java-Nginx與Tomcat安裝,配置及優化
1. java-Nginx安裝,配置及優化
1.1 Nginx的安裝
linux服務器三種安裝方式:
1.rpm(或pkg)安裝,類似以與Windows安裝程式,是預編譯好的程式,
- 使用的是通用引數編譯,配置引數部署最佳
- 可控制性不強,比如對程式特定組件的定制性安裝
- 通常安裝包間有復雜依賴關系,操作比較復雜
2.yum(或者apt-get)安裝,改良版的rpm,自動聯網下載安裝包,自動管理依賴關系
3.編譯安裝(方式在各類Linux發行版中差異不大)
- 可控制性強,config是可根據當前系統環境優化引數,可定制組件及安裝引數
- 易出錯,難度略高
1.2 nginx 安裝 啟動 關閉自動啟動
sbin目錄下:
啟動: ./nginx
關閉: ./nginx -s stop
多載組態檔: ./nginx -s reload
1.3 Nginx的配置
組態檔位置: conf/nginx.conf
全域塊
events塊
http塊
include: 引入組態檔
#頂層配置資訊管理服務器級別行為
#一般一個行程足夠了,你可以把連接數設得很大,如果有SSL、gzip這些比較消耗CPU的作業,而且是多核CPU的話,可以設為和CPU的數量一樣,或者要處理很多很多的小檔案,而且檔案總大小比記憶體大很多的時候,也可以把行程數增加,以充分利用IO帶寬(主要似乎是IO操作有block)
worker_processes 1;
#event指令與時間模型有關,配置處理連接有關資訊
events{
#單個作業行程可以允許同時建立外部連接的數量
worker_connections 1024;
}
#http指令處理http請求:接受請求
http{
#mime type 映射
include mime.types; #引入另外一個組態檔
default_type application/octet-stream; #在mime.type不存在的時候, 默認的檔案型別
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
#server 處理請求 表示一個虛擬主機,一臺服務器可配置多個虛擬主機
#第一個server 除了匹配本身 server_name 指定的域名外, 還匹配其他server都不匹配的域名
server{
#監聽埠
listen 80;
#識別的域名
server_name localhost;
#一個關鍵設定,與url引數亂碼問題有關
charset utf-8;
#access_log logs/host.access.log main;
#一個server下面可以有多個location,每個location有不同的處理行為,根據運算式匹配,請求交個哪個location,
#根據location里面的運算式,映射到具體的處理行為
#location
#location運算式:
#syntax: location [=|~|~*|^~|@] /uri/ {...}
#分為兩種匹配模式,普通字串匹配,正則匹配
#無開頭引導字符或以=開頭標識普通字串匹配
#以~或~*開頭標識正則匹配,~*標識不區分大小寫
#多個location時匹配規則
#總體是先普通后正則原則,只識別URI部分,例如請求為/test/1/abc.do?arg=xxx
#1. 先查找是否有=開頭的精確匹配,即location = /test/1/abc.do {...}
#2. 再查找普通匹配,以最大前綴為規則,如有以下兩個location
# location /test/ {...}
# location /test/1/ {...}
# 則匹配最后一項
#3. 匹配到一個普通格式后,搜索并未結束,而是暫存當前結果,并繼續再搜索正則模式
#4. 在所有正則模式location中找到第一個匹配項后,以此匹配項為最終結果
# 所以正則匹配項規則受定義前后順序影響,但普通匹配不會
#5. 如果未找到匹配項,則以3中快取的結果為最終結果
#6. 如果一個匹配都沒有,回傳404
#location =/ {...} 與 location / {...}的差別
#前一個是精確匹配,只回應/請求,所有/xxx類請求,不會以,前綴匹配形式匹配到它,
#后一個正相反,所有請求必然都是以/開頭,所以沒有其他匹配結果的時候一定會執行到它
#location ^~ / {...} ^~意思是非正則,標識匹配到此模式不再繼續正則搜索
#所有如果這樣配置,相當于關閉了正則匹配功能
#因為一個請求在普通匹配規則下沒得到其他普通匹配結果時,最終匹配到這里
#而這個 ^~指令又相當于不允許正則,相當于匹配到此為止
#精確匹配
location =/test {
...
}
#普通字符匹配
location /test {
...
}
location / {
root html; #指定根目錄 絕對路徑或者相對路徑
index index.html index.htm; #請求到達后沒有指定具體檔案,默認用index指定的順序,查找檔案
#deny all; 拒絕請求,回傳403
#allow all; 允許請求
}
location ^~ /test/ {
deny all;
}
#正則匹配
location ~ /test/.+\.jsp$ {
#代理
proxy_pass http://192.168.1.62:8080;
}
#正則匹配
location ~* \.jsp$ {
proxy_pass http://192.168.1.61:8080;
}
#定義各類錯誤頁
error_page 404 /404.html;
#redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x/html {
root html;
}
# @類似于變數定義
# 錯誤執行另外一個代理服務器的時候,location 定義一個變數名, 用@符號
# error_page 403 http://www.121212.com這種定義不允許,所以利用@實作
error_page 403 @page403;
location @page403 {
proxy_pass = http://www.121212.com;
}
}
}
mime.types
Nginx 會根據mime type定義的對應關系來告訴瀏覽器如何處理服務器傳給瀏覽器的這個檔案,是打開還是下載;如果Web程式沒設定,Nginx也沒對應檔案的擴展名,就用Nginx 里默認的 default_type定義的處理方式,
比如Nginx默認的配置中default_type application/octet-stream; 這個就是默認為下載,瀏覽器訪問到未定義的擴展名的時候,就默認為下載該檔案;如果將這個設定改成default_type text/html;那就是告訴瀏覽器默認的打開方式是把所有未設定的擴展名當HTML檔案打開,雖然可能這樣設定會很多打不開,
mime type 和檔案擴展名的對應關系一般放在 mime.types這個檔案里,然后用 include mime.types; 來加載
mime.types檔案里是用types指令來定義的,下面是一個完整的定義:
mime.types檔案
types {
text/html html htm shtml;
text/css css;
text/xml xml;
image/gif gif;
image/jpeg jpeg jpg;
#application/x-javascript js;
application/javascript js;
application/atom+xml atom;
application/rss+xml rss;
text/mathml mml;
text/plain txt;
text/vnd.sun.j2me.app-descriptor jad;
text/vnd.wap.wml wml;
text/x-component htc;
image/png png;
image/tiff tif tiff;
image/vnd.wap.wbmp wbmp;
image/x-icon ico;
image/x-jng jng;
image/x-ms-bmp bmp;
image/svg+xml svg;
application/java-archive jar war ear;
application/mac-binhex40 hqx;
application/msword doc;
application/pdf pdf;
application/postscript ps eps ai;
application/rtf rtf;
application/vnd.ms-excel xls;
application/vnd.ms-powerpoint ppt;
application/vnd.wap.wmlc wmlc;
application/vnd.wap.xhtml+xml xhtml;
application/vnd.google-earth.kml+xml kml;
application/vnd.google-earth.kmz kmz;
application/x-7z-compressed 7z;
application/x-cocoa cco;
application/x-java-archive-diff jardiff;
application/x-java-jnlp-file jnlp;
application/x-makeself run;
application/x-perl pl pm;
application/x-pilot prc pdb;
application/x-rar-compressed rar;
application/x-redhat-package-manager rpm;
application/x-sea sea;
application/x-shockwave-flash swf;
application/x-stuffit sit;
application/x-tcl tcl tk;
application/x-x509-ca-cert der pem crt;
application/x-xpinstall xpi;
application/zip zip;
application/octet-stream bin exe dll;
application/octet-stream deb;
application/octet-stream dmg;
application/octet-stream eot;
application/octet-stream iso img;
application/octet-stream msi msp msm;
audio/midi mid midi kar;
audio/mpeg mp3;
audio/x-realaudio ra;
video/3gpp 3gpp 3gp;
video/mpeg mpeg mpg;
video/quicktime mov;
video/x-flv flv;
video/x-mng mng;
video/x-ms-asf asx asf;
video/x-ms-wmv wmv;
video/x-msvideo avi;
}
一般在Nginx的組態檔nginx.conf里面的http{}欄位中配置即可,注意mime.types是在你的nginx的安裝目錄下,如果目錄不是下面的,那你要自己手工修改:
參考博客: https://blog.csdn.net/qq_37788558/article/details/78621592
location
url匹配規則
location [=|~|~*|^~|@] /uri/ {
...
}
- = : 表示精確匹配后面的url
- ~ : 表示正則匹配,但是區分大小寫
- ~* : 正則匹配,不區分大小寫
- ^~ : 表示普通字符匹配,如果該選項匹配,只匹配該選項,不匹配別的選項,一般用來匹配目錄
- @ : “@” 定義一個命名的 location,使用在內部定向時,例如 error_page
上述匹配規則的優先匹配順序:
- = 前綴的指令嚴格匹配這個查詢,如果找到,停止搜索;
- 所有剩下的常規字串,最長的匹配,如果這個匹配使用 ^~ 前綴,搜索停止;
- 正則運算式,在組態檔中定義的順序;
- 如果第 3 條規則產生匹配的話,結果被使用,否則,使用第 2 條規則的結果,
location運算式:
syntax: location [=|~|~*|^~|@] /uri/ {...}
分為兩種匹配模式,普通字串匹配,正則匹配
無開頭引導字符或以=開頭標識普通字串匹配
以~或~*開頭標識正則匹配,~*標識不區分大小寫
多個location時匹配規則
總體是先普通后正則原則,只識別URI部分,例如請求為/test/1/abc.do?arg=xxx
- 先查找是否有=開頭的精確匹配,即location = /test/1/abc.do {…}
- 再查找普通匹配,以最大前綴為規則,如有以下兩個location
location /test/ {…}
location /test/1/ {…}
則匹配最后一項- 匹配到一個普通格式后,搜索并未結束,而是暫存當前結果,并繼續再搜索正則模式
- 在所有正則模式location中找到第一個匹配項后,以此匹配項為最終結果
所以正則匹配項規則受定義前后順序影響,但普通匹配不會- 如果未找到匹配項,則以3中快取的結果為最終結果
- 如果一個匹配都沒有,回傳404
location =/ {…} 與 location / {…}的差別
前一個是精確匹配,只回應/請求,所有/xxx類請求,不會以,前綴匹配形式匹配到它,
后一個正相反,所有請求必然都是以/開頭,所以沒有其他匹配結果的時候一定會執行到它
location ^~ / {...} ^~意思是非正則,標識匹配到此模式不再繼續正則搜索
所有如果這樣配置,相當于關閉了正則匹配功能
因為一個請求在普通匹配規則下沒得到其他普通匹配結果時,最終匹配到這里
而這個 ^~指令又相當于不允許正則,相當于匹配到此為止
#精確匹配
location =/test {...}
#普通字符匹配
location /test {...}
location / {
root html; #指定根目錄 絕對路徑或者相對路徑
index index.html index.htm; #請求到達后沒有指定具體檔案,默認用index指定的順序,查找檔案
#deny all; 拒絕請求,回傳403
#allow all; 允許請求
}
location ^~ /test/ {
deny all;
}
#正則匹配
location ~ /test/.+\.jsp$ {
#代理
proxy_pass http://192.168.1.62:8080;
}
#正則匹配
location ~* \.jsp$ {
proxy_pass http://192.168.1.61:8080;
}
#定義各類錯誤頁
error_page 404 /404.html;
#redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x/html {
root html;
}
# @類似于變數定義
# 錯誤執行另外一個代理服務器的時候,location 定義一個變數名, 用@符號
# error_page 403 http://www.121212.com這種定義不允許,所以利用@實作
error_page 403 @page403;
location @page403 {
proxy_pass = http://www.121212.com;
}
@ 類似于變數定義
# @類似于變數定義
# 錯誤執行另外一個代理服務器的時候,location 定義一個變數名, 用@符號
# error_page 403 http://www.121212.com這種定義不允許,所以利用@實作
error_page 403 @page403;
location @page403 {
proxy_pass = http://www.121212.com;
}
1.4 Nginx的優化
nginx.conf組態檔
全域塊
nginx不同于apache服務器,當apache進行了大量優化設定后會有魔術般的明顯提升性能效果,nginx在安裝完成后,大部分引數都是最優化了,我們需要管理的東西并不多
阻塞和非阻塞網路模型:
同步阻塞模型,一請求一進(線)程,當進(線)程增加到一定程度后,更多的CPU時間浪費到切換CPU,性能急劇下降,所以負載率并不高
Nginx基于事件的非阻塞多路復用(epoll或kquene)模型,一個行程在段時間內可以回應大量的請求
案例:
#user nobody;
#作業行程數量:接受和處理用戶請求
#建議值 <= CPU核心數量,一般高于cpu數量不會帶來好處,也許還有行程切換開銷的負面影響
worker_processes 4;
#將work process 系結到特定的CPU上,避免行程在cpu間切換的開銷
#多少個cpu,每組數字就有多少個數字 0/1
worker_cpu_affinity 0001 0010 0100 1000;
#8核4行程時的設定方法 worker_cpu_affinity 00000001 00000010 00000100 10000000
# 每個行程最大可打開檔案描述符數量(linux上檔案描述符比較廣泛,網路埠,設備,磁盤檔案都是)
# 檔案描述符用完了,新的連接會拒絕,產生502類錯誤
# linux 最大可打開檔案數可通過ulimit -n FILECNT或 /etc/security/limits.conf配置
# 理論值: 系統最大數量 / 行程數,但行程間作業量并不是平均分配的,所以可以設定的大一些
#越大越好
worker_rlimit_nofile 655350;
events{
...
}
worker_processes
作業行程數量:接受和處理用戶請求
#作業行程數量:接受和處理用戶請求
#建議值 <= CPU核心數量,一般高于cpu數量不會帶來好處,也許還有行程切換開銷的負面影響
worker_processes 4;
worker_cpu_affinity
將work process 系結到特定的CPU上
#將work process 系結到特定的CPU上,避免行程在cpu間切換的開銷
#多少個cpu,每組數字就有多少個數字 0/1
worker_cpu_affinity 0001 0010 0100 1000;
#8核4行程時的設定方法 worker_cpu_affinity 00000001 00000010 00000100 10000000
worker_rlimit_nofile
每個行程最大可打開檔案描述符數量
# 每個行程最大可打開檔案描述符數量(linux上檔案描述符比較廣泛,網路埠,設備,磁盤檔案都是)
# 檔案描述符用完了,新的連接會拒絕,產生502類錯誤
# linux 最大可打開檔案數可通過ulimit -n FILECNT或 /etc/security/limits.conf配置
# 理論值: 系統最大數量 / 行程數,但行程間作業量并不是平均分配的,所以可以設定的大一些
#越大越好
worker_rlimit_nofile 655350;
events塊
....
events {
#并發回應能力的關鍵配置值
#每個行程允許的最大同時連接數,worker_connections * worker_processes = maxConnection;
#要注意maxConnection不等于可回應的用戶數量,
#因為一般一個瀏覽器會同時開兩條連接,如果反向代理,nginx到后端服務器的連接也要占用連接數
#所以,做靜態服務器時,一般 maxClient = worker_connections * worker_processes /2
#做反向代理服務器時,maxClient = worker_connections * worker_processes /4
#這個值理論上越大越好,但最多可承受多少請求與配置和網路相關,也可最大可打開檔案,最大可用sockets數量
worker_connections 200000;
#指明使用 epoll 或 kqueue (*BSD)
use epoll;
#備注:要達到超高負載下最好的網路回應能力,還有必要優化與網路相關的linux 引數
}
....
worker_connections
并發回應能力的關鍵配置值,每個行程允許的最大同時連接數
#并發回應能力的關鍵配置值
#每個行程允許的最大同時連接數,worker_connections * worker_processes = maxConnection;
#要注意maxConnection不等于可回應的用戶數量,
#因為一般一個瀏覽器會同時開兩條連接,如果反向代理,nginx到后端服務器的連接也要占用連接數
#所以,做靜態服務器時,一般 maxClient = worker_connections * worker_processes /2
#做反向代理服務器時,maxClient = worker_connections * worker_processes /4
#這個值理論上越大越好,但最多可承受多少請求與配置和網路相關,也可最大可打開檔案,最大可用sockets數量
worker_connections 200000;
maxClient:最大客戶可用連接數
maxClient = worker_connections * worker_processes /2
做反向代理服務器時,maxClient = worker_connections * worker_processes /4
use
指定事件處理的時候,指定網路模型
基本不需要設定,nginx自動識別,
windows無法使用多路復用模型,這也是為什么nginx在windows上,性能不夠好的原因
#指明使用 epoll 或 kqueue (*BSD)
use epoll;
http塊
....
events{
...
}
https {
include mime.types;
dafault_type application/octet-stream;
#訪問日式是否記錄
#關閉此項可減少IO開銷,但也無法記錄訪問資訊,不利于業務分析,一般運維情況不建議使用
access_log off;
#錯誤日志
#crit:只記錄更為嚴重的錯誤日志,可減少IO壓力,或者關閉
error_log logs/error.log crit;
#access_log logs/access.log main;
#啟用內核復制模式,應該保持開啟達到最快IO效率,從磁盤級IO復制到網路級IO,不經過用戶級,減少了幾次復制程序【零拷貝技術】
sendfile on;
#簡單說,啟動如下兩項配置,會在資料包達到一定大小后再發送資料
#這樣會較少網路通信次數,降低阻塞概率,但也會影響回應及時性
#比較合適于檔案下載這類的大資料包通信場景
#tcp_nohush on;
#tcp_nodelay on|off on禁用Nagle演算法
#HTTP1.1支持持久連接alive
#連接存活時間: 降低每個連接的alive時間,可在一定程度上提高回應連接數量,所以一般可適當降低此值
keepalive_timeout 30s;
#啟動內容壓縮,有效降低網路流量,生產環境打開
gzip on;
#內容壓縮最小長度:過短的就不要壓縮,因為 過短的內容壓縮效果不佳,壓縮程序還會浪費系統資源
gzip_min_length 1000;
#可選值1~9,壓縮級別越高,壓縮率越高,但對系統性能要求越高
gzip_comp_level 4;
#壓縮的內容類別
gzip_types text/plain text/css application/json application/x-javascript text/xml ...;
#靜態檔案快取
#最大快取數量,檔案未使用存活期
#open_file_cache 打開檔案,max:快取檔案最大個數,
#"inactive":檔案存活期,"open_file_cache_min_uses"快取檔案在20s內使用至少2次,那么快取檔案不會被替換,是一個命中率有效的檔案
#"open_file_cache_valid":表示多久驗證快取,會釋放使用次數少的檔案
open_file_cache max=655350 inactive=20s;
#驗證快取有效期時間間隔
open_file_cache_valid 30s;
#有效期內檔案最少使用次數
open_file_cache_min_uses 2;
server {
...
}
}
日志
#訪問日式是否記錄
#關閉此項可減少IO開銷,但也無法記錄訪問資訊,不利于業務分析,一般運維情況不建議使用
access_log off;
#錯誤日志
#crit:只記錄更為嚴重的錯誤日志,可減少IO壓力,或者關閉
error_log logs/error.log crit;
#access_log logs/access.log main;
內核復制
#啟用內核復制模式,應該保持開啟達到最快IO效率,從磁盤級IO復制到網路級IO,不經過用戶級,減少了幾次復制程序【零拷貝技術】
sendfile on;
壓縮
#啟動內容壓縮,有效降低網路流量,生產環境打開
gzip on;
#內容壓縮最小長度:果斷的就不要壓縮,因為 過短的內容壓縮效果不佳,壓縮程序還會浪費系統資源
gzip_min_length 1000;
#可選值1~9,壓縮級別越高,壓縮率越高,但對系統性能要求越高
gzip_comp_level 4;
#壓縮的內容類別
gzip_types text/plain text/css application/json application/x-javascript text/xml;
靜態檔案快取
#靜態檔案快取
#最大快取數量,檔案未使用存活期
#open_file_cache 打開檔案,max:快取檔案最大個數,
#"inactive":檔案存活期,"open_file_cache_min_uses"快取檔案在20s內使用至少2次,那么快取檔案不會被替換,是一個命中率有效的檔案
#"open_file_cache_valid":表示多久驗證快取,回釋放使用次數少的檔案
open_file_cache max=655350 inactive=20s;
#驗證快取有效期時間間隔
open_file_cache_valid 30s;
#有效期內檔案最少使用次數
open_file_cache_min_uses 2;
2. Tomcat安裝,配置及優化
2.1 安裝JDK
下載 jdk1.8.0_51.tar.gz 解壓…在下面添加配置
/etc/profile.d/ 系統啟動的時候,會執行這里面的 .sh檔案
#/etc/profile.d/java.sh
JAVA_HOME=/opt/jdk1.8.0_51
#參考原PATH方式::$PATH
PATH=$JAVA_HOME/bin:$PATH
#匯出路徑:
export JAVA_HOME PATH
設定立即生效: source /etc/profile
2.2 Tomcat安裝
日志: /logs/catalina.out
啟動: /bin/start.sh
關閉: /bin/shutdown.sh
開機啟動:/etc/rc.d/rc.local 檔案 :用來設定開機自動運行
touch /var/lock/subsys/local
/opt/nginx/sbin/nginx
export JAVA_HOME=/opt/jdk1.8.0_51
$JAVA_HOME/bin/startup.sh
rc.local 比 profile.d 檔案夾里面的控制腳本啟動的更早,所以上面需要重新匯出一遍JAVA_HOME命令
2.3 Tomcat的優化配置
記憶體使用配置
/bin/catalina.sh
......
#Windows下配置方法
#set JAVA_OPTS=%JAVA_OPTS% -server -Xms2048m -Xmx2048m -XX:PermSize=256m -XX:MaxPermSize=512m -Djava.awt.headless=true
#通過記憶體設定充分利用服務器記憶體
#-server模式啟動應用慢,但可以極大程度提高運行性能
#java 8開始,PermSize 被 MetaspaceSize 代替,MetaspaceSize共享heap,不會再有java.lang.outofMemoryError:PermGen space,可以不設定PermSize
#headless=true 適用于linux系統,于圖形操作有關,如生成驗證碼,含義是當前適用的是無顯示幕的服務器,應用中如果獲取系統顯示有關引數會拋例外
#可通過 jmap -heap process_id查看設定是否成功
JAVA_OPTS=$JAVA_OPTS -server -Xms2048m -Xmx2048m -XX:PermSize=256m -XX:MaxPermSize=512m -Djava.awt.headless=true
......
最大連接數配置
server.xml
<!-- 埠連接 protocol : bio nio apr 三種網路模型-->
<!-- protocol 啟用nio模式,(tomcat8默認使用的是nio)(apr模式利用系統異步io) -->
<!-- minProcessors 最小空閑連接執行緒數 -->
<!-- maxProcessors 最大連接執行緒數 -->
<!-- acceptCount 允許的最大連接數,應大于等于 maxProcessors -->
<!-- enableLookups 如果為true,request.getRemoteHost 會執行DNS 查找,反向決議ip 對應域名或主機名 -->
<Connector port="8080" protocol="org.apache.coyote.http11.Http11NioProtocol"
connectionTimetoue="20000"
redirectPort="8443"
maxThreads="500" #最大連接執行緒數
minSpareThreads="100" #最小空閑執行緒
maxSpareThreads="200" #最大空閑執行緒
acceptCount="200" #所有執行緒啟動后,還允許接受的連接數量,也就是等待的執行緒數 ,最大可接受的任務:maxThreads+acceptCount
enableLookups="false" #是否允許DNS反查
/>
3. Nginx+Tomcat負載均衡詳細配置
3.1 負載均衡配置的實作
正向代理和反向代理
**正向代理:如果把局域網外的 Internet 想象成一個巨大的資源庫,則局域網中的客戶端要訪問 Internet,則需要通過代理服務器來訪問,這種代理服務就稱為正向代理,**對于反向代理,客戶端對代理是無感知的,因為客戶端不需要任何配置就可以訪問,我們只需要將請求發送到反向代理服務器,由反向代理服務器去選擇目標服務器獲取資料后,在回傳給客戶端,此時反向代理服務器和目標服務器對外就是一個服務器,暴露的是代理服務器地址,隱藏了真實服務器 IP 地址,
代理一般分為正向代理和反向代理,
正向代理是一個位于客戶端和原始服務器之間的服務器,為了從原始服務器取得內容,客戶端向代理發送一個請求并指定目標(原始服務器),然后代理向原始服務器轉交請求并將獲得的內容回傳給客戶端,
反向代理實際運行方式是代理服務器接受網路上的連接請求,它將請求轉發給內部網路上的服務器,并將從服務器上得到的結果回傳給網路上請求連接的客戶端,此時代理服務器對外就表現為一個服務器,
可以這么認為,對于正向代理,代理服務器和客戶端處于同一個局域網內;而反向代理,代理服務器和源站則處于同一個局域網內,
參考博客:https://blog.csdn.net/u010039418/article/details/80011127
https://www.cnblogs.com/xudong-bupt/p/8661523.html
nginx 充當代理服務器: 瀏覽器->Nginx->Tomcat,原理如下:
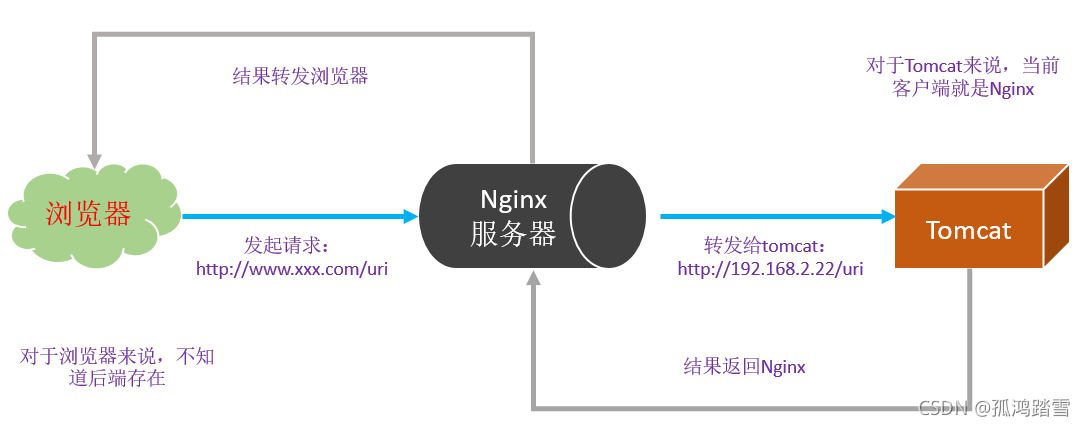
192.168.1.61服務器請求轉到192.168.1.62中的tomcat
192.168.1.61中nginx配置如下:
nginx.conf檔案里面設定代理:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
location / {
#root html;
index index.html index.htm;
#代理配置
proxy_pass http://192.168.1.62:8080;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
修改完成后,組態檔生效:sbin/nginx -s reload
負載均衡
示意圖如下:
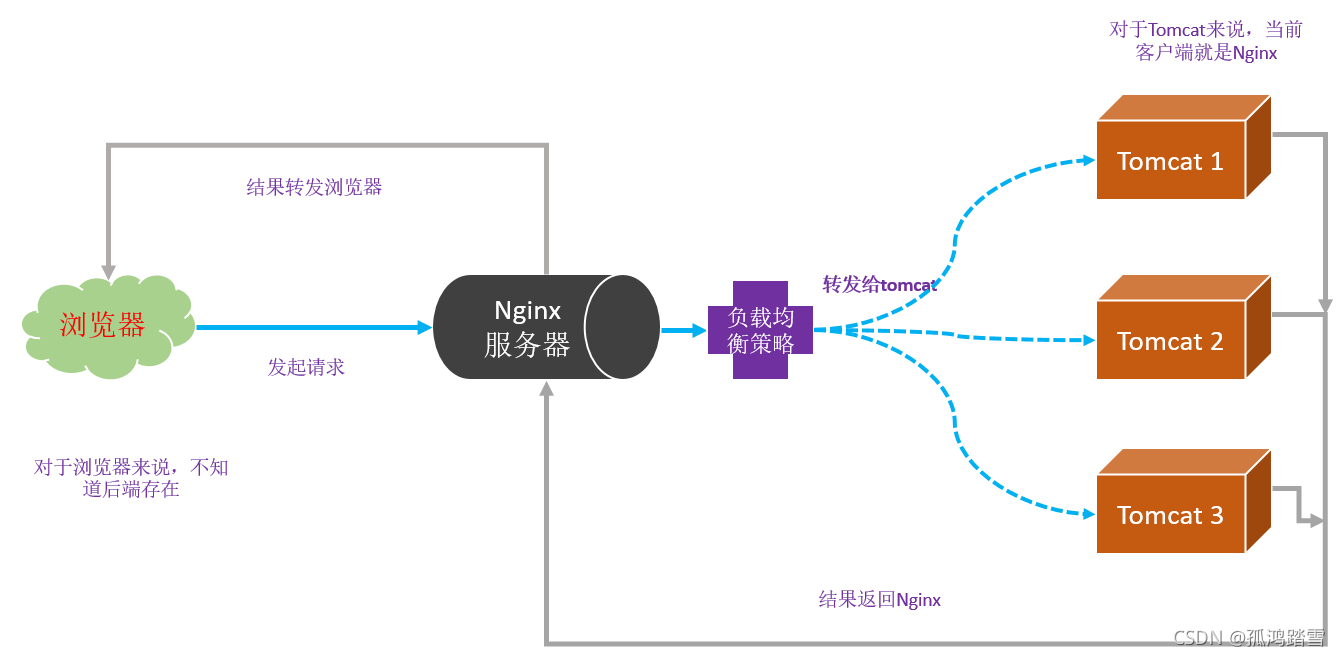
三個要素:
1.服務器組
2.nginx配置
3.負載均衡策略
首先要有多個服務器,形成服務器組,nginx通過反向代理,將請求發送到服務器組上,根據負載均衡策略,分配請求到具體的服務器上,
打開nginx檔案,實作負載均衡配置:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#定義服務器組,默認輪訓方式發送請求
upstream tomcats {
server 192.168.1.62:8080;
server 192.168.1.63:8080;
}
server {
listen 80;
server_name localhost;
location / {
#root html;
index index.html index.htm;
#代理配置: 服務器組名,請求發送給服務器組
proxy_pass http://tomcats;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
upstream 引數
...
#配置用于負載均衡的服務器集群資訊
upstream backends {
#均衡策略
#none 輪訓(權重由weight決定)
#ip_hash
#fair
#url_hash
server 192.168.1.62:8080;
server 192.168.1.63;
#weight:權重,值越高負載越大;
#server 192.168.1.64 weigth=5;
#backup: 備份機,只有非備份機都掛掉,才啟用:
server 192.168.1.64 backup;
#down: 停機標志,不會被訪問
server 192.168.1.64 down;
#max_fails:達到指定次數認為服務器掛掉;
#fail_timeout:掛掉之后過多久再去測驗是否已恢復
server 192.168.1.66 max_fails=2 fail_timeout=60s;
}
...
均衡策略
平均輪訓 默認
1:1
權重
根據權重不大, 分配的ip數量不同,默認1:1
upstream backends {
server 192.168.1.62:8080 weight=5;
server 192.168.1.63:8080 weight=3;
}
ip_hash
用戶訪問的ip第一次訪問的時候,會系結到某一個均衡策略里面,指定的服務器上面,后續該ip的請求的,都會訪問這個系結的服務器ip地址,
使用方式:
upstream backends {
ip_hash; #在這指定使用了ip_hash方式
server 192.168.1.62:8080 ;
server 192.168.1.63:8080 ;
}
fair
第三方擴展的
下載: nginx-upstream-fair-master.zip
編譯第三方檔案:
在編譯nginx的時候,
./configure --prefix=/opt/nginx --add-module=/tmp/nginx-upstream-fair-master
make & make install #如果第一次編譯,
make #如果nginx之前已經編譯過了, make:只是編譯
cd objs #里面是擴展包,用里面的nginx替換掉外部的nginx
(用nginx檔案帶著第三方擴展模塊,重新編譯,然后編譯的nginx替換掉之前的nginx檔案,即可)
動態自動的,對服務器負載高的的服務器增加請求數量,自動調節
upstream backends {
fair;
server 192.168.1.62:8080 ;
server 192.168.1.63:8080 ;
}
url_hash
第三方擴展的
根據用戶的url進行hash運算
電子商務網站,對于不同商品的,不同路徑,在快取了商品的獨一無二的url之后,用戶訪問的話,都會映射到一個服務器上,如果資料在服務器上面快取的話, 會極大提供并發,大量不同的商品在不同的服務器上面快取起來,
3.2 負載均衡是Session的處理策略
問題
分布式負載均衡情況下 session存在的問題:
服務訪問集群的時候,負載均衡策略把回應轉發到不同的tomcat中,會導致下次訪問請求,如果訪問的不是之前的保存session的那個tomcat,那么此次就會獲取不到session的值,
解決方式
三種策略,
1. 粘性session
用戶鎖定到某個tomcat中,
同一個用戶的請求鎖定到固定的某一個tomcat中,不存在session丟失的問題,
方式:ip_hash
優點:簡單,session無需額外處理
缺點:缺乏容錯性,這個tomcat一旦掛了,用戶立刻感知到
2. session復制
session改變,會在集群里面廣播,所有服務器同步session資料
優點:實時性好
缺點:網路負荷嚴重,可能造成后端性能低下
實作方式:
1.在tomcat的server.xml中開啟 session復制開關
找到模塊Engine
<Engine name="Catalina" defaultHost="localhost">
<!-- For clustering, please take a look at document at:
/docs/cluster-howto.html(simple how to)
/docs/config/cluster.html(reference documentation)
-->
#打開注釋 打開了tomcat的集群功能, tomcat7以后的版本,有默認值,可以無需配置,只需要打開這個即可
<Cuslter className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>
<!-- 基于網路廣播的策略,一個節點的session變化,其他節點同步復制,節點多或資料量大時性能低下 -->
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster" >
<Channel className="org.apache.catalina.tries.group.GroupChannel">
<Receiver className="org.apcache.catalina.tribes.transport.nio.NioReceiver" address="auto" port="4000" />
</Channel>
</Cluster>
</Engine>
2.在應用中通知tomcat,當前應用處于集群中
在web.xml中增加選項
<?xml version="1.0" encoding="UTF-8" ?>
...
#增加這個,標識當前應用可以處于集群當中
<distributable/>
...
在TOMCAT7以后,SERVER.XML取消CLUSTER這行注釋之后表示TOMCAT開啟了集群功能.TOMCAT的集群功能配備了發送器,接收器,內容轉換器,還有各種監聽借口,事件顯示幕等一系列功能.以上是在TOMCAT中的要進行修改的,對應的在開發的應用中要在WEB.XML中添加這么一條配置選項,位置如下圖.添加完這兩項配置后,這個應用就有了SESSION復制的功能了.
需要說明的是,因為在一臺服務器上可能不止有一個TOMCAT,在配置引數的時候,不要使用默認引數,要自行進行手動配置.首先要考慮的就是埠沖突問題.比如上方的示例,如果一臺服務器上有兩個TOMCAT,默認指定不同埠.地址也是一樣,因為開啟該項功能,如果設定的是AUTO,會自動選擇,如果選擇錯了,那么也就不能進行.通常服務器有兩個網卡,一個是內網網卡,一個是外網的,我們的接收器是系結在內網上的.因為我們的服務器集群是在內網的,所以接收器自然系結的是內網的網卡,如果綁錯了就會接收不到訊息.
接收器Receiver修改:
多個tomcat存在沖突,埠修改,另外,需要指定網路
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster" >
<Channel className="org.apache.catalina.tries.group.GroupChannel">
<Receiver className="org.apcache.catalina.tribes.transport.nio.NioReceiver" address="192.16.1.62" port="4002" />
</Channel>
</Cluster>
#另外一個:
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster" >
<Channel className="org.apache.catalina.tries.group.GroupChannel">
<Receiver className="org.apcache.catalina.tribes.transport.nio.NioReceiver" address="192.16.1.63" port="4003" />
</Channel>
</Cluster>
3. 共享空間保存session
對于Session來說,肯定是頻繁使用的,雖然你可以把它存放在資料庫中,但是真正生產環境中我更推薦存放在性能更快的分布式KV資料中,例如:Memcached和Redis,
借助分布式快取: memched,redis等,
粘性模式 MSM原理 sticky
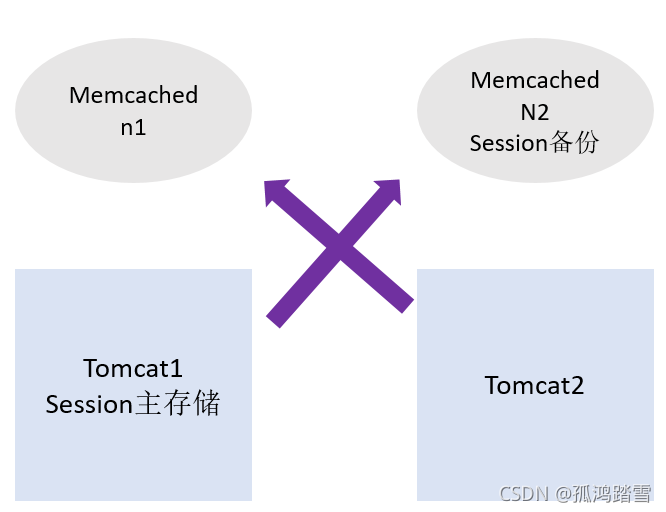
將用戶的每次請求固定到同一臺服務器,需要一到多個memcached存盤器,主從備份,資料一樣,
一個tomcat指定一個memcached存盤器,不同tomcat指定不同的memcached存盤器,
用戶請求到達tomcat,session會復制一份到memcached存盤器,下次來如果是讀取session,那么不需要讀取memcached存盤器,直接讀取tomcat上面的session資訊,
如果是修改session,tomcat修改完,資料保存到memcached存盤器,
如果tomcat宕機,用戶請求會轉移到另外一個tomcat上面,
如果用戶請求訪問了另外一個tomcat,tomcat沒有session,會去存盤器上訪問,資料保存到tomcat中,,相當于資料同步到tomcat中,
以tomcat為主存盤,備份session到存盤器中,tomcat中沒有資料的時候,從存盤器中獲取,
非粘性模式 MSM原理non-sticky
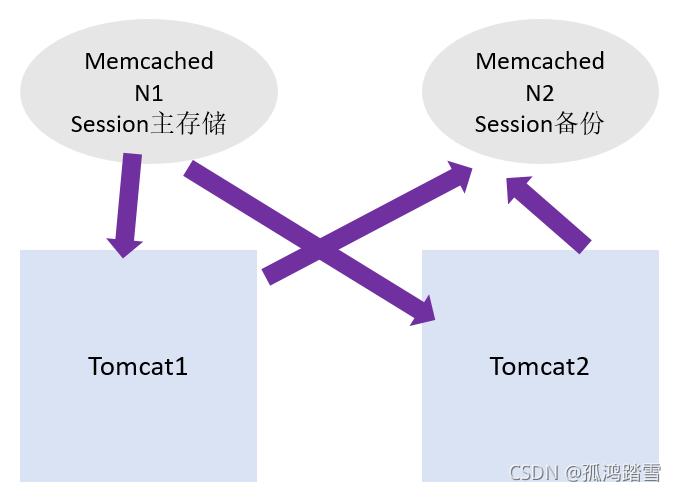
memcached有多個服務,其中一個是主存盤,其他是備份,資料是實時同步,
session資料寫入備份存盤器,同步到主存盤,tomcat不保存session,讀取的時候,從主存盤獲取,
msm配置:
1.復制jar包到tomcat/lib目錄,jar分三類
spymemcached.har memcached java客戶端
msm相關包
memcached-session-manager-{version}.jar 核心包
memcached-session-manager-tc{tomcat-version}-{version}.jar tomcat版本相關的包
- 序列化相關包,有多種可選方法,不設定時使用jdk自帶序列化,其他可選kryo,javaolution,xstream
msm-{tools}-serializer-{version}.jar
2.配置Context,加入處理session的Manager MemcachedBackupSessionManager
Context查找順序:
- conf/context.xml 全域配置,作用于所用應用
- conf/[enginename]/[hostname]/context.xml.default 全域配置,作用于指定host下全部應用
- conf/[enginename]/[hostname]/[contextpath].xml 只作用于contextpath指定的應用
- 應用META-INF/context.xml 只作用于本應用
- conf/server.xml 的模塊下, 作用于Context docBase指定的應用
所以,只希望session管理作用于特定應用,最好用3,4方式設定,希望作用于全體,可用1,2,5設定
舉個例子,
context-msm.xml
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<WatchedResource>WEB-INF/web.xml</WatchedResource>
<WatchedResource>${catalina.base}/conf/web.xml</WatchedResource>
<!--
sticky session最小配置
className 管理器型別
memcachedNodes memcached服務器節點,以節點名:主機:埠形式表示,其中節點名稱隨意命名,但不同tomcat之間名稱,應該同步
sticky隱含默認值為true,此時為sticky session模式
failoverNodes僅適用于sticky模式,n1表示主要將session備份到n2,如果n2不可用,再用n1
failoverNodes="n1",說明n2是這個tomcat主要用來備份(粘性模式,session主要存盤在tomcat中)的存盤器,n1是n2不可用的時候的被迫選擇,
另外一臺服務器配置,正好相反,這樣保證將session保存到其他機器,避免整個集群崩潰時tomcat與session都不可用
-->
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="n1:192.168.1.62:11211,n2:192.168.1.63:11211"
failoverNodes="n1"
/>
<!-- 經常用到的生產環境sticky模式配置 -->
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="n1:192.168.1.62:11211,n2:192.168.1.63:11211"
failoverNodes="n1"
#忽略的模式
requestUriIgnorePattern=".*\.(jpg|png|css|js)$"
#二進制的協議,效率更高
memcachedProtocol="binary"
#指定第三方的序列化工具,性能比jdk自帶的更高
transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory"
/>
<!-- 經常用到的生產環境non-sticky模式配置 -->
<Manager className="de.javakaffee.web.msm.MemcachedBackupSessionManager"
memcachedNodes="n1:192.168.1.62:11211,n2:192.168.1.63:11211"
sticky="false"
#粘性模式的時候, session異步備份模式,非粘性,需要同步
sessionBackupAsync="false"
#鎖模式,session備份寫入的時候,session才可以讀取等操作,防止session操作混亂
lockingMode="auto"
#忽略的模式
requestUriIgnorePattern=".*\.(jpg|png|css|js)$"
#二進制的協議,效率更高
memcachedProtocol="binary"
#指定第三方的序列化工具,性能比jdk自帶的更高
transcoderFactoryClass="de.javakaffee.web.msm.serializer.kryo.KryoTranscoderFactory"
/>
</Context>
4. 集群環境中應用代碼應注意的問題
4.1 物體類序列化支持
實作 介面 Serializable
session里面的物件想,需要序列化
// 可能會放到session中的物體類應實作Serializable介面
// 這樣才能保證成功使用jdk進行序列化
//第三方序列化工具一般不需要實作該介面
//但對無參構造,某些型別(如Map)序列化有特殊要求
//如果程式運行時出現序列化例外,需要參考工具相關檔案進行處理
public class User implements Serializable {
//實作了 介面 Serializable 的類建議生成一個serialVersionUID,他相當于一個類版本號,當類成員改變時,修改這個ID,這樣,jdk能正確識別已序列化實體與當前類定義是否版本一致
private static final long serialVersionUID= 1L;
...
}
4.2 獲取客戶端IP地址
如果是nginx反向代理,tomcat服務器以為nginx是客戶端,所以獲取了nginx服務器的地址,
如果要獲取真是的客戶端的IP地址,需要在nginx代理配置引數
server {
listen 80;
server_name localhost;
location / {
#root html;
index index.html index.htm;
proxy_pass http://tomcats;
# 增加這個配置 ,把真實地客戶端Ip地址放到請求頭中,nginx 內置的環境變數:$remote_addr
proxy_set_header X-Real-IP $remote_addr;
}
...
}
設定了nginx從客戶端中讀取的ip,放到了請求頭:"X-Real-IP"中,讀取如下:
//獲取真實IP
public static String getIp(HttpServletRequest request){
String remoteIp = request.GetRemoteAddr();
String headIp = request.getheader("X-Real-IP");
return headIp == null ? remoteIp : headIp;
}
4.3 nginx 中其他的資訊
#負載均衡設定,將所有jsp請求發送到upstream backends 指定的服務器群上
location ~ \.jsp$ {
proxy_pass http://backends;
#真實的客戶端IP
proxy_set_header X-Real_IP $remote_addr;
#請求頭中Host資訊, http://www.test.tt/index.jsp,用戶可以取到客戶端真實正確的host地址
proxy_set_header Host $host;
#代理路由資訊,此處取IP有安全隱患,整個代理的路由資訊,是各個nginx 等的ip資訊
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#真實的用戶訪問協議
proxy_set_header X-Forwarded-Proto $scheme;
#默認值是default
#后端response 302時,tomcat header中location的host是http://192.168.1.62:8080
#因為tomcat收到的請求是nginx發過去的,nginx發起的請求url host是http://192.168.1.62:80
#設定default后,nginx自動把回應有中的location host部分替換成當前用戶請求的host部分
#網上很多教程,將此值設定為 off 禁止了替換
#這樣用戶瀏覽器收到302后,跳到http://192.168.1.62:8080,直接將后端服務器暴露給瀏覽器
#所以除非特殊設定,否則不要做這種畫蛇添足的操作
proxy_redirect default;
}
4.4 動靜分離結果的預規劃
高并發,資源類的檔案,腳本,樣式表,檔案,
靜態檔案放到靜態服務器,
tomcat放到動態服務器中
開發之前規劃好,
總結:
負載均衡實作
session管理
5. 其他
Nginx 配置中nginx和alias的區別分析
root和alias都可以定義在location模塊中,都是用來指定請求資源的真實路徑;
root: *真實的路徑是root指定的值加上location指定的值 ,*
alias: 正如其名,alias指定的路徑是location的別名,不管location的值怎么寫,資源的 *真實路徑都是 alias 指定的路徑*
1、 alias 只能作用在location中,而root可以存在server、http和location中,
2、 alias 后面必須要用 “/” 結束,否則會找不到檔案,而 root 則對 ”/” 可有可無,
本小節參考博客: https://blog.csdn.net/tuoni123/article/details/79712246
本文參考來源:極客學院
如有侵權,聯系速刪
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/354585.html
標籤:其他