P演算法流程
一開始圖中所有的邊都默認被鎖住了,只有邊被解鎖了,才能考慮要不要這條邊,一開始圖中所有的點也都默認全部被鎖住了,只有選中了某個點,這個點才被解鎖,并且這個點的直接邊(從這個點出發的邊)也全部被解鎖,解鎖的點放入一個集合,
所以,一開始從圖中任意一點出發,在這個點的所有直接邊里選一條權值最小的邊,如果這條邊的的兩側有新結點,就解鎖這個結點;如果沒有新結點,就不要這條邊,然后新解鎖的結點的直接邊又全部被解鎖了,再在這些邊里面選權值最小的邊…周而復始,
總的來說,P演算法流程就是,先從某個點出發,解鎖一批邊,選條最小的邊解鎖一個新結點,再解鎖一批邊…
P演算法不需要用到并查集,因為總是一個點解鎖一批邊,在這一批邊里選一個點放入集合里,每次都是一個一個點進入集合,根本不存在兩大片集合要合并的問題,所以表示解鎖的點只需要一個集合就可以,當然邊的選擇還是要用到小根堆,
大家可以按照上面的思路和下面圖片來理一下思路:
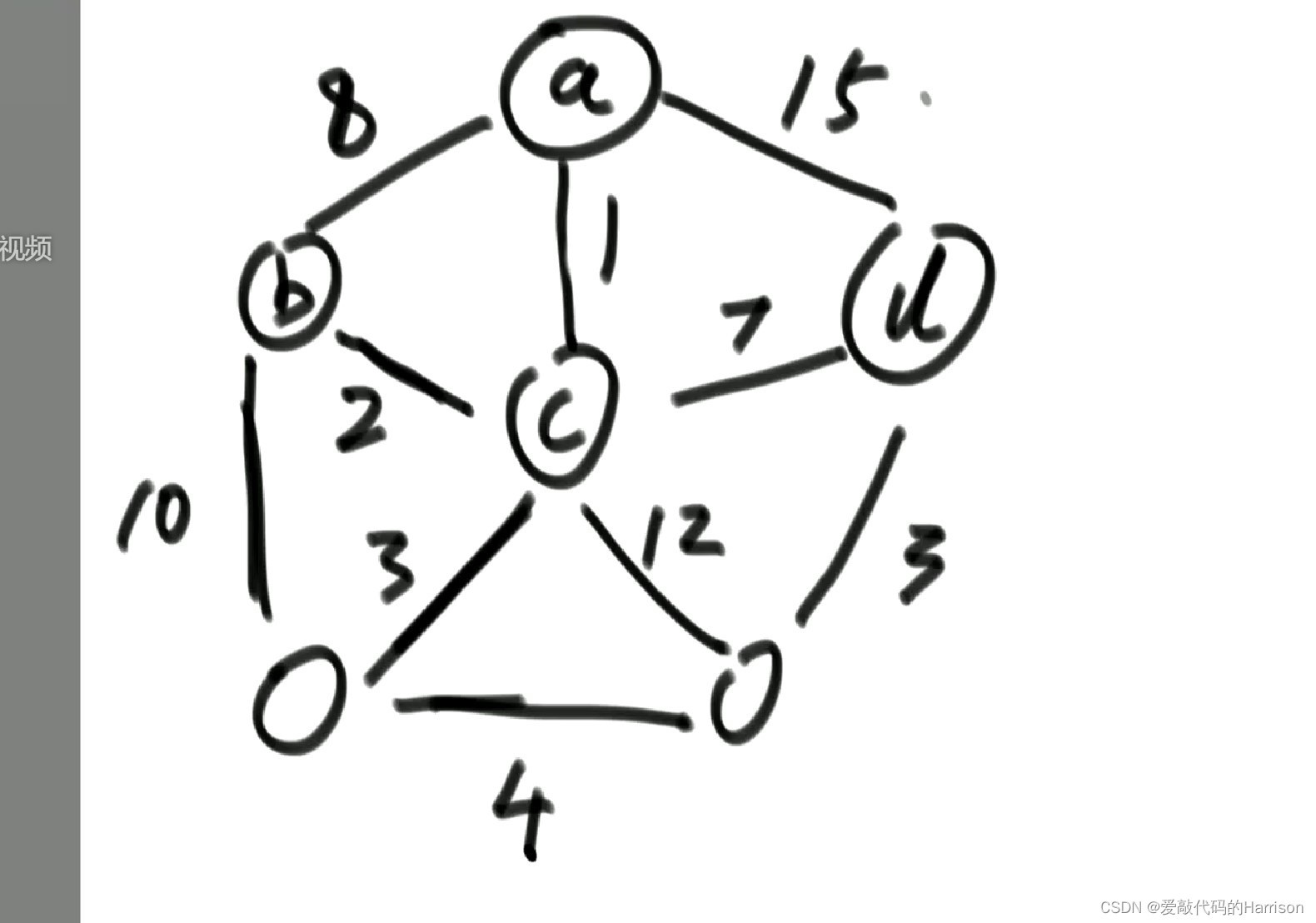
package com.harrison.class11;
import java.util.Comparator;
import java.util.HashSet;
import java.util.PriorityQueue;
import java.util.Set;
import com.harrison.class11.Code01_NodeEdgeGraph.*;
public class Code06_Prim {
public static class EdgeComparator implements Comparator<Edge>{
public int compare(Edge e1,Edge e2) {
return e1.weight-e2.weight;
}
}
public static Set<Edge> primMST(Graph graph){
// 按邊的權值組織的小根堆
PriorityQueue<Edge> pq=new PriorityQueue<>(new EdgeComparator());
// 解鎖的點放入這個集合里
HashSet<Node> nodeSet=new HashSet<>();
// 保證放入小根堆里的邊不會重復
HashSet<Edge> edgeSet=new HashSet<>();
// 選好的邊就依次放入這個集合
Set<Edge> ans=new HashSet<>();
// for回圈只是為了防止森林的出現,也可以去掉此for回圈
// 因為面試題中不會出現森林,不管有向無向
for(Node node:graph.nodes.values()) {
if(!nodeSet.contains(node)) {
nodeSet.add(node);
for(Edge edge:node.edges) {// 接下來由這個點解鎖一批邊
if(!edgeSet.contains(edge)) {
pq.add(edge);
edgeSet.add(edge);
}
}
while(!pq.isEmpty()) {
Edge edge=pq.poll();// 彈出權值最小的邊
Node toNode=edge.to;
if(!nodeSet.contains(toNode)) {
nodeSet.add(toNode);
ans.add(edge);
for(Edge nextEdge:node.edges) {
if(!edgeSet.contains(nextEdge)) {
pq.add(nextEdge);
edgeSet.add(nextEdge);
}
}
}
}
}
break;
}
return ans;
}
}
最后再總結一下:
1)隨便選一個結點解鎖,相鄰的邊也全部解鎖,然后選一條權值最小的邊
2)新解鎖的邊兩側有新結點,則把新節點給解鎖,并把新解鎖的邊考慮在最小生成樹里面;新解鎖的邊兩側沒有新結點,則不將新解鎖的邊考慮在最小生成樹里面
3)新解鎖的結點所有相鄰的邊被解鎖,已經被考慮在最小生成樹里的邊不重復解鎖,然后在所有相鄰的邊里選擇一條權值最小的邊,重復步驟 2)周而復始,一直到把所有的點都解鎖完
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/390386.html
標籤:其他