💖作者簡介:大家好,我是車神哥,府學路18號的車神🥇
?About—>車神:從寢室到實驗室最快3分鐘,最慢3分半(那半分鐘其實是等紅綠燈)
📝個人主頁:應無所住而生其心的博客_府學路18號車神_CSDN博客
🥇 官方認證:人工智能領域新星創作者
🎉點贊?評論?收藏 == 養成習慣(一鍵三連)😋?希望大家多多支持🤗~一起加油 😁
專欄
《Golang · 過關斬將》
《Neural Network》
《微信小程式開發》
《LeetCode天梯》
《Algorithm》
《Python》
《web》
Borderline-SMOTE演算法
- 🎉Borderline-SMOTE演算法介紹
- 🤗源代碼
最近寫畢業課題論文,用到了Borderline-SMOTE演算法,做故障診斷,其實實際工況中包含了很多的資料,而且監測周期極其不均勻,有的檢測時間是按照月來采樣,有的則是按照年,還有日度,實時等等,在很多地方是不平衡的資料,由此我們需要產生更多相似的資料,一般的虛擬樣本生成技術有很多:蒙特卡洛法、整體趨勢擴散技術、SMOTE、DNN、Bootstrap等等很多很多,由于最近用Borderline-SMOTE比較多,下面介紹一下!~
文末Python源代碼自取!!!
🎉Borderline-SMOTE演算法介紹
Borderline SMOTE是在SMOTE基礎上改進的過采樣演算法,該演算法僅使用邊界上的少數類樣本來合成新樣本,從而改善樣本的類別分布,
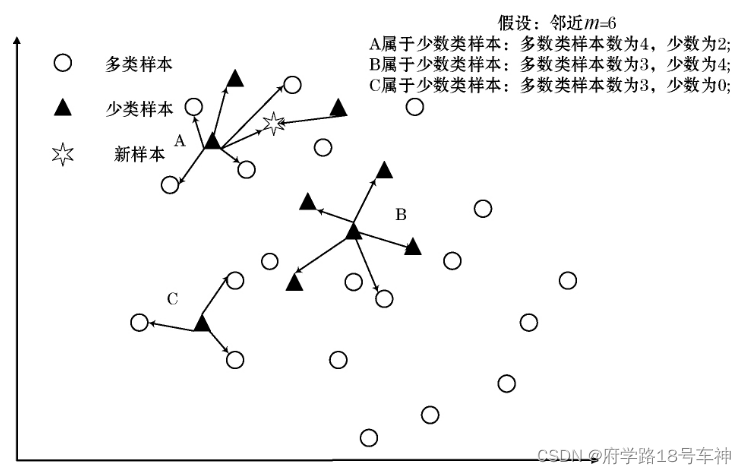
Smote 演算法仍屬于是建立在相距較近的少類樣本之間樣本的假設基礎之上,還沒有充分考慮鄰近樣本 的分布特點,會造成類間發生重復性的可能性較大,而 采用識別少類種子樣本的 Borderline-Somte 演算法可以 避免這種重復性的發生,基于邊界上樣本的合成樣本原理如下圖所示,
Borderline SMOTE采樣程序是將少數類樣本分為3類,分別為Safe、Danger和Noise,最后,僅對表為Danger的少數類樣本過采樣,
Borderline-SMOTE又可分為Borderline-SMOTE1和Borderline-SMOTE2,Borderline-SMOTE1在對Danger點生成新樣本時,在K近鄰隨機選擇少數類樣本(與SMOTE相同),Borderline-SMOTE2則是在k近鄰中的任意一個樣本(不關注樣本類別)
假設
S
S
S為樣本集,
S
m
i
n
S_{min}
Smin? 為少類樣本集,
S
m
a
x
j
S_{maxj}
Smaxj?的多數樣本集,m 為鄰近樣本個數,
x
i
x_i
xi? 屬性,
x
i
j
x_{ij}
xij?為鄰近樣本全部屬性,
x
n
x_n
xn? 為近鄰樣本,
R
i
j
R_{ij}
Rij? 取值0.5或1,合成演算法步驟如下,
- Step1:假設每一個 x i ∈ S m i n x_i \in S_{min} xi?∈Smin?,確定與其最鄰近的樣本集,其資料集為 S N N S_{NN} SNN?,且 S N N ∈ S S_{NN} \in S SNN?∈S.
- Step:對每一個樣本 x i x_i xi?,判斷最近鄰屬于多數樣本集的個數,即 ∣ S N N ∩ S m a x j ∣ < m | S_{NN} \cap S_{maxj}| < m ∣SNN?∩Smaxj?∣<m;合成少數類的樣本,即 x i x_i xi?與近鄰得出 x n x_n xn?對應屬性 j j j中的差值記為 d i j = x i ? x i j d_{ij}=x_{i}-x_{ij} dij?=xi??xij?,得出合成新的少數類樣本 h i j = x i + d i j × r a n d ( 0 , R i j ) h_{ij}=x_i+d_{ij} \times rand(0, R_{ij}) hij?=xi?+dij?×rand(0,Rij?),
與 SMOTE 方法相比,Borderline-SMOTE 方法只針對邊界樣本進行近鄰線性插值,使得合成后的少數 類樣本分布更為合理.
哇,好久沒有在Markdown手敲公式了,都有點手生了,哈哈哈,
🤗源代碼
Python代碼:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/28 10:49
# @Author : 府學路18號車神
# @Email :yurz_control@163.com
# @File : Borderline-SMOTE_imblearn.py
from collections import Counter
import numpy as np
import pandas as pd
from icecream import ic
from sklearn.datasets import make_classification
from imblearn.over_sampling import BorderlineSMOTE
import random
from sklearn.neighbors import NearestNeighbors
# 讀取資料
def loaddata(filename):
df = pd.read_excel(io=filename)
# ic(df)
return np.array(df)
# 均勻的100個資料
def gene_data(Lb, Ub):
# 生成LB
# 回圈取值獲得Lb和Ub的值
m = Lb.shape[0]
gene_box = []
for i in range(m):
gene_sample = np.linspace(Lb[i], Ub[i], 100)
# ic(gene_sample)
gene_box.append(gene_sample)
return gene_box
class Smote:
def __init__(self,samples,N=10,k=5):
self.n_samples,self.n_attrs=samples.shape
self.N=N
self.k=k
self.samples=samples
self.newindex=0
# self.synthetic=np.zeros((self.n_samples*N,self.n_attrs))
def over_sampling(self):
N=int(self.N/100)
self.synthetic = np.zeros((self.n_samples * N, self.n_attrs))
neighbors=NearestNeighbors(n_neighbors=self.k).fit(self.samples)
print('neighbors',neighbors)
for i in range(len(self.samples)):
nnarray=neighbors.kneighbors(self.samples[i].reshape(1,-1),return_distance=False)[0]
#print nnarray
self._populate(N,i,nnarray)
return self.synthetic
# for each minority class samples,choose N of the k nearest neighbors and generate N synthetic samples.
def _populate(self,N,i,nnarray):
for j in range(N):
nn=random.randint(0,self.k-1)
dif=self.samples[nnarray[nn]]-self.samples[i]
gap=random.random()
self.synthetic[self.newindex]=self.samples[i]+gap*dif
self.newindex+=1
if __name__ == '__main__':
# 讀取資料
datafile = "LbUbCL邊界.xlsx"
df = loaddata(datafile)
df_LB = df[:, 2]
df_UB = df[:, 3]
# ic(df_LB, df_UB)
# ic(df_LB.shape, df_UB.shape)
# 在LB和UB區間內生成均勻的100個資料,然后再用borderline-SMOTE進行虛擬樣本生成
Initial_dt = np.array(gene_data(df_LB, df_UB))
X = Initial_dt.T
ic((Initial_dt.T).shape) # success
# 相應的標簽y
y = np.array([1]*100)
# y = np.ones((16, 100))
# ic(y)
# print('Original dataset shape %s' % Counter(y))
# 對生成的100個樣本使用borderline-SMOTE生成虛擬樣本
# sm = BorderlineSMOTE(random_state=42, kind="borderline-1")
# X_res, y_res = sm.fit_resample(X, y)
# print('Resampled dataset shape %s' % Counter(y_res))
# ic(X_res, y_res)
ss = Smote(X, N=100)
res = ss.over_sampling()
pd.DataFrame(res).to_excel("Borderline-SMOTE_result.xlsx")
print(res)
"""-----------------------------------------------------------"""
# print('Original dataset shape %s' % Counter(y))
# sm = BorderlineSMOTE(random_state=42, kind="borderline-1")
# X_res, y_res = sm.fit_resample(X, y)
# print('Resampled dataset shape %s' % Counter(y_res))
# icecream.ic(X_res, y_res.shape)
# X1, y1 = make_classification(n_classes=2, class_sep=2,
# weights=[0.1, 0.9], n_informative=2, n_redundant=0, flip_y=0,
# n_features=2, n_clusters_per_class=1, n_samples=100, random_state=9)
# ic(X1, y1)
注意,由于我們的資料集是我的論文資料集,所以不能分析給大家啦!~
下面還有一個畫圖的代碼也一起附上吧,僅供參考:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/28 21:35
# @Author : 府學路18號車神
# @Email :yurz_control@163.com
# @File : plot.py
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pylab import mpl, text
from matplotlib.font_manager import FontProperties
roman = FontProperties(fname=r'C:\Windows\Fonts\Times New Roman.ttf', size=10) # Times new roman
mpl.rcParams['font.sans-serif'] = ['SimSun']
fontcn = {'family': 'SimSun','size': 10} # 1pt = 4/3px
fonten = {'family':'Times New Roman','size': 10}
df = pd.read_excel("SMAPE_final.xlsx", sheet_name="Sheet2")
df2 = pd.read_excel("SMAPE_final.xlsx", sheet_name="Sheet4")
print(df)
t1 = list(df2.iloc[0, 1:])
t2 = list(df2.iloc[1, 1:])
t3 = list(df2.iloc[2, 1:])
# X2 = ["MTD(%)", "MT-MTD(%)", "MD-MTDB(%)"]
X2 = ['10', '15', '20', '25', '&']
plt.plot(X2, t1, linestyle="-.", marker="o", linewidth=2, label="MTD", markersize='8')
plt.plot(X2, t2, "-D", linewidth=2, label="MT-MTD", markersize='8')
plt.plot(X2, t3, "--v",linewidth=2, label="MD-MTDB", markersize='8')
plt.xlabel("Size of Sample", fontsize=15)
plt.ylabel("AveSMAPE(%)", fontsize=15)
plt.rcParams.update({'font.size':14})
plt.legend()
plt.show()
y1 = list(df.iloc[0, 1:])
y2 = list(df.iloc[1, 1:])
y3 = list(df.iloc[2, 1:])
X = ['10', '15', '20', '25', '30']
plt.plot(X, y1, '--o', linewidth=2, label='SMAPE no vitual samples', markersize='8')
plt.plot(X, y2, '-^', linewidth=2, label='SMAPE include vitual samples', markersize='8')
plt.xlabel("Size of Sample", fontsize=15)
plt.ylabel("AveSMAPE(%)", fontsize=15)
plt.rcParams.update({'font.size':14})
plt.legend()
plt.show()
# plt.subplot(211)
plt.bar(X, y3, width=0.8)
plt.xlabel("Size of Sample", fontsize=15)
plt.ylabel("AvePCR(%)", fontsize=15)
plt.show()
加油吧!~準備卷畢業課題第三章了,o(╥﹏╥)o

?堅持讀Paper,堅持做筆記,堅持學習,堅持刷力扣LeetCode?!!!
堅持刷題!!!打天梯!!!
?To Be No.1??哈哈哈哈
?創作不易?,過路能?關注、收藏、點個贊?三連就最好不過了
?( ′・?・` )
?
『
萬事開頭難,然后中間難,最后結尾難,
』
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/398451.html
標籤:其他