TCP協議
TCP協議的特點是:面向連接、位元組流和可靠傳輸,
使用TCP協議通信的雙方必須先建立連接,然后才能開始資料的讀寫,雙方都必須為該連接分配必要的內核資源,以管理連接的狀態和連接上資料的傳輸,TCP連接是全雙工的,即雙方的資料讀寫可以通過一個連接進行,完成資料交換之后,通信雙方都必須斷開連接以釋放系統資源,
-
TCP協議采用回傳確認機制,即發送端發送的每個TCP報文段都必須得到接收方的應答,才認為這個TCP報文段傳輸成功,
-
TCP協議采用超時重傳機制,發送端在發送出一個TCP報文段之后啟動定時器,如果在定時時間內未收到應答,它將重發該報文段,
-
TCP報文段最終是以IP資料報發送的,而IP資料報到達接收端可能亂序、重復,所以TCP協議還會對接收到的TCP報文段重排、整理,再交付給應用層
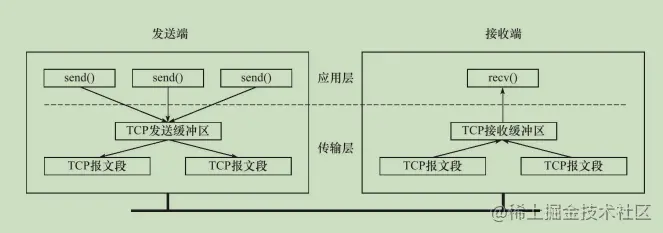
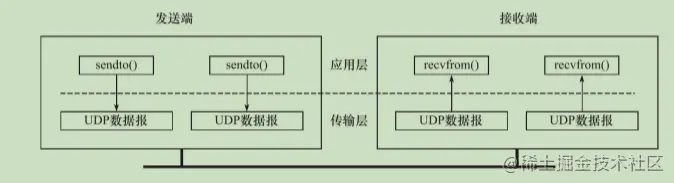
TCP會將資料放到緩沖區當中,接收端應用程式可以一次性將TCP接識訓沖區中的資料全部讀出,也可以分多次讀取,但是UDP每發送一個資料包,接收端必須及時針對每一個UDP資料報執行讀操作(通過recvfrom系統呼叫),否則就會丟包,
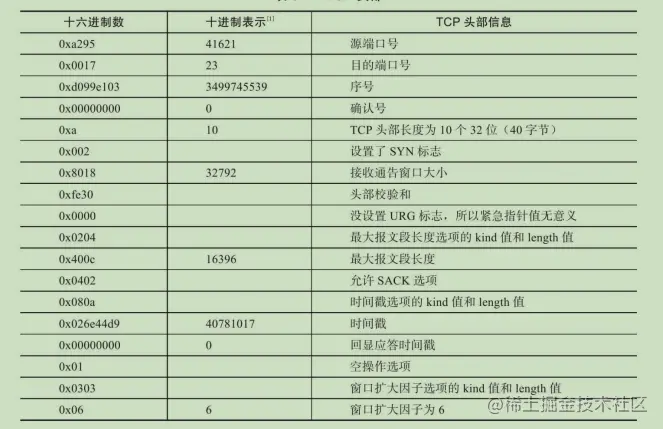
TCP頭部結構

-
16位埠號(port number):告知主機該報文段是來自哪里(源埠)以及傳給哪個上層協議或應用程式(目的埠)的,進行TCP通信時,客戶端通常使用系統自動選擇的臨時埠號,而服務器則使用知名服務埠號,所有知名服務使用的埠號都定義在/etc/services檔案中,
-
32位序號(sequence number):一次TCP通信(從TCP連接建立到斷開)程序中某一個傳輸方向上的位元組流的每個位元組的編號,假設主機A和主機B進行TCP通信,A發送給B的第一個TCP報文段中,序號值被系統初始化為某個隨機值ISN(Initial Sequence Number,初始序號值),那么在該傳輸方向上(從A到B),后續的TCP報文段中序號值將被系統設定成ISN加上該報文段所攜帶資料的第一個位元組在整個位元組流中的偏移,例如,某個TCP報文段傳送的資料是位元組流中的第1025~2048位元組,那么該報文段的序號值就是ISN+1025,另外一個傳輸方向(從B到A)的TCP報文段的序號值也具有相同的含義,
-
32位確認號(acknowledgement number):用作對另一方發送來的TCP報文段的回應,其值是收到的TCP報文段的序號值加1,假設主機A和主機B進行TCP通信,那么A發送出的TCP報文段不僅攜帶自己的序號,而且包含對B發送來的TCP報文段的確認號,反之,B發送出的TCP報文段也同時攜帶自己的序號和對A發送來的報文段的確認號,
-
4位頭部長度(header length):標識該TCP頭部有多少個32bit字(4位元組),因為4位最大能表示15,所以TCP頭部最長是60位元組,
-
6位標志位包含如下幾項:
- URG標志,表示緊急指標(urgent pointer)是否有效,
- ACK標志,表示確認號是否有效,我們稱攜帶ACK標志的TCP報文段為確認報文段,
- PSH標志,提示接收端應用程式應該立即從TCP接識訓沖區中讀走資料,為接收后續資料騰出空間(如果應用程式不將接收到的資料讀走,它們就會一直停留在TCP接識訓沖區中),
- RST標志,表示要求對方重新建立連接,我們稱攜帶RST標志的TCP報文段為復位報文段,
- SYN標志,表示請求建立一個連接,我們稱攜帶SYN標志的TCP報文段為同步報文段,
- FIN標志,表示通知對方本端要關閉連接了,我們稱攜帶FIN標志的TCP報文段為結束報文段,
-
16位視窗大小(window size):是TCP流量控制的一個手段,這里說的視窗,指的是接收通告視窗(Receiver Window,RWND),它告訴對方本端的TCP接識訓沖區還能容納多少位元組的資料,這樣對方就可以控制發送資料的速度,
-
16位校驗和(TCP checksum):由發送端填充,接收端對TCP報文段執行CRC演算法以檢驗TCP報文段在傳輸程序中是否損壞,注意,這個校驗不僅包括TCP頭部,也包括資料部分,這也是TCP可靠傳輸的一個重要保障,
-
16位緊急指標(urgent pointer):是一個正的偏移量,它和序號欄位的值相加表示最后一個緊急資料的下一位元組的序號,因此,確切地說,這個欄位是緊急指標相對當前序號的偏移,不妨稱之為緊急偏移,TCP的緊急指標是發送端向接收端發送緊急資料的方法,
TCP連接
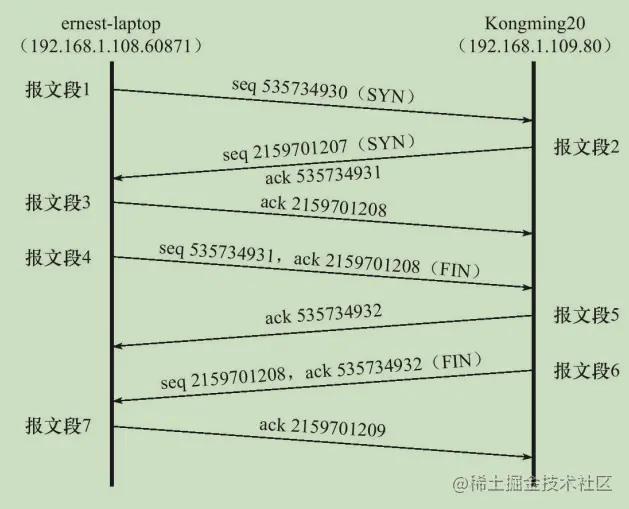
TCP三次握手
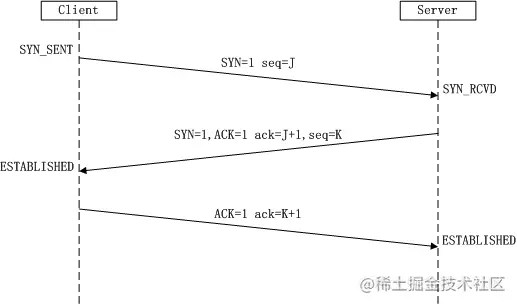
- 客戶端向服務器發送一個連接請求,將標志位SYN置為1,隨機產生一個值seq=J,并將該資料包發送給服務器,等待服務器確認,
- 服務器收到資料包后由標志位SYN=1知道Client請求建立連接,Server將標志位SYN和ACK都置為1,ack=J+1,隨機產生一個值seq=K,并將該資料包發送給Client以確認連接請求,Server進入SYN_RCVD狀態,
- 客戶端檢查標志位,確認連接建立,回傳資料包,ACK=1,此時已經可以攜帶資料
TCP四次揮手
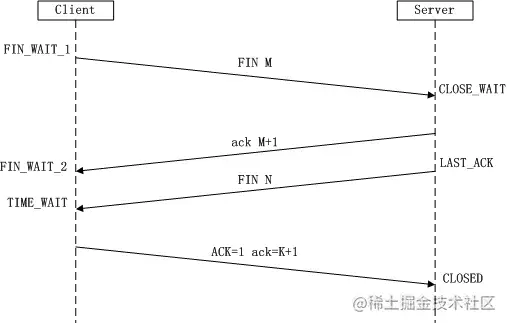
由于TCP連接時全雙工的,因此,每個方向都必須要單獨進行關閉,這一原則是當一方完成資料發送任務后,發送一個FIN來終止這一方向的連接,收到一個FIN只是意味著這一方向上沒有資料流動了,即不會再收到資料了,但是在這個TCP連接上仍然能夠發送資料,直到這一方向也發送了FIN,首先進行關閉的一方將執行主動關閉,而另一方則執行被動關閉
- Client發送一個FIN,用來關閉Client到Server的資料傳送,Client進入FIN_WAIT_1狀態,
- Server收到FIN后,發送一個ACK給Client,確認序號為收到序號+1,Server進入CLOSE_WAIT狀態,
- Server發送一個FIN,用來關閉Server到Client的資料傳送,Server進入LAST_ACK狀態,
- Client收到FIN后,Client進入TIME_WAIT狀態,接著發送一個ACK給Server,確認序號為收到序號+1,Server進入CLOSED狀態,完成四次揮手
TCP超時重傳
客戶端在長時間未收到回應報文時會重傳報文,例如,重傳時間間隔由/proc/sys/net/ipv4/tcp_syn_retries內核變數所定義,每次重連的超時時間都增加一倍,在5次重連均失敗的情況下,TCP模塊放棄連接并通知應用程式,
TCP狀態轉移
TCP連接的任意一端在任一時刻都處于某種狀態,當前狀態可以通過netstat命令查看
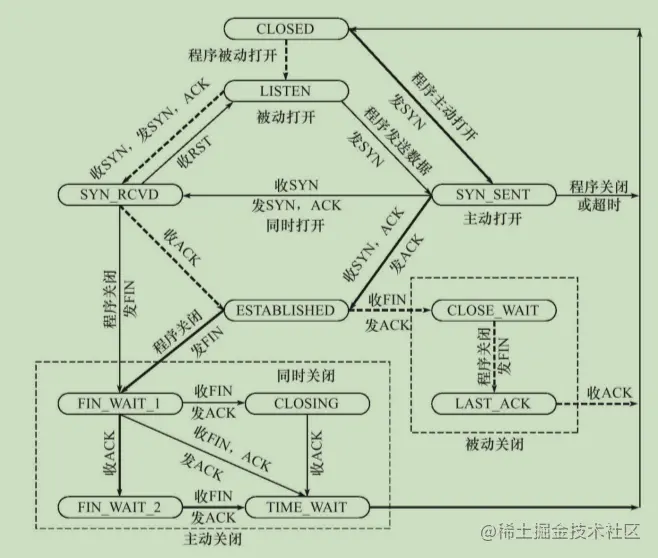
客戶端狀態
客戶端通過connect系統呼叫主動與服務器建立連接,connect系統呼叫首先給服務器發送一個同步報文段,使連接轉移到SYN_SENT狀態,此后,connect系統呼叫可能因為如下兩個原因失敗回傳:
- 如果connect連接的目標埠不存在(未被任何行程監聽),或者該埠仍被處于TIME_WAIT狀態的連接所占用,則服務器將給客戶端發送一個復位報文段,connect呼叫失敗,
- 如果目標埠存在,但connect在超時時間內未收到服務器的確認報文段,則connect呼叫失敗,
connect呼叫失敗將使連接立即回傳到初始的CLOSED狀態,如果客戶端成功收到服務器的同步報文段和確認,則connect呼叫成功回傳,連接轉移至ESTABLISHED狀態,
當客戶端執行主動關閉時,它將向服務器發送一個結束報文段,同時連接進入FIN_WAIT_1狀態,若此時客戶端收到服務器專門用于確認目的的確認報文段,則連接轉移至FIN_WAIT_2狀態,當客戶端處于FIN_WAIT_2狀態時,服務器處于CLOSE_WAIT狀態,這一對狀態是可能發生半關閉的狀態,此時如果服務器也關閉連接(發送結束報文段),則客戶端將給予確認并進入TIME_WAIT狀態,
服務器狀態
服務器通過listen系統呼叫進入LISTEN狀態,被動等待客戶端連接,因此執行的是所謂的被動打開,服務器一旦監聽到某個連接請求(收到同步報文段),就將該連接放入內核等待佇列中,并向客戶端發送帶SYN標志的確認報文段,此時該連接處于SYN_RCVD狀態,如果服務器成功地接收到客戶端發送回的確認報文段,則該連接轉移到ESTABLISHED狀態,ESTABLISHED狀態是連接雙方能夠進行雙向資料傳輸的狀態,
當客戶端主動關閉連接時(通過close或shutdown系統呼叫向服務器發送結束報文段),服務器通過回傳確認報文段使連接進入CLOSE_WAIT狀態,這個狀態的含義很明確:等待服務器應用程式關閉連接,通常,服務器檢測到客戶端關閉連接后,也會立即給客戶端發送一個結束報文段來關閉連接,這將使連接轉移到LAST_ACK狀態,以等待客戶端對結束報文段的最后一次確認,一旦確認完成,連接就徹底關閉了,
TCP擁塞控制
滑動視窗
為了解決可靠傳輸以及包亂序的問題,TCP 引入滑動視窗的概念,在傳輸程序中,client 和 server 協商接收視窗 rwnd,再結合擁塞控制視窗 cwnd 計算滑動視窗 swnd,在 Linux 內核實作中,滑動視窗 cwnd 是以包為單位,所以在計算 swnd 時需要乘上 mss(最大分段大小),
![[公式]](https://img.uj5u.com/2021/12/09/286264090748489.png)
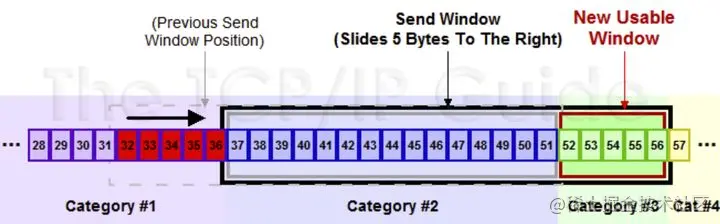
滑動視窗包含 4 部分:
- 已收到 ack 確認的資料;
- 已發還沒收到 ack 的;
- 在視窗中還沒有發出的(接收方還有空間);
- 視窗以外的資料(接收方沒空間),
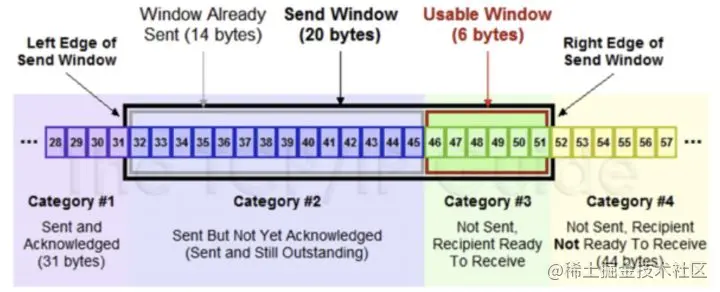
滑動后的示意圖如下(收到 36 的 ack,并發出了 46-51 的資料):
擁塞控制
RTT:RTT——Round Trip Time,也就是一個資料包從發出去到回來的時間,這樣發送端就大約知道需要多少的時間,
擁塞的發生是因為網路上的包太多導致路由器總是丟包,擁塞控制是快速傳輸的基礎,TCP不能忽略網路上發生的事情,而無腦地一個勁地重發資料,對網路造成更大的傷害,對此TCP的設計理念是:TCP不是一個自私的協議,當擁塞發生的時候,要做自我犧牲,就像交通阻塞一樣,每個車都應該把路讓出來,而不要再去搶路了, 一個擁塞控制演算法一般包括慢啟動演算法、擁塞避免演算法、快速重傳演算法、快速恢復演算法四部分,
慢啟動演算法
慢啟動的意思是,剛剛加入網路的連接,一點一點地提速,不要一上來就像那些特權車一樣霸道地把路占滿,新同學上高速還是要慢一點,不要把已經在高速上的秩序給搞亂了,
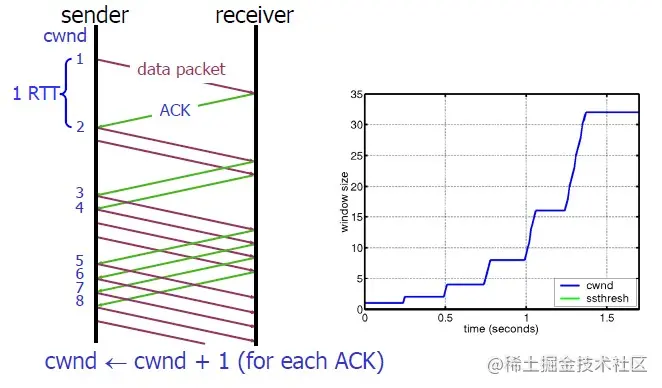
慢啟動的演算法如下(cwnd全稱Congestion Window):
1)連接建好的開始先初始化cwnd = 1,表明可以傳一個MSS大小的資料,
2)每當收到一個ACK,cwnd++; 呈線性上升
3)每當過了一個RTT,cwnd = cwnd*2; 呈指數讓升
4)還有一個ssthresh(slow start threshold),是一個上限,當cwnd >= ssthresh時,就會進入“擁塞避免演算法”
所以,我們可以看到,如果網速很快的話,ACK也會回傳得快,RTT也會短,那么,這個慢啟動就一點也不慢,下圖說明了這個程序,
擁塞避免演算法
前面說過,還有一個ssthresh(slow start threshold),是一個上限,當cwnd >= ssthresh時,就會進入“擁塞避免演算法”,一般來說ssthresh的值是65535,單位是位元組,當cwnd達到這個值時后,演算法如下:
1)收到一個ACK時,cwnd = cwnd + 1/cwnd
2)當每過一個RTT時,cwnd = cwnd + 1
這樣就可以避免增長過快導致網路擁塞,慢慢的增加調整到網路的最佳值,很明顯,是一個線性上升的演算法,
擁塞狀態時的演算法
前面我們說過,當丟包的時候,會有兩種情況:
1)等到RTO超時,重傳資料包,TCP認為這種情況太糟糕,反應也很強烈,
-
- sshthresh = cwnd /2
- cwnd 重置為 1
- 進入慢啟動程序
2)Fast Retransmit演算法,也就是在收到3個duplicate ACK時就開啟重傳,而不用等到RTO超時,
-
- TCP Tahoe的實作和RTO超時一樣,
-
-
TCP Reno的實作是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 進入快速恢復演算法——Fast Recovery
-
上面我們可以看到RTO超時后,sshthresh會變成cwnd的一半,這意味著,如果cwnd<=sshthresh時出現的丟包,那么TCP的sshthresh就會減了一半,然后等cwnd又很快地以指數級增漲爬到這個地方時,就會成慢慢的線性增漲,我們可以看到,TCP是怎么通過這種強烈地震蕩快速而小心得找到網站流量的平衡點的,
快速恢復演算法
TCP Reno
快速重傳和快速恢復演算法一般同時使用,快速恢復演算法是認為,你還有3個Duplicated Acks說明網路也不那么糟糕,所以沒有必要像RTO超時那么強烈, 注意,進入快速恢復演算法之前,cwnd 和 sshthresh已被更新:
- cwnd = cwnd /2
- sshthresh = cwnd
然后,真正的Fast Recovery演算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是確認有3個資料包被收到了)
- 重傳Duplicated ACKs指定的資料包
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就進入了擁塞避免的演算法了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/377034.html
標籤:其他
上一篇:四不幫你弄懂網路編程之最后一步