這是我第一次創建用于處理包含大量資料的檔案的代碼,所以我有點卡在這里。
我要做的是讀取路徑串列,列出所有需要讀取的 csv 檔案,從每個檔案中檢索 HEAD 和 TAIL 并將其放入串列中。
我總共有 621 個 csv 檔案,每個檔案由 5800 行和 251 列組成
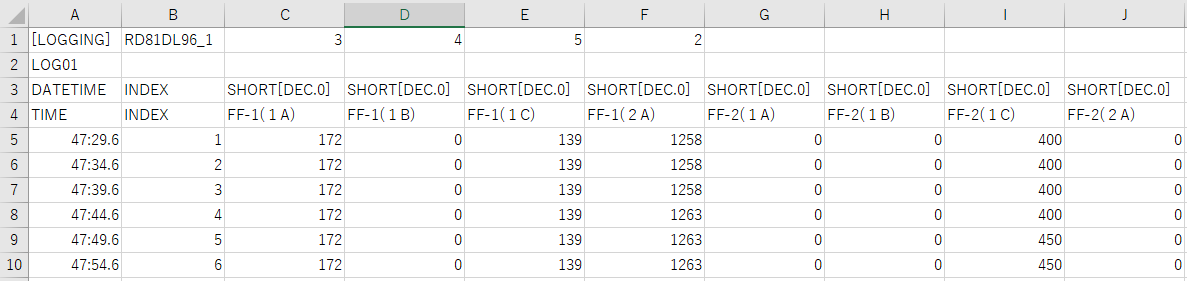 這是資料樣本
這是資料樣本
[LOGGING],RD81DL96_1,3,4,5,2,,,,
LOG01,,,,,,,,,
DATETIME,INDEX,SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0]
TIME,INDEX,FF-1(1A) ,FF-1(1B) ,FF-1(1C) ,FF-1(2A),FF-2(1A) ,FF-2(1B) ,FF-2(1C),FF-2(2A)
47:29.6,1,172,0,139,1258,0,0,400,0
47:34.6,2,172,0,139,1258,0,0,400,0
47:39.6,3,172,0,139,1258,0,0,400,0
47:44.6,4,172,0,139,1263,0,0,400,0
47:49.6,5,172,0,139,1263,0,0,450,0
47:54.6,6,172,0,139,1263,0,0,450,0
問題是,雖然讀取所有檔案大約需要 13 秒(老實說還是有點慢)
但是當我添加一行附加代碼時,這個程序需要很多時間才能完成,大約 4 分鐘。
以下是代碼片段:
# CsvList: [File Path, Change Date, File size, File Name]
for x, file in enumerate(CsvList):
timeColumn = ['TIME']
df = dd.read_csv(file[0], sep =',', skiprows = 3, encoding= 'CP932', engine='python', usecols=timeColumn)
# The process became long when this code is added
startEndList.append(list(df.head(1)) list(df.tail(1)))
為什么會這樣?我正在使用 dask.dataframe
uj5u.com熱心網友回復:
目前,您的代碼并沒有真正利用 Dask 的并行化功能,因為:
df.head并且df.tail呼叫將觸發“計算”(即,將您的 Dask DataFrame 轉換為 pandas DataFrame——這是我們在使用 Dask 進行惰性評估時嘗試最小化的內容),并且- for 回圈按順序運行,因為您正在創建 Dask DataFrames 并將它們轉換為 pandas DataFrames,所有這些都在回圈內。
因此,您當前的示例類似于僅在 for 回圈中使用 pandas,但增加了 Dask-to-pandas-conversion 開銷。
由于您需要處理每個檔案,我建議您查看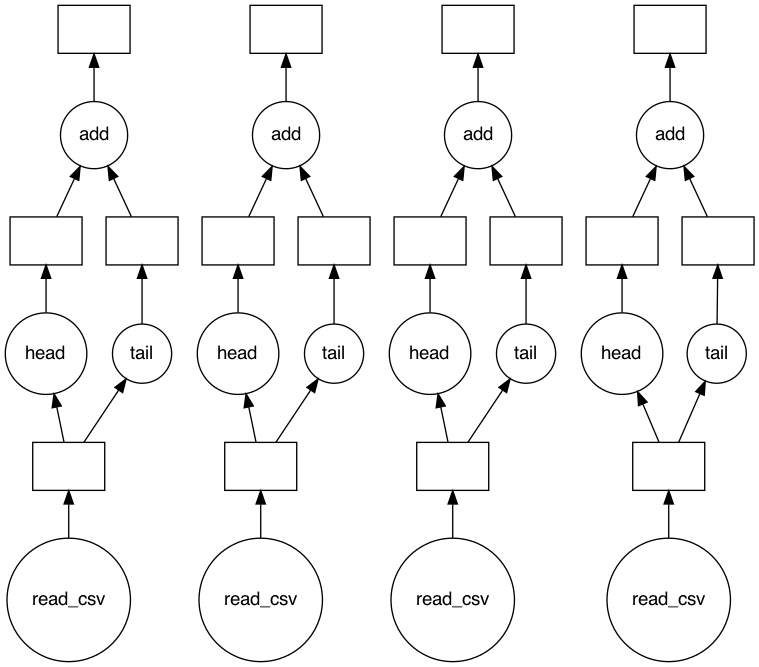
如果你真的想在這里使用 Dask DataFrame,你可以嘗試:
- 將所有檔案讀入單個 Dask DataFrame,
- 確保每個 Dask “磁區”對應一個檔案,
- 使用 Dask Dataframe
apply獲取head和tail值并將它們附加到新串列 - 在新串列上呼叫計算
uj5u.com熱心網友回復:
第一種僅使用 Python 作為起點的方法:
import pandas as pd
import io
def read_first_and_last_lines(filename):
with open(filename, 'rb') as fp:
# skip first 4 rows (headers)
[next(fp) for _ in range(4)]
# first line
first_line = fp.readline()
# start at -2x length of first line from the end of file
fp.seek(-2 * len(first_line), 2)
# last line
last_line = fp.readlines()[-1]
return first_line last_line
data = []
for filename in pathlib.Path('data').glob('*.csv'):
data.append(read_first_and_last_lines(filename))
buf = io.BytesIO()
buf.writelines(data)
buf.seek(0)
df = pd.read_csv(buf, header=None, encoding='CP932')
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/441873.html