公司簡介
北京金海樂游軟體有限公司是一家以計算機軟體架構開發為核心,實施計算機軟硬體系統集成的現代科技企業,我司從事交通運輸行業系統軟體研發,技術覆寫且不限于 JAVA Spring框架(可選技術框架:C/C++、Python、Go)行業業務邏輯實作、TransCAD\TransModeler\超圖\Arcgis等商業軟體的二次開發和演算法實作、大資料分析及資料中臺、 交通資產管理,
作者資訊
王揚 北京金海樂游軟體有限公司 技術主管
專案背景
某市級管理單位為了強化全市交通運輸管理,統籌綜合交通發展,提升交通運行和管理效率,建立了大交通資料資源管理系統及相關應用 “一圖一庫”,其中“一庫”部分主要內容包括:資料接入,資料存盤,資料共享;“一圖”部分主要內容包括:GIS資訊及其關聯資料資訊在二維、三維地圖上的形象表達,
該大交通資料資源管理系統本質是為某市交通運輸行業建設高效可用的行業資料中臺系統,其基本架構如下:
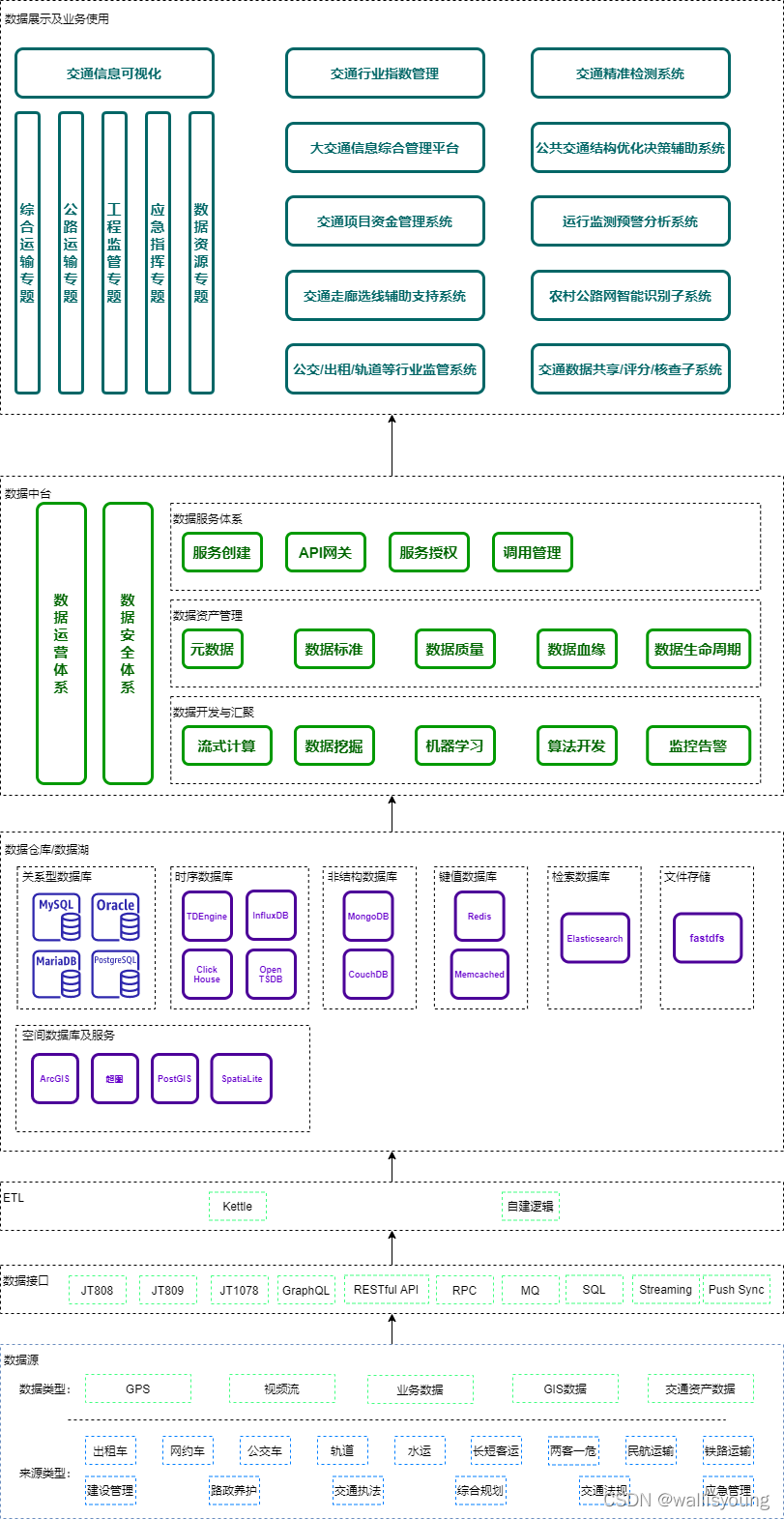
我們的需要
在交通運輸行業的資料中臺建設中,存在大量的時序資料應用場景,其中最為關鍵的就是車輛運行時序資料的存盤與使用,如下圖所示,綜合交通運行監測系統中,GPS時序資料是及其重要的資料資源:
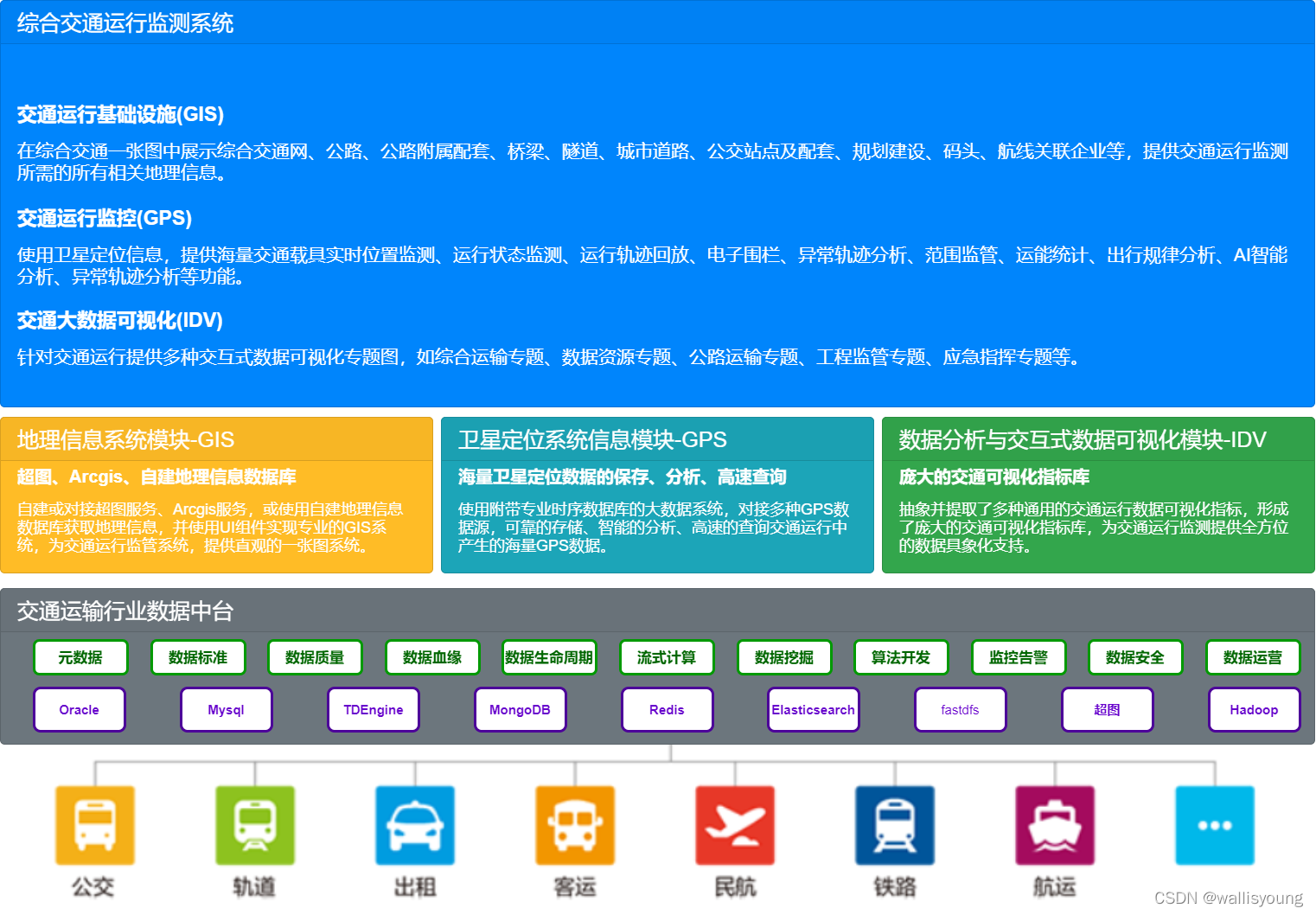
由出租車、網約車、公交車、軌道、水運、長短客運、兩客一危、鐵路運輸的車輛船舶實時上傳運行相關資料,均具備時序資料的特征,每日的入庫資料量輕松突破億級大關,一線城市或省級區域的車輛船舶運行資料甚至可達到數億甚至數十級別,如何高效的將時序類資料入庫成為交通運輸行業資料中臺的一個核心訴求,
交通運輸行業資訊化業務中有對于車輛的實時位置高效查詢的核心訴求,舉一個典型的用例,用戶需要頻繁獲得當日上線車船(數萬至數十萬)的數量、最終位置資訊、營業額度等資訊,此種型別的查詢需要高效的回傳結果集(萬級車船查詢須在秒級),并且,用戶隨著資訊化的行程,頻繁的出現各種新的時序資料查詢需求,需要快速高效的實作與部署,
由于交通行業的資料的重要性和敏感性,資料存盤的可靠性、可擴張性是極為重要的核心訴求,
為何是TDengine?
選型初始,我們考慮的了三個資料庫物件,他們分別是InfluxDB、ClickHouse和TDengine,
- InfluxDB:成熟的老牌時序資料庫,但是重要的集群功能需要商業版本,考慮到國外商業軟體的特殊性質,從審批到付款以及后續安全性,都存在風險,
- ClickHouse:俄羅斯開發的高性能資料庫,主要問題在于開源社區主要以俄語為主,其非標準化SQL的學習成本較高、集群維護成本高,
- TDengine:國產化資料庫、中文開源社區,極佳的寫入速度,便于維護的集群架構這三點原因最終促使我們選擇TDengine作為我們專案的時序資料庫,
參考選型文章:
- TDengine Testing Report
- System Properties Comparison ClickHouse vs. InfluxDB vs. TDengine
落地程序
集群架構落地
使用5臺服務器搭建TDengine的dnode集群,mnode與資料庫的副本數均設定為3,
在集群的設定初期,由于當前版本mnode個數的預設值由之前的3個變更成為了1個,系統mnode最初沒有副本,使用以下的方法進行安全的重啟維護,將mnode總數升級為3個,此方法由官方社群中提供的TDengine集群版升級步驟變更而來:
0.確保集群節點狀態正常(show dnodes;),讀寫無問題,
1.在所有節點停止資料庫服務systemctl stop taosd
2.備份資料檔案目錄下的所有內容 到資料檔案目錄之外,
3.分別cd進入各個節點的資料檔案目錄
4.tree命令檢查所有vnode目錄下的wal目錄是否為空
5.如果為空,進入步驟7
6.如果非空,啟動資料庫行程,再關閉,直到wal全部為空,
7.在資料庫服務taosd停止的狀態下,分別在所有節點修改組態檔,將numOfMnodes的值設為3,
8.分別啟動所有節點的taosd服務,systemctl start taosd,
9.show dnodes檢查節點狀態
10.檢查資料,
資料寫入架構落地
由于我們的業務開發框架使用的是Srping框架,在使用TAOS-JDBCDriver進行開發時,可以選擇兩種方式進行資料入庫,JDBC-JNI方式 或者是JDBC-RESTful方式,在TAOS官網,明確記載了“JDBC-RESTful 性能是 JDBC-JNI 的 50%~90%”,所以,我們選擇了JDBC-JNI方式進行多執行緒入庫,
在JDBC-JNI方式中,依然有兩種實作方式,在資料庫連接池(Hikari、druid)的基礎上,原生SQL執行寫入或者是使用ORM框架(MyBatis等)執行寫入,在設計試運行初期,我們使用了ORM框架進行資料寫入,在當前的資料寫入量之下,并沒有太大的問題,但是,參考濤思資料副總肖波在社區群中溝通中的話:“ORM框架大多數面向關系庫開發場景的,每秒幾萬的吞吐量對它們來說就很大了,但時序寫入場景里,這連塞牙縫都不夠,設計滿足的應用場景不同原因導致它們不適合,但查詢影響不大”,我們認識到ORM框架本身可能存在性能瓶頸,因此在未來的版本中,我們使用了資料庫連接池(Hikari、druid)+原生SQL執行寫入為主要寫入模式,
寫入效果
專案的目標寫入量為1億條/天,每秒鐘寫入1158條左右,我們通過TDengine自帶的log功能進行分析,確認寫入效率,由下圖可以看出,五節點構成的集群中,目前瞬時寫入能力取不精確的最大值,也就是dn1節點的23107條,log.dn表中資料采集的周期是30秒,由此可知,dn1的實測瞬時最大寫入量是770條/秒,加之五節點的集群在分布式插入的架構下,770*5=3850條/秒的資料插入效率是完全可以保障的,完全滿足了我們業務需求,至于本集群的插入性能上限,應在此實測值的100倍以上,并且有極大的增長空間,
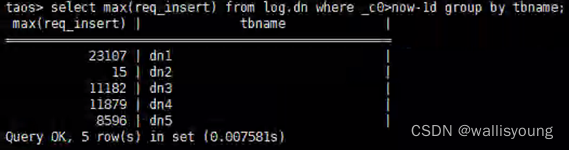
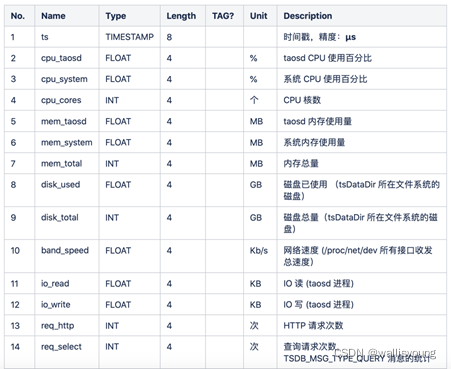
這里說明一下log.dn表是及其重要的一張TDengine自帶的運行狀態資料表,我們可以通過此表對TDengine的運行狀態進行監視,后面在查詢資源占用情況的時候,我們還會用到這張表,log表欄位的說明如下圖:(據官方社區作業人員表示,后面新版本的TDinsight是更好的監控工具,有機會打算試用一下)

查詢效果
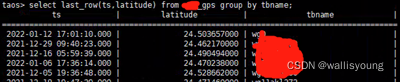
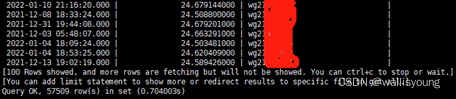
所有車輛最新位置資訊的查詢,這個查詢是交通運行監控中的重中之重,在最初,使用何種查詢陳述句實作高效查詢極大的困擾了我們,在TDengine社區團隊的幫助下,我們利用了隱藏欄位名tbname和group by方法,高效的查詢了車輛的最新定位資訊,從下圖中我們可以看到,頻繁查詢的情況下,接近六萬輛車的位置資訊,只需要不到1秒的查詢時間,簡單而又高效,完全符合我們的業務需求:
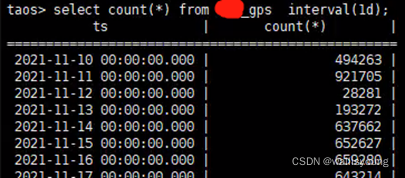
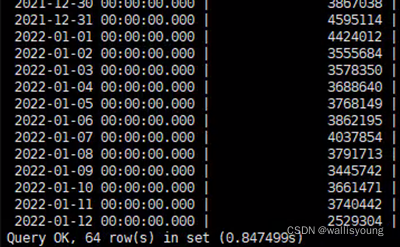
資料統計分析也是各種業務系統中需要廣泛實裝的一個功能,我們再看一個例子,一個64天資料量的表,進行每日資料條數的降維統計,所需時間也是不到1秒:
在合理的SQL設計支持之下,TDengine的查詢效率完全可以滿足時序類資料的高效查詢需求,大大簡化了開發難度,降低了運維成本,整個團隊都感到滿意,
資源占用
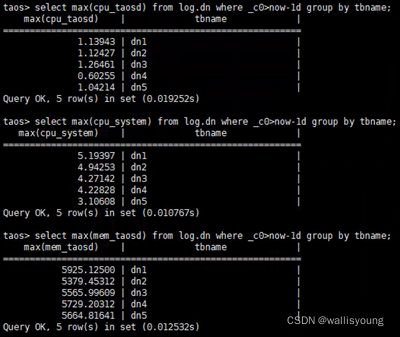
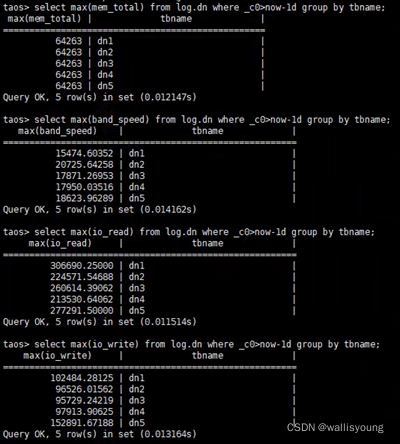
看圖說話,圖中羅列了一日內各個節點的CPU、記憶體、帶寬、IO讀寫的相關資料(最大采樣值),其資源消耗尤其是CPU方面的消耗是及其穩定和可控的:
結語
TDengine在本次開發中展現出的性能效果非常顯著,推動了交通行業海量時序資料業務快速高質的落地,大大的降低了開發與運維成本,對于國貨精品的TDengine,我們愿意付出更多的耐心與信心,甚至愿意參加到開源社區的開發活動中去,建立一個良好的社區生態,
對于TDengine產品本身,我們也有更多的期許:
- 在目前的高迭代開發期,尤其是對集群客戶,提供不間斷服務的無縫升級功能,
- 建議TDengine開展培訓、認證、服務分成體系,培養更多的認證服務代理商,
- 提供更多的專業領域函式,比如說空間函式庫,功能上可以參考mysql的空間函式庫,
- 開放第三方的函式插件市場,在插件開發規范的基礎上,會有更多的用戶貢獻出專業領域的函式插件,
愿TDengine借助中國的巨大市場,成長為時序資料庫領域的Oracle!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/413336.html
標籤:其他