我在同一目錄中有多個 csv 檔案。每個 csv 檔案包含 3 列,但在第 3 列中,缺少列名。要讀取所有 csv 檔案,我必須使用error_bad_lines=False. 現在,我想將列名添加c3到多個 csv 檔案的第三列。
樣本df:
v info
12 days 6
53 x a
42 y b
預期輸出:
v info c3
0 12 days 6
1 53 x a
2 42 y b
uj5u.com熱心網友回復:
不確定你的 csv 是什么樣子,所以我假設你的 csv 是:
v,info,
12,days,6
53,x,a
42,y,b
無論如何,您可以加載目錄中的所有 csv 檔案并更改列名,如下所示:
import pandas as pd
import glob
for f in glob.glob("C:\*.csv"):
print(f) # f is a file name
df = pd.read_csv(f)
df.reset_index() # add index column, 0, 1, 2, ...
df.columns = ['v', 'info', 'c3'] # change column names
df.to_csv(f) # save it (overwriting)
您可以在此處詳細了解如何使用glob加載目錄中的檔案: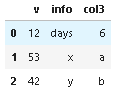
或者,簡單地說:
a.rename(columns={'':'new'})
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/441874.html
下一篇:將Pandas資料框匯出為CSV