month')
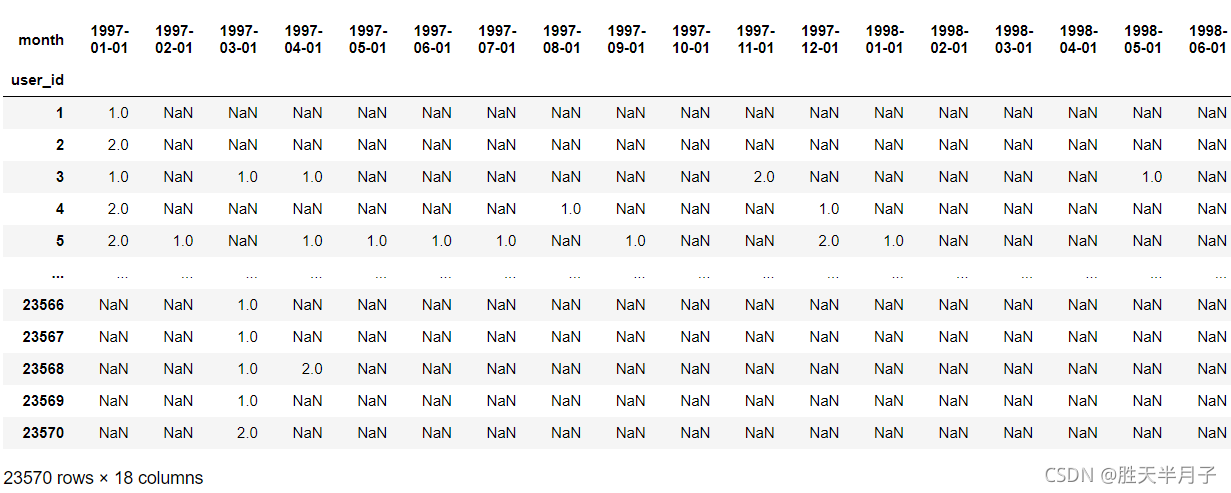
user_month_order_count = df.pivot_table(index='user_id',values='order_dt',aggfunc='count',columns='month',fill_value=0)
user_month_order_count.head()
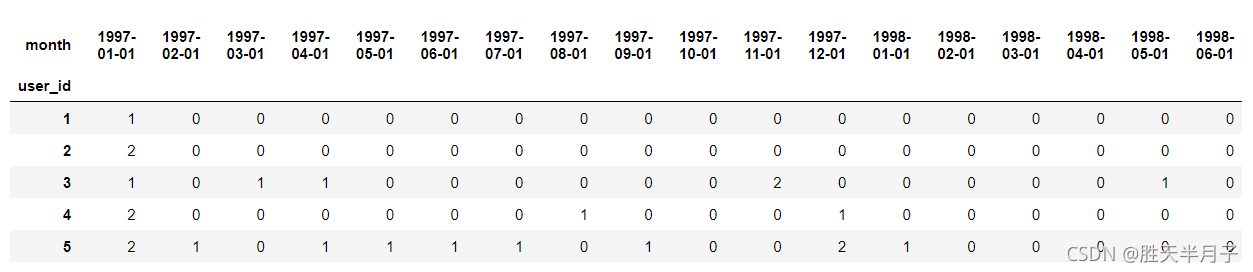
- 統計出每個用戶每個月是否消費,消費記錄為1 否則為0
- applymap()函式用于對DataFrame中的每一個元素執行相同的函式操作
- apply()函式主要用于對DataFrame中的某一column或row中的元素執行相同的函式操作,
df_purchase = user_month_order_count.applymap(lambda x:1 if x>=1 else 0)
df_purchase.head()

- 對每月得用戶活躍成分進行用戶劃分???

# 將df_purchase中的原始資料0和1修改為new,unactive ...,回傳的df叫做df_purchase_new
# 固定演算法
# data :每一行資料(某一個用戶在不同月份的消費記錄)
def active_status(data):
status = [] # 某個用戶每一個月的活躍度
for i in range(18):
# 若本月沒 有消費
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 若本月消費
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'active':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return status
# 每一行作為引數傳入active_status
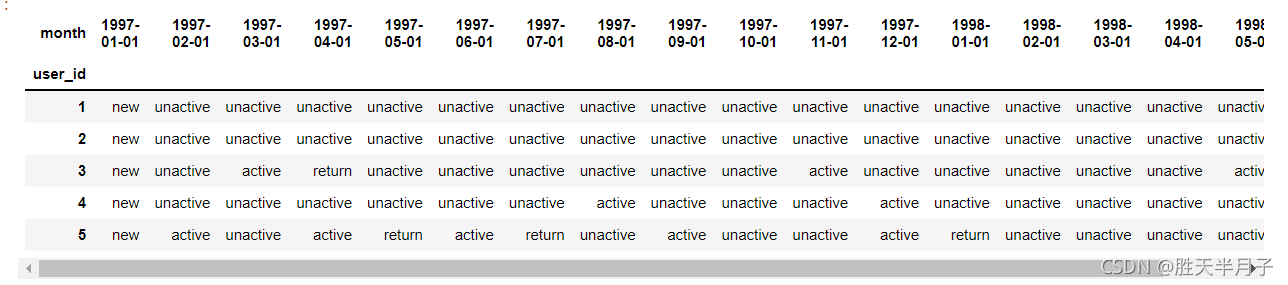
pivoted_status = df_purchase.apply(active_status,axis=1)
pivoted_status.head()

- 需要將上述回傳的Series封裝到DataFrame中??
pivoted_status.values

pivoted_status.values.tolist()

df_purchase_new = DataFrame(data=pivoted_status.values.tolist(),index=df_purchase.index,columns=df_purchase.columns)
df_purchase_new.head()
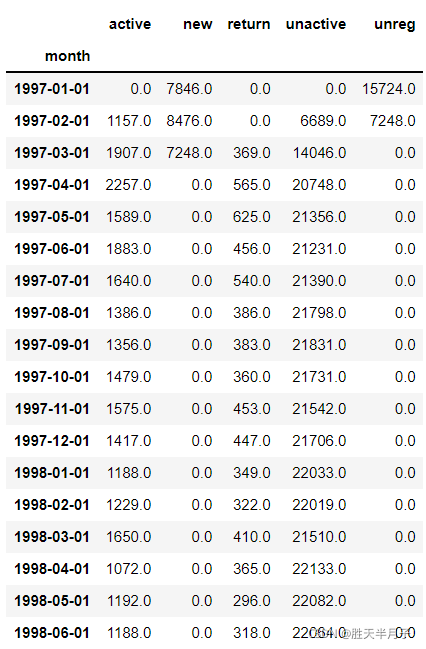
- 每月【不同活躍】用戶的計數?
purchase_status_ct = df_purchase_new_apply(lambda:pd.value_counts(x)).fillna(0)
轉置進行最終結果的查看
df_purchase_new.apply(lambda x:pd.value_counts(x))

- 將NaN用0填充
df_purchase_new.apply(lambda x:pd.value_counts(x)).fillna(0)

- 翻轉
df_purchase_new.apply(lambda x:pd.value_counts(x)).fillna(0).T
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/344311.html
標籤:其他