一網打盡MySQL的各種鎖
- 系列文章
- 一、如何選擇索引
- 影響優化器的幾大因素
- 掃描行數從何而來?
- 為什么優化器選擇了掃描行數多的索引?
- 二、索引選擇例外如何處理
- 三、總結
系列文章
二、一生摯友redo log、binlog《死磕MySQL系列 二》
三、MySQL強人“鎖”難《死磕MySQL系列 三》
四、S 鎖與 X 鎖的愛恨情仇《死磕MySQL系列 四》
五、如何選擇普通索引和唯一索引《死磕MySQL系列 五》
如果你對索引的知識點還不太清楚,可以直接通過傳送門查看咔咔總結的索引知識點,
揭開MySQL索引神秘面紗
索引是為加速查詢速度,創建的索引也符合所有規則,但MySQL就是不使用理想的索引,導致查詢速度變慢并產生大量慢查詢記錄,
今天就從這個問題來聊聊MySQL選擇索引時都做一些什么事情,
一、如何選擇索引
影響優化器的幾大因素
一條查詢SQL執行需要經過連接器、分析器、優化器、執行器,而選擇索引的重任就交給了優化器,
優化器在多個索引中選擇目的是為了找出執行代價最低的方案,
影響優化器選擇無非就這幾個因素,掃描行數、是否使用了臨時表、是否使用檔案排序,
臨時表、檔案排序這個兩個點會在后期文章給大家慢慢引出,今天只聊掃描行數,
掃描行數越少則訪問磁盤資料的次數就越少,消耗的CPU資源越少,
那么這個掃描行數是從哪里取的呢?
掃描行數從何而來?
創建索引一直提倡大家給區分度高的列建立索引,在一個索引上不同值的個數稱之為基數(cardinality),
使用show index from table_name可以查看每個索引的基數是多少,
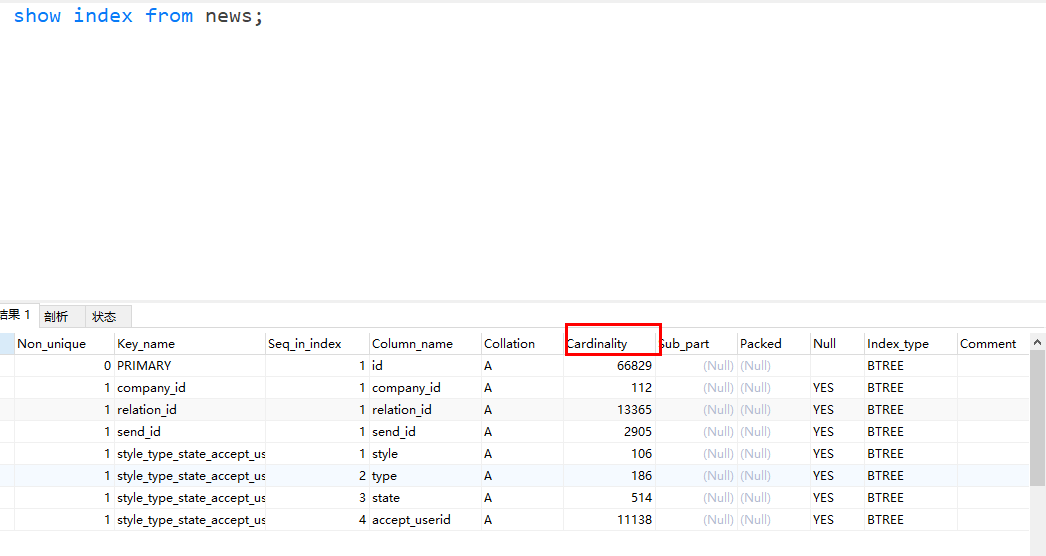
索引基數怎么計算
MySQL使用采樣統計的方法,會選出N個資料頁,每個資料頁大小16kb,接著統計選出來的資料頁上的不同值就會得到一個平均值,用平均值在乘以索引的頁面數得到的結果就是這個索引的基數,
表資料是持續增加或刪減的,統計的這個資料也不是時時變化的,當變更的資料超過1/M時會自動觸發重新計算,
這個M是根據引數innodb_stats_persistent的值選則的,設定為on值為10,設定為off值為16,
索引基數通過這種方式計算不是精準的但也差不了多少
為什么優化器選擇了掃描行數多的索引?
第一種情況
表增刪十分頻繁,導致掃描行數不準確
第二種情況
假設你主鍵索引掃描行數是10W行,而普通索引需要掃描5W行,這種情況就會遇到優化器選擇了掃描行數多的,
在索引那一期文章中知道主鍵索引是不需要回表的,找到值直接就回傳對應的資料了,
而普通索引是需要先拿到主鍵值,再根據主鍵值獲取對應的資料,這個程序優化器選擇索引時需要計算的一個成本,
如何解決這種情況
掃描行數不準確時可以執行analyze table table_name命令,重新統計索引資訊,達到預期優化器選擇的索引,
二、索引選擇例外如何處理
方案一
在MySQL中提供了force index來強制優化器使用這個索引,
使用方法:select * from table_name force index (idx_a) where a = 100;
但別誤解force index的使用方法,之前在代碼中看到這樣一個案例,給查詢列使用了函式操作導致使用不上索引,然后這哥們就直接使用force index,肯定不行的哈!
當優化器沒有正確選擇索引時是可以使用這種方案來解決,
缺點
使用force index的缺點相信大家也知道就是太死板,一旦索引名字改動就會失效,
方案二
刪掉誤選的索引,簡單粗暴,很多索引建立其實也是給優化器的一個誤導,直接刪掉即可,
方案三
修改SQL陳述句,主動引導MySQL使用期望的索引,一般情況這種做法使用的很少除非你對系統十分熟悉,否則盡量少操作,
三、總結
優化器選擇索引首先會根據掃描行數再由執行成本決定,
當索引統計資訊不準確時,使用analyze table 解決,
優化器選擇了錯誤的索引,只用force index來快速矯正,再通過優化SQL陳述句來引導優化器選擇正確的索引,最暴力的手法是直接洗掉誤選的索引,
堅持學習、堅持寫作、堅持分享是咔咔從業以來所秉持的信念,愿文章在偌大的互聯網上能給你帶來一點幫助,我是咔咔,下期見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/351039.html
標籤:其他
上一篇:Java-類和物件