分布式架構演進
架構設計的三大目標
? 高性能、高可用、可擴展,
? 架構設計要切忌過度設計,最適合自己業務的才是最好的,并不是說大家都用分布式架構,你也要用;單體架構太low就一定不用,一個架構帶來好處的時候也一定會帶來弊端:比如將單體服務微服務化后,可以幫助實作服務的敏捷開發和部署,但是,由于將原本一體化架構的應用,拆分成了多個通過網路通信的分布式服務,為了在分布式環境下,協調多個服務正常運行,就必然引入一定的復雜度;而原本單體服務很容易做到的事務、單點登錄到了分布式架構中也會難度加倍,
單體服務
分層架構
? 軟體架構分層在軟體工程中是一種常見的設計方式,它是將整體系統拆分成 N 個層次,每個層次有獨立的職責,多個層次協同提供完整的功能,
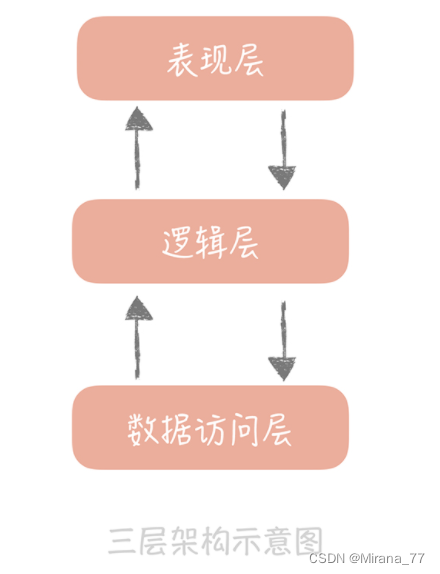
三層架構
? 一種常見的分層方式是將整體架構分為表現層、邏輯層和資料訪問層:
- 表現層,顧名思義嘛,就是展示資料結果和接受用戶指令的,是最靠近用戶的一層;
- 邏輯層里面有復雜業務的具體實作;
- 資料訪問層則是主要處理和存盤之間的互動,
這是在架構上最簡單的一種分層方式,其實,我們在不經意間已經按照三層架構來做系統分層設計了,比如在構建專案的時候,我們通常會建立三個目錄:Web、Service 和 Dao,它們分別對應了表現層、邏輯層還有資料訪問層,
MVC
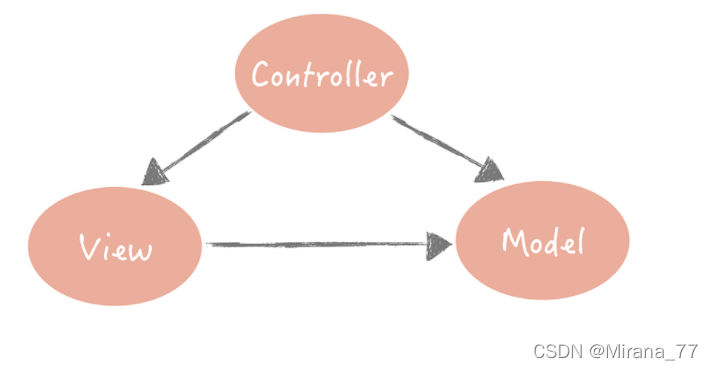
? 還有一種軟體分層架構是MVC(Model-View-Controller)架構,它將整體的系統分成了 Model(模型),View(視圖)和 Controller(控制器)三個層次,也就是將用戶視圖和業務處理隔離開,并且通過控制器連接起來,很好地實作了表現和邏輯的解耦,是一種標準的軟體分層架構,
分層架構的優勢
-
分層的設計可以簡化系統設計,讓不同的人專注做某一層次的事情,
-
**再有,分層之后可以做到很高的復用,**比如,我們在設計系統 A 的時候,發現某一層具有一定的通用性,那么我們可以把它抽取獨立出來,在設計系統 B 的時候使用起來,這樣可以減少研發周期,提升研發的效率,
-
**最后一點,分層架構可以讓我們更容易做橫向擴展,**如果系統沒有分層,當流量增加時我們需要針對整體系統來做擴展,但是,如果我們按照上面提到的三層架構將系統分層后,那么我們就可以針對具體的問題來做細致的擴展,比如說,業務邏輯里面包含有比較復雜的計算,導致 CPU 成為性能的瓶頸,那這樣就可以把邏輯層單獨抽取出來獨立部署,然后只對邏輯層來做擴展,這相比于針對整體系統擴展所付出的代價就要小的多了,
-
橫向擴展是高并發系統設計的常用方法之一,既然分層的架構可以為橫向擴展提供便捷, 那么支撐高并發的系統一定是分層的系統,
分層架構的劣勢
- 它最主要的一個缺陷就是增加了代碼的復雜度,
- 如果我們把每個層次獨立部署,層次間通過網路來互動,那么多層的架構在性能上會有損耗,這也是為什么服務化架構性能要比單體架構略差的原因,也就是所謂的“多一跳”問題,
架構的演進
? 假設有一天突然領導讓你去開發一個電商系統,很急很關鍵,讓你最好三天搞完上線,那這個時候你可能會采用最簡單的架構:三層架構+一臺資料庫服務器存盤業務資料完事兒,
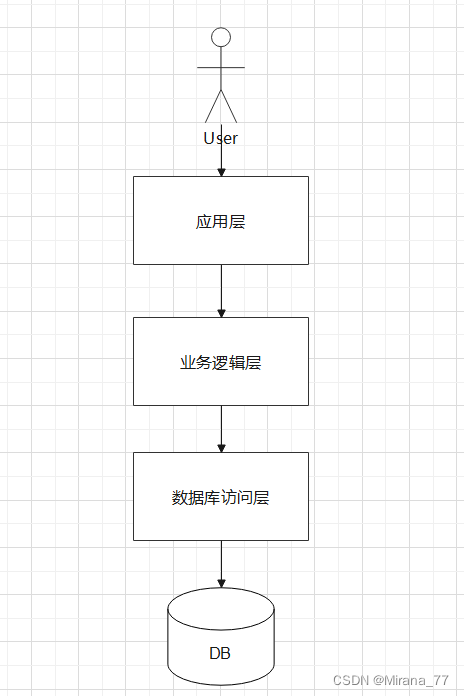
在系統開發的初期,這種架構確實給你的開發運維,帶來了很大的便捷,主要體現在:
- 開發簡單直接,代碼和專案集中式管理;
- 只需要維護一個工程,節省維護系統運行的人力成本;
- 排查問題的時候,只需要排查這個應用行程就可以了,目標性強,
資料庫
我們先看一份常用系統操作回應時間的統計資料:
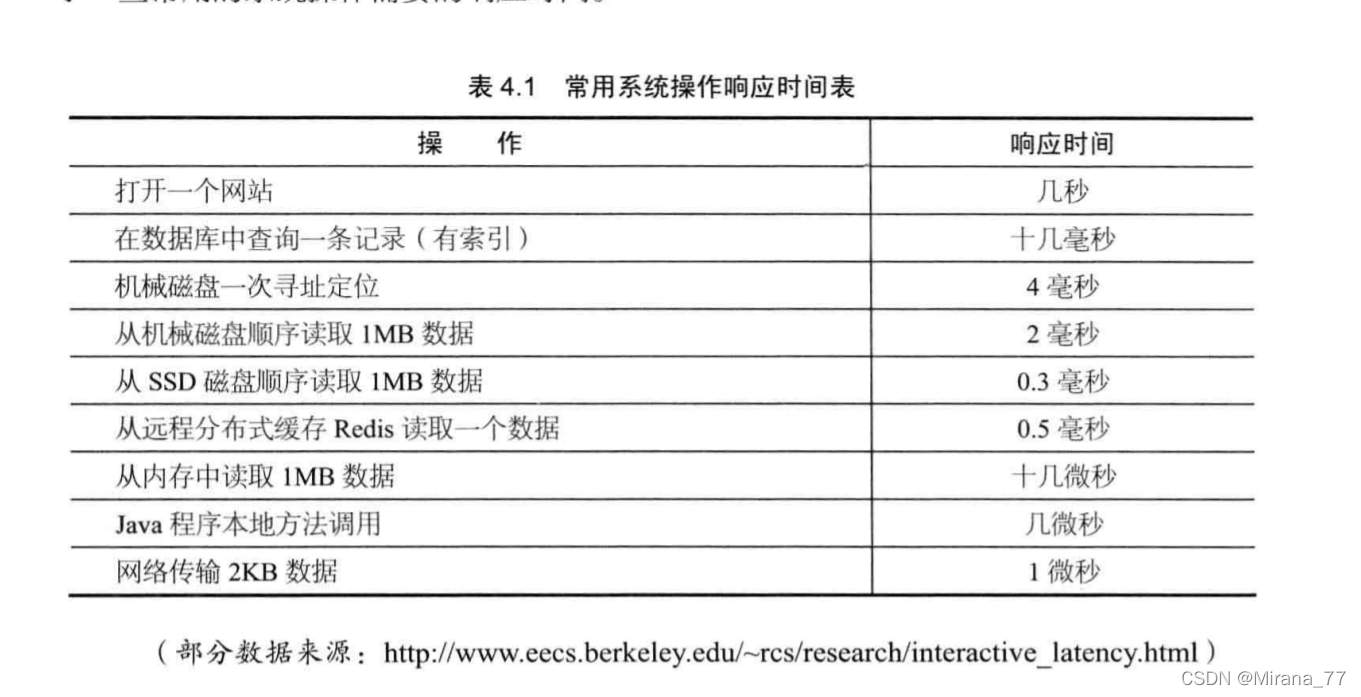
這樣資料庫很容易就成為我們的系統的瓶頸,畢竟在有索引的情況下,資料庫查詢也要在十幾ms,而資料庫的優化又可以分為幾部分:
-
系統慢的原因出現在和資料庫的互動上?——可以通過“池化”的思想來解決,
-
業務是否是讀多寫少?——讀寫分離
-
隨著系統逐漸發展,資料庫中存盤的資料也越來越多,單個表的資料量超過了千萬甚至到了億級別,這時即使你使用了索引,索引占用的空間也隨著資料量的增長而增大,資料庫就無法快取全量的索引資訊,那么就需要從磁盤上讀取索引資料,就會影響到查詢的性能了——分庫分表:
? 按照業務型別來拆分——垂直拆分
? 將單一資料表按照某一種規則拆分到多個資料庫和多個資料表中,比如按照時間——水平拆分
微服務化
分庫分表后,你的系統可能是長這個樣子:
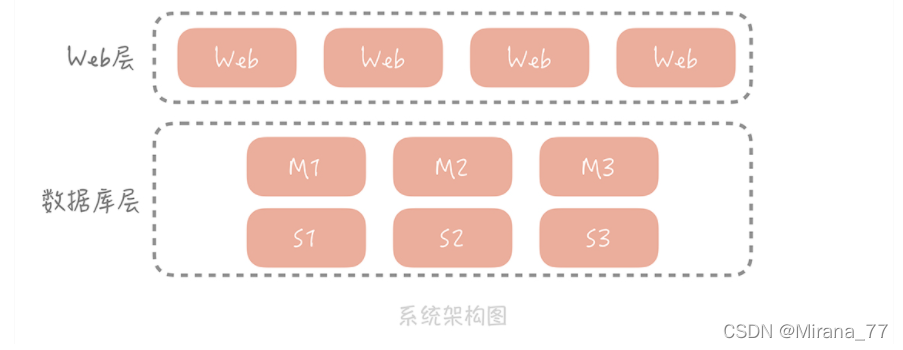
? 從整體上看,資料庫分了主庫和從庫,資料也被切分到多個資料庫節點上,但是你的工程的部署方式還是采用一體化架構,也就是說所有的功能模塊,比方說電商系統中的訂單模塊、用戶模塊、支付模塊、物流模塊等等,都被打包到一個大的 Web 工程 中,然后部署在應用服務器上,但隨著業務量的增加,單體架構的劣勢逐漸體現出來:
-
首先,在技術層面上,資料庫連接數可能成為系統的瓶頸
? 資料庫的連接是比較重的一類資源,不僅連接程序比較耗時,而且連接 MySQL 的客戶端數量有限制,最多可以設定為 16384(在實際的專案中,可以依據 實際業務來調整),
? 這個數字看著很大,但是因為你的系統是按照一體化架構部署的,在部署結構上沒有分層, 應用服務器直接連接資料庫,那么當前端請求量增加,部署的應用服務器擴容,資料庫的連 接數也會大增,給你舉個例子, 我之前維護的一個系統中,資料庫的最大連接數設定為 8000,應用服務器部署在虛擬機 上,數量大概是 50 個,每個服務器會和資料庫建立 30 個連接,但是資料庫的連接數,卻 遠遠大于 30 * 50 = 1500,因為你不僅要支撐來自客戶端的外網流量,還要部署單獨的應用服務,支撐來自其它部門的 內網呼叫,也要部署佇列處理機,處理來自訊息佇列的訊息,這些服務也都是與資料庫直接 連接的,林林總總加起來,在高峰期的時候,資料庫的連接數要接近 3400,
? 所以,一旦遇到一些大的運營推廣活動,服務器就要擴容,資料庫連接數也隨之增加,基本 上就會處在最大連接數的邊緣,這就像一顆定時炸彈,隨時都會影響服務的穩定,
-
第二點,一體化架構增加了研發的成本,抑制了研發效率的提升,由于代碼部署在一起,每個人都向同一個代碼庫提交代碼,代碼沖突無法避免;同時,功能之間耦合嚴重,可能你只是更改了很小的邏輯,卻導致其它功能不可用,從而在測驗時需要對整體功能回歸,延長了交付時間,模塊之間互相依賴,一個小團隊中的成員犯了一個錯誤,就可能會影響到,其它團隊維護的服務,對于整體系統穩定性影響很大,
-
第三點,一體化架構對于系統的運維也會有很大的影響,想象一下,在專案初期,你的代碼可能只有幾千行,構建一次只需要一分鐘,那么你可以很 敏捷靈活地頻繁上線變更修復問題,但是當你的系統擴充到幾十萬行,甚至上百萬行代碼的 時候,一次構建的程序,包括編譯、單元測驗、打包和上傳到正式環境,花費的時間可能達 到十幾分鐘,并且,任何小的修改,都需要構建整個專案,上線變更的程序非常不靈活,
微服務化的拆分
? 隨著業務的擴增,我們會發現我們的工程可以按照業務維度做垂直拆分,但是僅僅是對工程做拆分是不夠的,試想一下我們有一個社交系統,用戶注冊了之后可以在好友圈發送訊息,然后關注他的人都可以看到,如果這個時候我們僅僅是對工程做拆分,把與用戶相關的邏輯,部署成一個單獨的服務,但是無論是內容還是互動,都會查詢用戶庫獲取用戶資料,所以,即使我們做了業務池的拆分,但實際上,每一個業務池子都需要連 接用戶庫,并且請求量都很大,這就造成了用戶庫的連接數比其它都要多一些,容易成為系統的瓶頸,所以,我們需要按照業務的維度同時拆分工程跟資料庫,
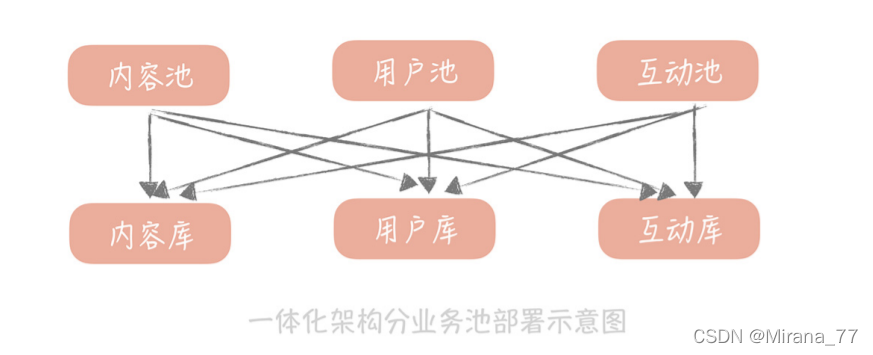
? 通過按照業務做橫向拆分的方式,解決資料庫層面的擴展性問題:
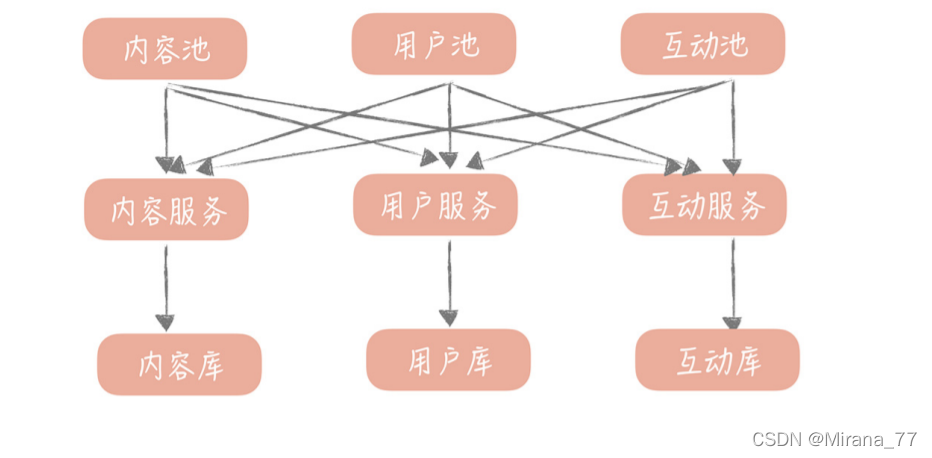
? 再比如,我們在做社區業務的時候,會有多個模塊需要使用地理位置服務,將 IP 資訊或者經緯度資訊,轉換為城市資訊,比如,推薦內容的時候,可以結合用戶的城市資訊,做附近 內容的推薦;展示內容資訊的時候,也需要展示城市資訊等等,
? 那么,如果每一個模塊都實作這么一套邏輯就會導致代碼不夠重用,因此,我們可以把將 IP 資訊或者經緯度資訊,轉換為城市資訊,包裝成單獨的服務供其它模塊呼叫,也就是, 我們可以將與業務無關的公用服務抽取出來,下沉成單獨的服務,
? 按照以上兩種拆分方式將系統拆分之后,每一個服務的功能內聚,維護人員職責明確,增加 了新的功能只需要測驗自己的服務就可以了,而一旦服務出了問題,也可以通過服務熔斷、 降級的方式減少對于其他服務的影響,
? 另外,由于每個服務都只是原有系統的子集,代碼行數相比原有系統要小很多,構建速度上 也會有比較大的提升,
? 我們可以通過DDD:領域驅動設計來幫助我們做從業務層面,對我們的工程做微服務拆分,
晚點會對這部分做詳細總結整理
快取
? 但是僅僅是將工程微服務化還不夠,隨著并發的增加,存盤資料量的增多,資料庫的磁盤 IO 逐漸成了系統的瓶頸,我們需要一種訪問更快的組件來降低請求回應時間,提升整體系統性能,而這個時候我們可以通過多級快取配合使用,比如:
- ? 在負載均衡層使用靜態快取
- ? 在應用層和資料庫層之間,可以借助快取中間件實作分布式快取,例如Redis、Memcache、Mongodb等
- ? 在應用層使用本地快取
我們需要將請求盡量擋在上層,因為越往下層,對于并發的承受能力越差,
使用了快取那就要考慮資料一致性:
- ? 分布式快取——Cache Aside(旁路快取)策略
- ? 本地快取——Read/Write Through(讀穿 / 寫穿)策略
同時,也要考慮快取會遇到的問題:
- ? 快取擊穿
- ? 快取穿透
- ? 快取雪崩
訊息佇列
? 在加上快取之后,隨著業務的發展,你可能會遇到一些存在高并發寫請求的場景,或者可以異步處理的場景,這個時候就要考慮使用訊息佇列,
? 訊息佇列的幾個主要作用:
- 解耦
- 異步
- 削峰填谷
? 既然要使用訊息佇列,那就要考慮選型:
- RabbitMQ
- RocketMq
- Kafka
? 但是使用訊息佇列也會碰到一些問題,比如為了保證訊息一定會被發送到,訊息至少會被發送一次,那如何保證產生的訊息一定會被消費到,并且只被消費一次呢?
- 訊息的可靠性保證
- 訊息的冪等性處理
? 還有另外一個問題:單體架構中,我們可以使用事務來保證對資料庫中的一組資料進行操作的同時成功或者同時失敗,那我們怎么保證本地事務與訊息佇列發送/消費訊息的事務性?——訊息的事務處理
分布式架構的問題
? 現在我們對單體架構按照業務進行了拆分,同時又加上了快取來提高性能,使用訊息佇列來幫助幫助我們的工程抗住更高的并發:
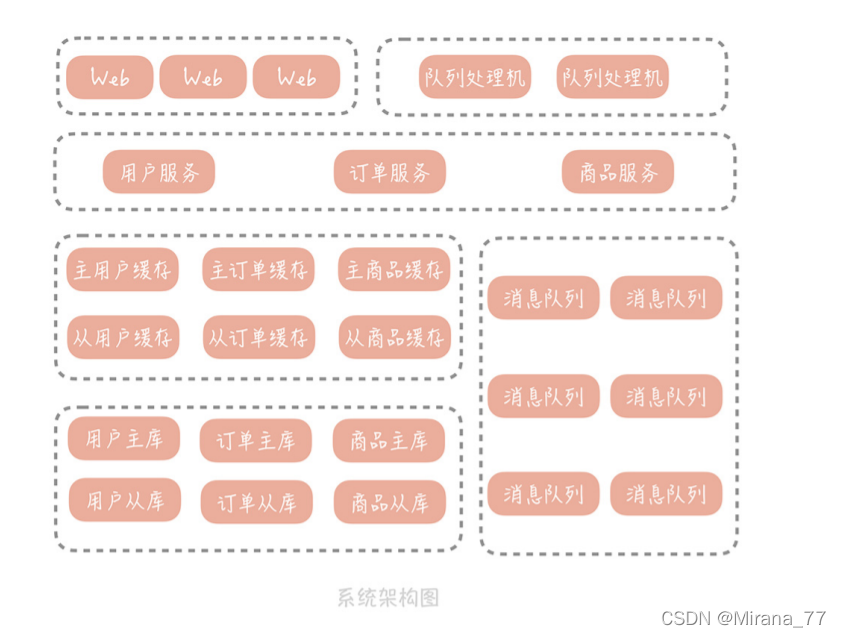
? 那接下來又會冒出來一系列因分布式集群架構帶來的問題:
- ? 我們的服務是基于分布式集群來實作部署的,如何保證一些共享資源的原子性?——分布式鎖
- ? 分布式集群架構如何實作單點登錄?——分布式會話
- ? 如何保證不同資源服務器的資料一致性?——分布式事務
- ? 服務跨網路怎么通信?——分布式通信
- ? 服務跨網路之后怎么感知對方的地址互相呼叫?——注冊中心
- ? 如何將訪問的請求“均衡”地分配到多個處理節點上?——負載均衡
- ? 如何將一些服務共有的功能整合在一起,獨立部署為單獨的一層,用來解決一些服務治理的問題?——API網關
- ? 如何防止微服務的雪崩效應?——熔斷、降級處理
- ? 微服務化后,如何定位問題?——鏈路追蹤
- ? 微服務化后,如何生成唯一主鍵?——分布式全域ID
? 當然問題不止這么些,還有應用監控與調優、容器化部署等等方面,慢慢整理吧~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/391427.html
標籤:其他
上一篇:分布式調度架構:兩層調度
下一篇:VLAN虛擬局域網