目錄
1 Http原理
1.1 為啥會有應用層
1.2 什么是url
1.3 urlencode和urldecode
1.4 Http協議格式
1.5 Http的方法
1.6 Http的狀態碼
? 最常見的狀態碼, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
1.7 Http常見的Header
2 Http server
3.1 用戶資訊
3.3 session
4 簡單的html
4.1 html介紹
總結
1 Http原理
1.1 為啥會有應用層
我們已經學過
TCP/IP
,
已經知道目前資料能從客戶端行程經過路徑選擇跨網路傳送到服務器端行程
[
IP+Port
],
可
是,僅僅把資料從
A
點傳送到
B
點就完了嗎?這就好比,在淘寶上買了一部手機,賣家
[
客戶端
]
把手機通過順豐
[
傳送
+
路徑選擇
]
送到買家
[
服務器
]
手里就完了嗎?當然不是,買家還要使用這款產品,還要在使用之后,給賣家打分評
論,所以,我們把資料從
A
端傳送到
B
端,
TCP/IP
解決的是順豐的功能,而兩端還要對資料進行加工處理或者使用,
所以我們還需要一層協議,不關心通信細節,關心應用細節!
這層協議叫做應用層協議,而應用是有不同的場景的,所以應用層協議是有不同種類的,其中經典協議之一的
HTTP
就是其中的佼佼者,那么,
Http
是解決什么應用場景呢?
早期用戶,上網使用瀏覽器來進行上網,而用瀏覽器上網閱讀資訊,最常見的是查看各種網頁【其實也是檔案資料, 不過是一系列的 html
檔案,當然還有其他資源如圖片,
css
,
js
等】
,
而要把網頁檔案資訊通過網路傳送到客戶
端,或者把用戶資料上傳到服務器,就需要
Http
協議【當然,
http
作用不限于此】
那如何理解應用層協議呢?再回到我們剛剛說的買手機的例子,順豐相當于
TCP/IP
的功能,那么買回來的手機都附
帶了說明書【產品介紹,使用介紹,注意事項等】,而該說明書指導用戶該如何使用手機【雖然我們都不看,但是父
母輩有部分是有看說明書的習慣的:)】,此時的說明書可以理解為用戶層協議
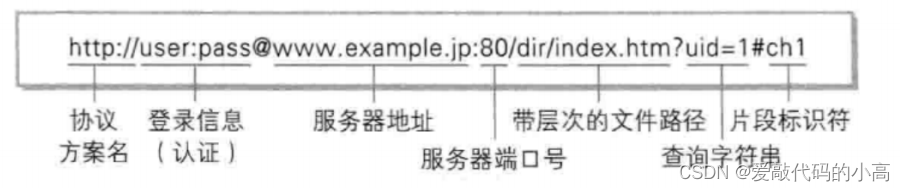
1.2 什么是url
平時我們俗稱的
"
網址
"
其實就是說的
URL
1.3 urlencode和urldecode
像
/ ? :
等這樣的字符
,
已經被
url
當做特殊意義理解了
.
因此這些字符不能隨意出現
.
比如
,
某個引數中需要帶有這些特殊字符
,
就必須先對特殊字符進行轉義
.
轉義的規則如下
:
將需要轉碼的字符轉為
16
進制,然后從右到左,取
4
位
(
不足
4
位直接處理
)
,每
2
位做一位,前面加上
%
,編碼成
%XY
格式
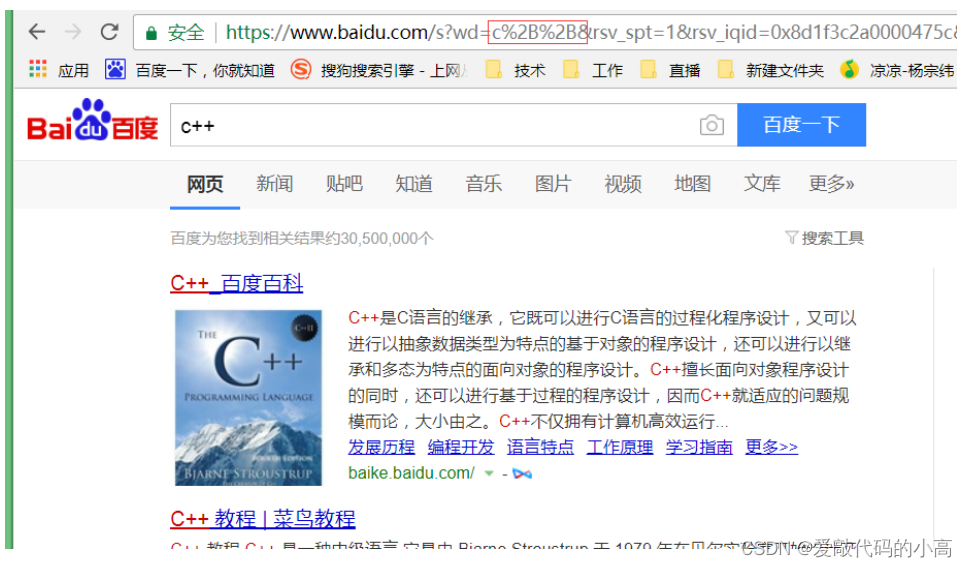
"+"
被轉義成了
"%2B"
urldecode
就是
urlencode
的逆程序
;
1.4 Http協議格式
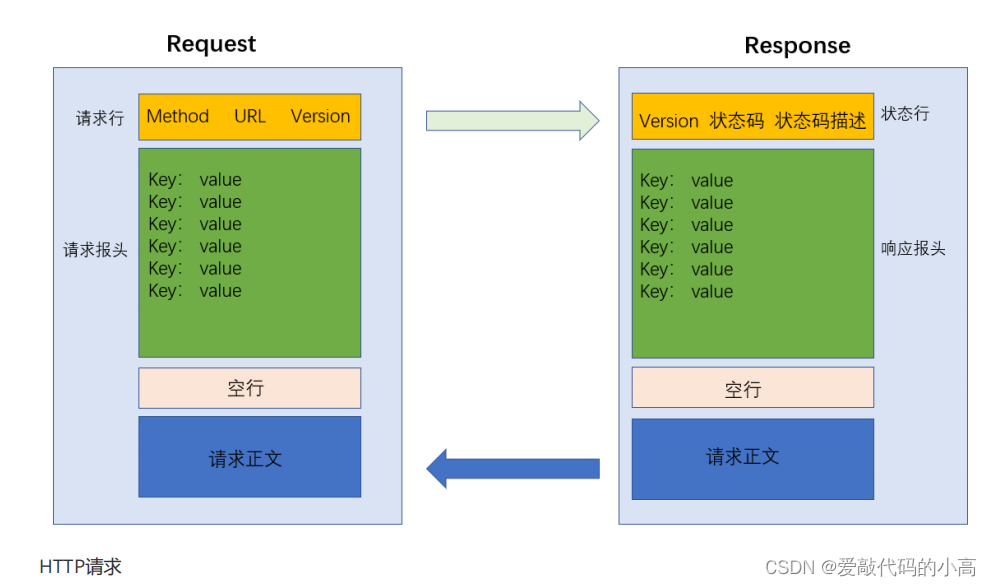
首行
: [
方法
] + [url] + [
版本
]
Header:
請求的屬性
,
冒號分割的鍵值對
;
每組屬性之間使用
\n
分隔
;
遇到空行表示
Header
部分結束
Body:
空行后面的內容都是
Body. Body
允許為空字串
.
如果
Body
存在
,
則在
Header
中會有一個
Content
Length
屬性來標識
Body
的長度
;
HTTP
回應
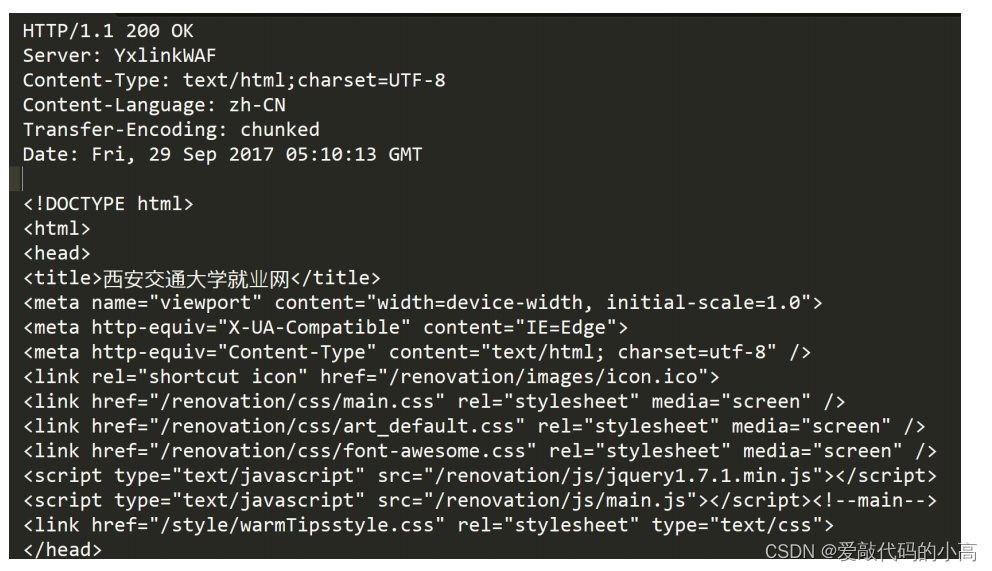
首行
: [
版本號
] + [
狀態碼
] + [
狀態碼解釋
]
Header:
請求的屬性
,
冒號分割的鍵值對
;
每組屬性之間使用
\n
分隔
;
遇到空行表示
Header
部分結束
Body:
空行后面的內容都是
Body. Body
允許為空字串
.
如果
Body
存在
,
則在
Header
中會有一個
Content
Length
屬性來標識
Body
的長度
;
如果服務器回傳了一個
html
頁面
,
那么
html
頁面內容就是在
body
中
.
1.5 Http的方法
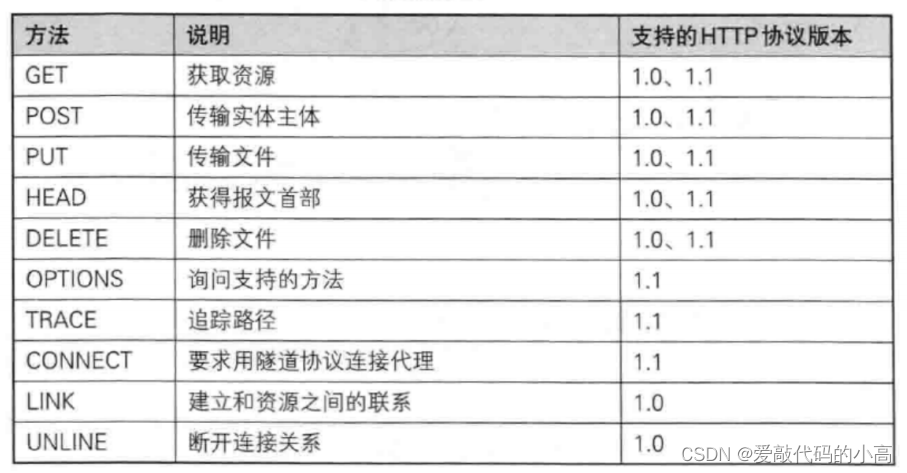
其中最常用的就是GET方法和POST方法.
1.6 Http的狀態碼
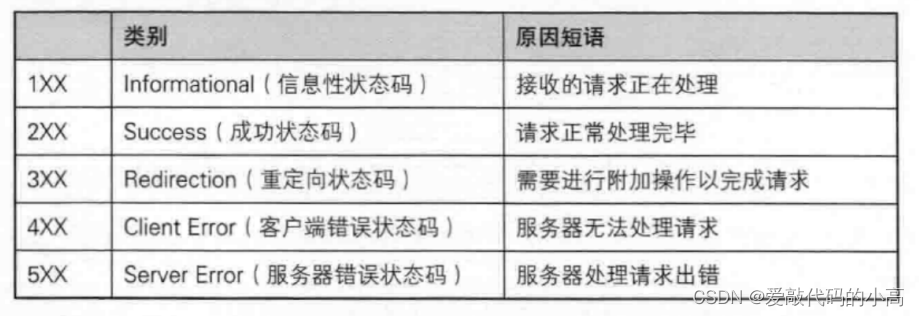 最常見的狀態碼, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
最常見的狀態碼, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
1.7 Http常見的Header
Content-Type:
資料型別
(text/html
等
)
Content-Length: Body
的長度
Host:
客戶端告知服務器
,
所請求的資源是在哪個主機的哪個埠上
;
User-Agent:
宣告用戶的作業系統和瀏覽器版本資訊
;
referer:
當前頁面是從哪個頁面跳轉過來的
;
location:
搭配
3xx
狀態碼使用
,
告訴客戶端接下來要去哪里訪問
;
Cookie:
用于在客戶端存盤少量資訊
.
通常用于實作會話
(session)
的功能
;
2 Http server


3 session 和cookie
3.1 用戶資訊
Http
是一個無狀態協議
,
就是說這一次請求和上一次請求是沒有任何關系的,互不認識的,沒有關聯的,這種無狀態
的的好處是快速,壞處是需要進行用戶狀態保持的場景時
[
比如,登陸狀態下進行頁面跳轉,或者用戶資訊多頁面共
享等場景
]
,必須使用一些方式或者手段比如:
session
和
cookie
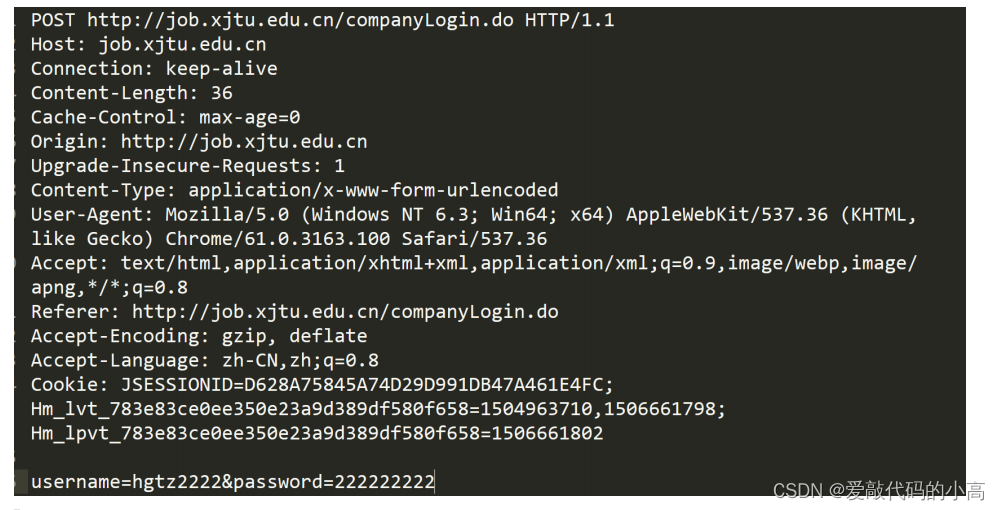
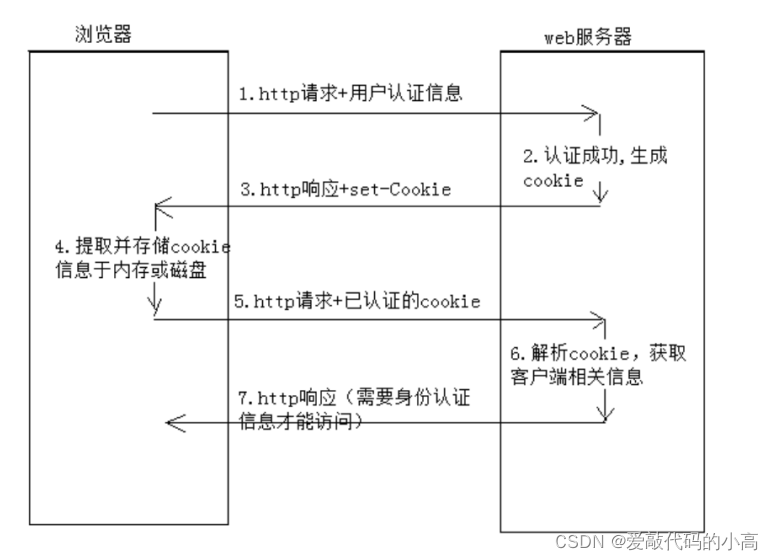
3.2 cookie
如上所述,
Http
是一個無狀態的協議,但是訪問有些資源的時候往往需要經過認證的賬戶才能訪問,而且要一直保
持在線狀態,所以,
cookie
是一種在瀏覽器端解決的方案,將登陸認證之后的用戶資訊保存在本地瀏覽器中,后面每
次發起
http
請求,都自動攜帶上該資訊,就能達到認證用戶,保持用戶在線的作用,具體如下圖:
3.3 session
而將用戶敏感資訊放到本地瀏覽器中,能解決一定的問題,但是又引進了新的安全問題,一旦
cookie
丟失,用戶資訊
泄露,也很容易造成跨站攻擊,所以有了另一種解決方法,將用戶敏感資訊保存至服務器,而服務器本身采用
md5
算
法或相關演算法生成唯一值(
session id
),將該值保存值客戶端瀏覽器,隨后,客戶端的后續請求,瀏覽器都會自動
攜帶該
id
,進而再在服務器端認證,進而達到狀態保持的效果
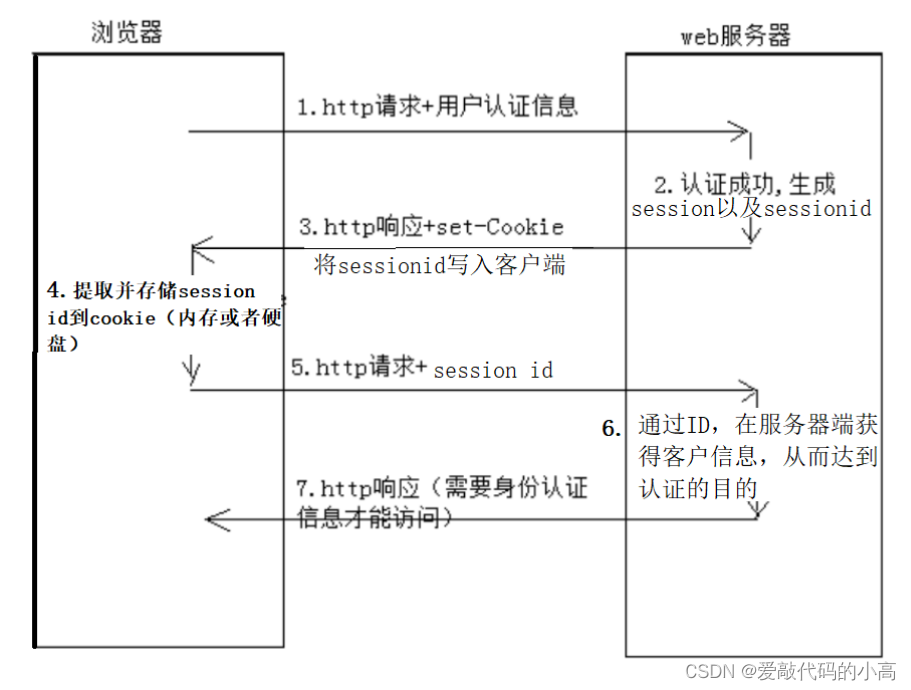
3.4 cookie和session的區別
Cookie
以文本檔案格式存盤在瀏覽器中,而
session
存盤在服務端
因為每次發起
Http
請求,都要攜帶有效
Cookie
資訊,所以
Cookie
一般都有大小限制,以防止增加網路壓力
,
一
般不超過
4k
可以輕松訪問
cookie
值但是我們無法輕松訪問會話值,因此
session
方案更安全
4 簡單的html
4.1 html介紹
HTML
是用于創建網頁的語言,我們通過使用
HTML
標記標簽創建
html
檔案來創建網頁,
HTML
代表超文本標記
語言,
HTML
是一種標記語言,它是標記標簽的集合,
HTML
標簽是由尖括號括起來的詞,如
<html>
,
<body>
,標簽通常成對出現,例如
<html>
和
</html>
,
一對中的第一個標簽是開始標簽
;
第二個標簽是結束標簽,如是開始標簽,而
</html>
是結束標簽,我們還可以
將開始標簽稱為起始標簽,結束標簽稱為閉合標簽,
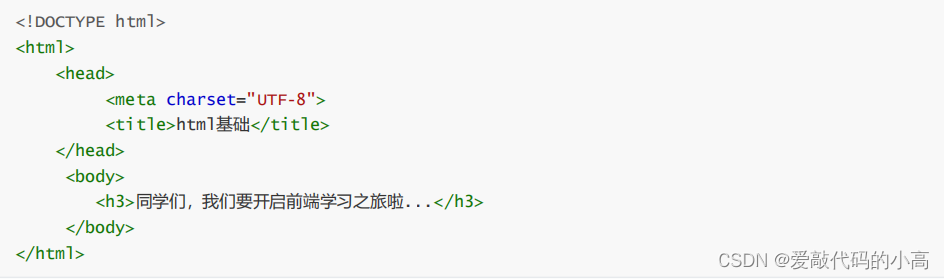
HTML
檔案結構至少要包括
head, body
兩部分
.
如
:
總結
本次的網路編程分享到此為止,內容指定有很多不足,但學習本就是一個循序漸進的程序,我也會繼續學習相關知識,繼續和大家一起來分享,大家務必不吝賜教,在此感激不盡!!!越來越好!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/377033.html
標籤:其他
上一篇:【期末不掛科】計算機網路 物理層
下一篇:清華老師終于把TCP協議講清楚了