KMP 演算法是一種改進的字串匹配演算法,由 D.E.Knuth , J.H.Morris 和 V.R.Pratt 提出的,因此人們稱它為克努特 — 莫里斯 — 普拉特操作(簡稱 KMP 演算法), KMP 演算法的核心是利用匹配失敗后的資訊,盡量減少模式串與主串的匹配次數以達到快速匹配的目的,具體實作就是通過一個 next() 函式實作, 函式 本身包含了模式串的區域匹配資訊, KMP 算法的 時間復雜度 O(m+n) [1] , 來自 ------- 百度百科,
在學習kmp演算法之前我們需要理解BF演算法的原理:
BF演算法:
BF 演算法,即暴力演算法 ,是普通的模式匹配演算法, BF 演算法的思想就是將目標串 S 的第一個字符與模式串 T的第一個字符進行匹配,若相等,則繼續比較 S 的第二個字符和 T 的第二個字符;若不相等,則比較 S 的第二個字符和T 的第一個字符,依次比較下去,直到得出最后的匹配結果, BF 演算法是一種蠻力演算法
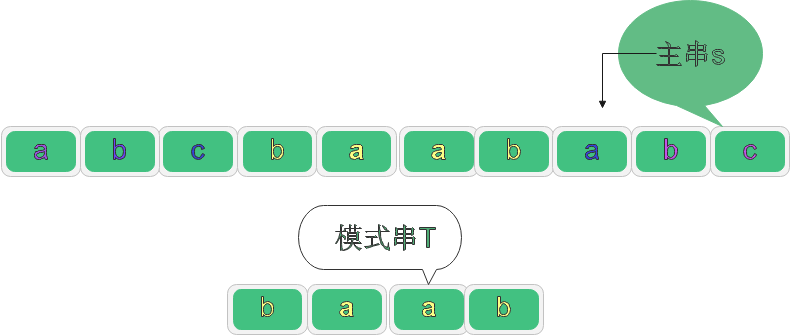
我們只需要定義一個變數i遍歷主串,定義一個變數j遍歷字串,暴力列舉即可
第一次匹配:
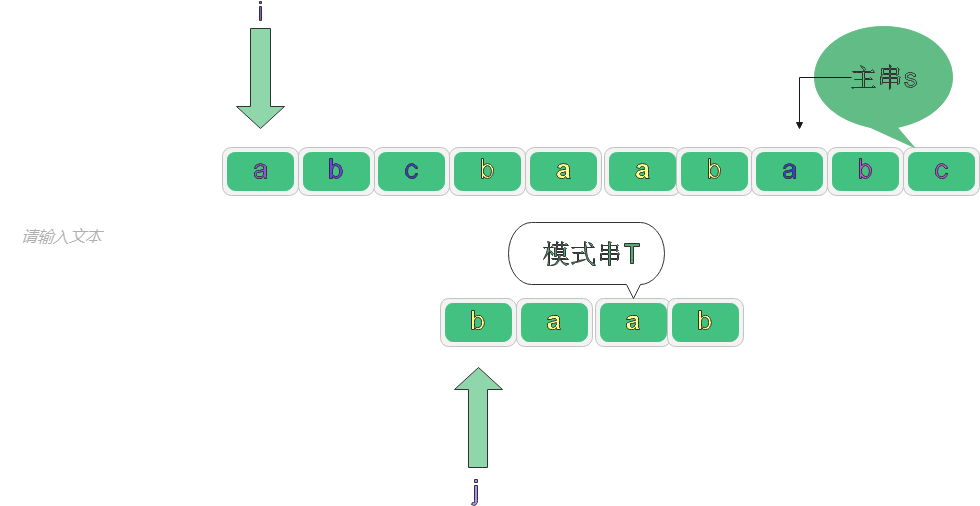
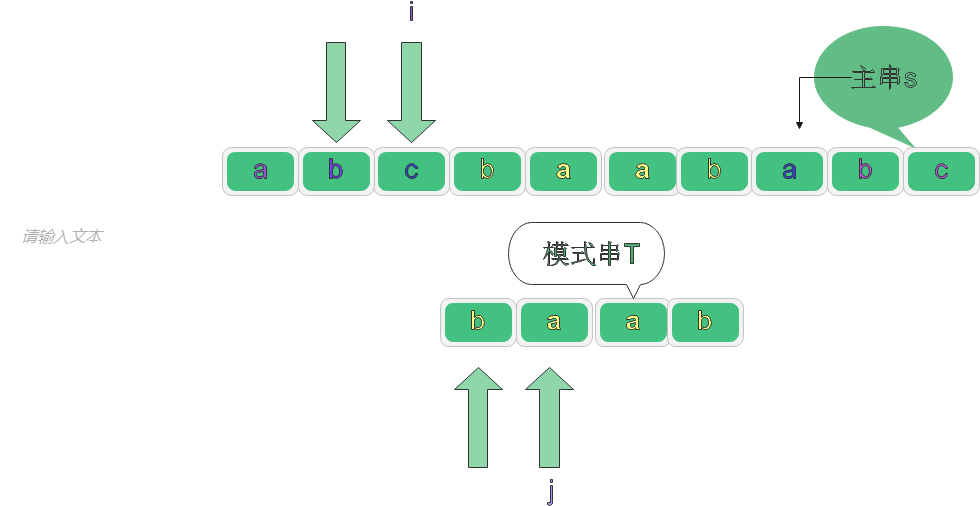
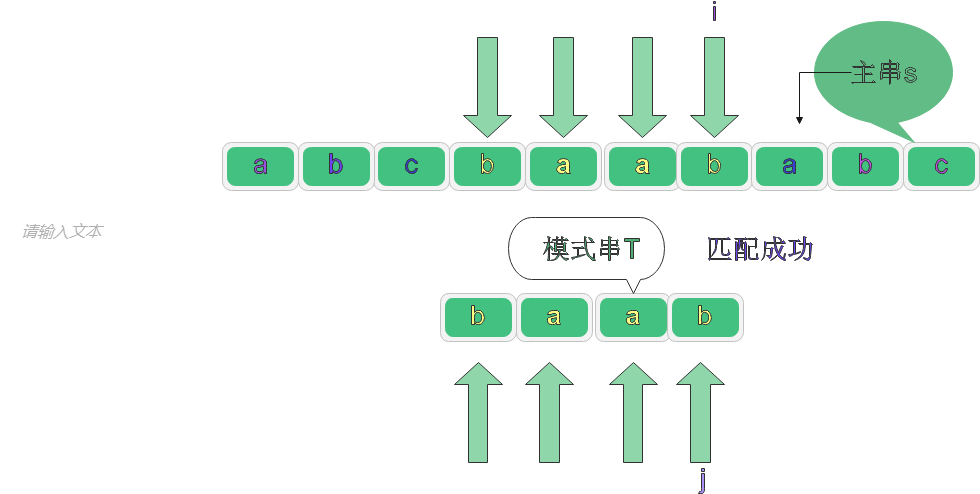
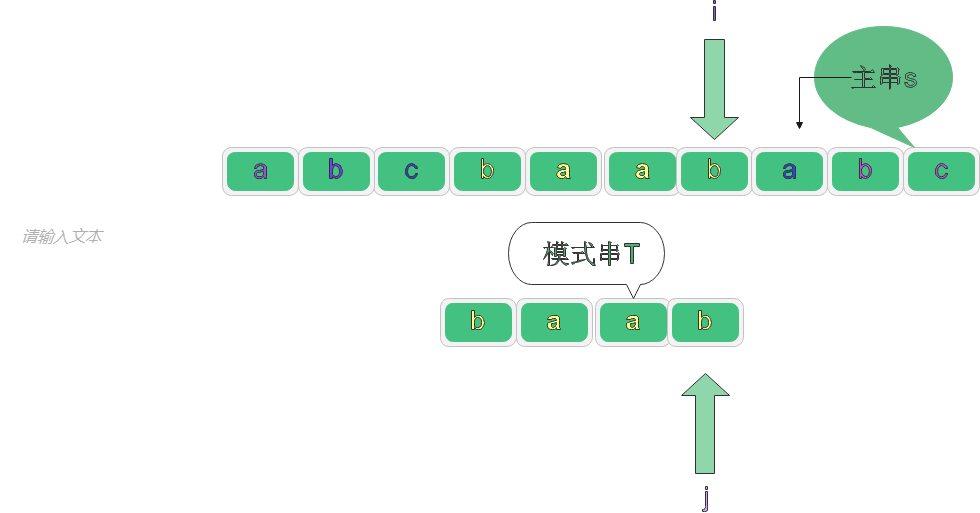
對應代碼:
int strStr(string haystack, string needle) { int n=haystack.size(); int m=needle.size(); for(int i=0;i<=n-m;i++){//每次回退到前一個位置的下一個位置 bool flag=1; for(int j=0;j<m;j++){//j每次匹配失敗后回退到0號位置 if(haystack[i+j]!=needle[j]){ flag=0; break; } } if(flag){ return i; } } return -1; }
i<=n-m的原因是當i走到主串的位置之后的字串的長度沒有字串長了那么就不用找了因為長度都不一樣所以i后面的字串肯定沒有要找的字串了
時間復雜度:
設主串長度為n,模式串長度為m,假設主串從第 i 個位置與模式串匹配成功,則此前 i-1 趟字符總比較了 i-1 次,第i趟成功比較字符次數為m,則總比較次數為 i-1+m 次,
對于成功匹配的主串,其起始位置由 1 到 n-m+1,假定這 n-m+1 個起始位置上的匹配概率相等,則最好的情況下匹配成功的平均比較次數為:所以最好情況下平均時間復雜度是O(n+m)
最壞情況是每次匹配不成功發生在模式串最后一個字符,直達主串最后一個字符與之匹配,復雜度為: O(n*m)
下面讓我們來看一下KMP演算法:
假設有這兩個串:
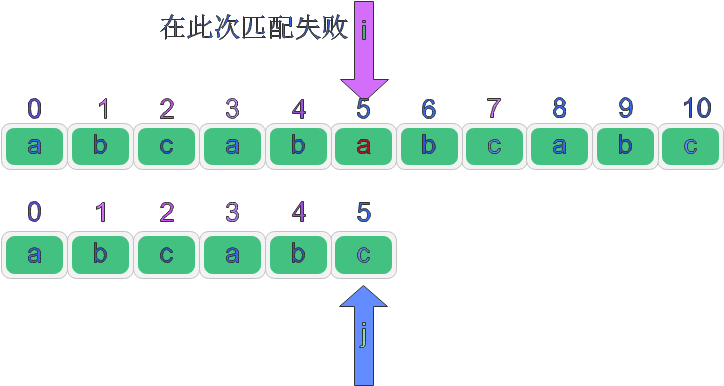
此時我們在紅色陰影處匹配失敗,綠色為匹配成功部分,如果按照BF演算法那么就要將i下標回退到起始位置的后一個位置,j回退到起始位置,此時我們發現這并沒有必要,因為回退之后i和j下標對應的值并不相等,
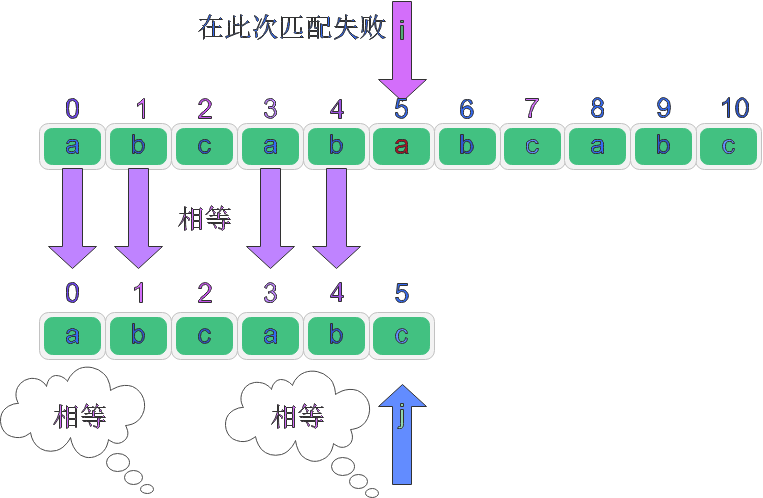
通過觀察我們可以發現:這4個ab都是相等的,此時我們通過觀察可以發現j回退到2號位置是最合適的,因為它最大程度的在主串中匹配字串,我們還可以發現j回退的位置的下標不就是ab的長度嗎也就是p[0]....p[1]=p[3]...p[4],再來看i和j下標對應的值是否相同如果不同則j要繼續回退
在這里我們就引出了next陣列:
next陣列的作用:保存字串某個位置失敗后回退的位置
KMP 的精髓就是 next 陣列:也就是用 next[j] = k;來表示,不同的 j 來對應一個 K 值, 這個 K 就是你將來要移動的 j要移動的位置,而 K 的值是這樣求的:1、規則:找到匹配成功部分的兩個相等的真子串(不包含本身),一個以下標 0 字符開始,另一個以 j-1 下標字符結尾,2、不管什么資料 next[0] = -1;next[1] = 0;在這里,我們以下標來開始,而說到的第幾個第幾個是從 1 開始;
求next陣列的練習:
練習 1: 舉例對于”ababcabcdabcde”, 求其的 next 陣列?
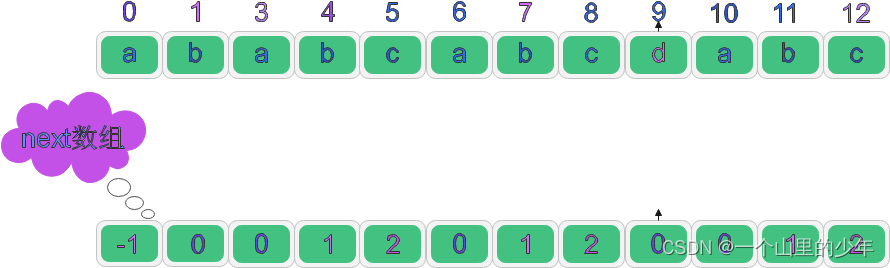
到這里大家對如何求next陣列應該問題不大了,接下來的問題就是,已知next[i] = k;怎么求next[i+1] = ?如果我們能夠通過 next[i]的值,通過一系列轉換得到 next[i+1]得值,那么我們就能夠實作這部分,那該怎么做呢?首先假設: next[i] = k 成立,那么,就有這個式子成立: P0...Pk-1 = Px...Pi-1;得到: P0...Pk-1 = Pi-k..Pi-1;到這一步:我們再假設如果 Pk = Pi;我們可以得到 P0...Pk = Pi-k..Pi;那這個就是 next[i+1] = k+1;
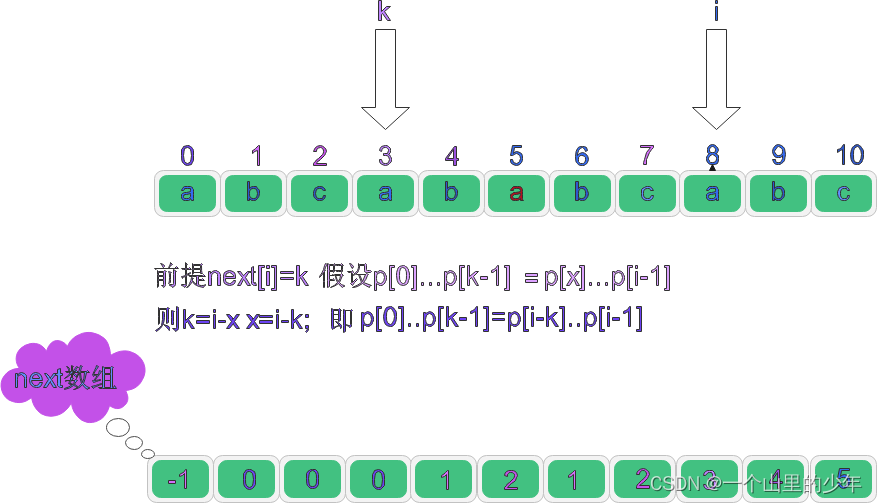
在p[0]..p[k-1]=p[i-k]..p[i-1]的前提下又有p[i]=p[k]那么就有next[i+1]=k+1;
那么如果p[i]!=p[k]那么next[i+1]=?
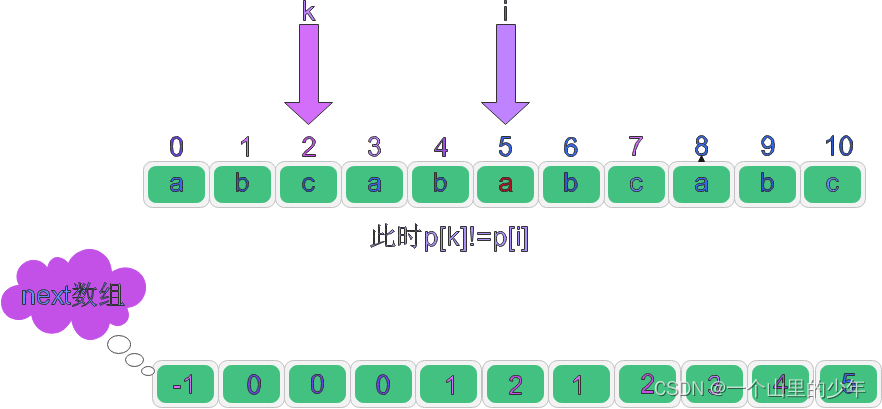
此時p[k]!=p[i]那為什么next[i+1]=1了?這也意味著回退到的2號位置不一定是我們要找的數字,此時需要繼續回退,k就回退到nxet[k]對應的位置如果仍然沒有p[i]!=p[k]那么就一直回退直到p[k]=p[i]
下面我們來看一下代碼:
int strStr(string haystack, string needle) { int len1=haystack.size(); int len2=needle.size(); if(len1==0&&len2!=0)return -1; if(len1==0&&len2==0)return 0; if(len1!=0&&len2==0)return 0; int i=0;//遍歷主串 int j=0;//遍歷字串 int *next=new int [len2]; Getnext(next,needle); while(i<len1&&j<len2){ if((j==-1)||haystack[i]==needle[j]){ i++; j++; } else{ j=next[j]; } } if(j>=len2) return i-j; else return-1; }
注意:如果一上來就匹配失敗:那么j就會回退到-1的位置此時就會越界,所以我們要加這個特判,如果一上來就匹配失敗j回到起始位置i繼續往后走即可
對應next陣列代碼:
void Getnext(int *next,string&needle){ int len=needle.size(); next[0]=-1; if(len==1)return; next[1]=0; int k=0;//前一項的K int i=2;//此時i表示當前下標,也就是下一項 while(i<len){ if(k==-1||needle[i-1]==needle[k]){ next[i]=k+1; k++; i++; } else{ k=next[k];//此陳述句是這段代碼最反人類的地方,如果你一下子就能看懂,那么請允許我稱呼你一聲大神! } } }
注意:1.如果字串的長度只有1我們需要特判一下防止next陣列越界 .
2.i代表的是當前下標,也就是之前的i+1;
3.如果k回退到-1時需要特判
總代碼:
class Solution { public: void Getnext(int *next,string&needle){ int len=needle.size(); next[0]=-1; if(len==1)return; next[1]=0; int k=0;//前一項的K int i=2;//此時i表示當前下標,也就是下一項 while(i<len){ if(k==-1||needle[i-1]==needle[k]){ next[i]=k+1; k++; i++; } else{ k=next[k]; } } } int strStr(string haystack, string needle) { int len1=haystack.size(); int len2=needle.size(); if(len1==0&&len2!=0)return -1; if(len1==0&&len2==0)return 0; if(len1!=0&&len2==0)return 0; int i=0;//遍歷主串 int j=0;//遍歷字串 int *next=new int [len2]; Getnext(next,needle); while(i<len1&&j<len2){ if((j==-1)||haystack[i]==needle[j]){ i++; j++; } else{ j=next[j]; } } if(j>=len2)//匹配成功 return i-j; else return-1;//匹配失敗 } };
最后:🙌🙌🙌🙌
結語:對于個人來講,在演算法上進行探索以及單人闖關是一件有趣的時間,一個程式員,如果不喜歡編程,那么可能就失去了這份職業的樂趣,刷到我的文章的人,我希望你們可以駐足一小會,忙里偷閑的閱讀一下我的文章,可能文章的內容對你來說很簡單,(^▽^)不過文章中的每一個字都是我認真專注的見證!希望您看完之后,若是能幫到您,勞煩請您簡單動動手指鼓勵我,我必回報更大的付出~

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/374845.html
標籤:其他
上一篇:Hadoop環境搭建筆記