論文地址:https://arxiv.org/pdf/1709.01507.pdf
代碼地址:https://github.com/hujie-frank/SENet
1、通道間的特征關系
近些年來,卷積神經網路在很多領域上都取得了巨大的突破,而卷積核作為卷積神經網路的核心,通常被看做是在區域感受野上,將空間上(spatial)的資訊和特征維度上(channel-wise)的資訊進行聚合的資訊聚合體,卷積神經網路由一系列卷積層、非線性層和下采樣層構成,這樣它們能夠從全域感受野上去捕獲影像的特征來進行影像的描述,
我們可以看到,已經有很多作業在空間維度上來提升網路的性能,那么很自然想到,網路是否可以從其他層面來考慮去提升性能,比如考慮特征通道之間的關系?論文的作者就是基于這一點并且提出了Squeeze-and-Excitation Networks(簡稱 SENet),作者并不希望引入一個新的維度來進行特征通道間的融合,而是采用一種全新的特征重標定策略,簡單來說,就是通過增加一條分支,自動獲取到每個通道的重要程度,然后依照這個重要程度去提升有用的資訊,同時抑制對當前任務用處不大的特征,
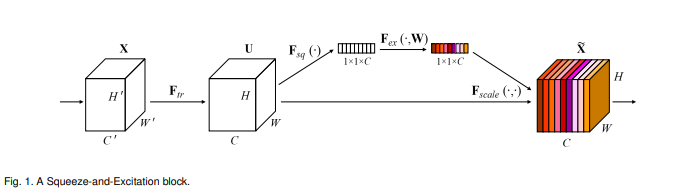
上圖是SE模塊的示意圖,給定一個輸入X,其通道數維C’,經過一系列卷積等變換后得到一個通道數維C的特征,接下來的結構有點類似ResNet,但又與ResNet有很大不同,
首先是Squeeze操作,我們順著空間維度來進行特征壓縮,將每個二維特征通道變換成一個實數,這個實數某種程度上具有全域感受野,并且輸出和輸入的通道數是一樣的,它表征著在特征通道上回應的全域分布,而且使得靠近輸入的層也可以獲得全域的感受野,這一點在很多任務中都是非常有用的,
其次是Excitation操作,他是類似于RNN中門的機制,通過引數W來為每個特征通道生成權重,其中引數W將被用來控制U中每個通道的重要性,
最后一個是Reweight的操作,我們將Excitation的輸出權重看做是特征選擇后每個特征通道的重要性,然后通過乘法逐通道加權到原來的特征U上,完成在通道維度上的特征重標定,
2、具體的網路結構
由于SE模塊并不像GoogLeNet和ResNet一樣,提出了全新的網路結構,所以它是可以很靈活的嵌入到已有主流網路中去,
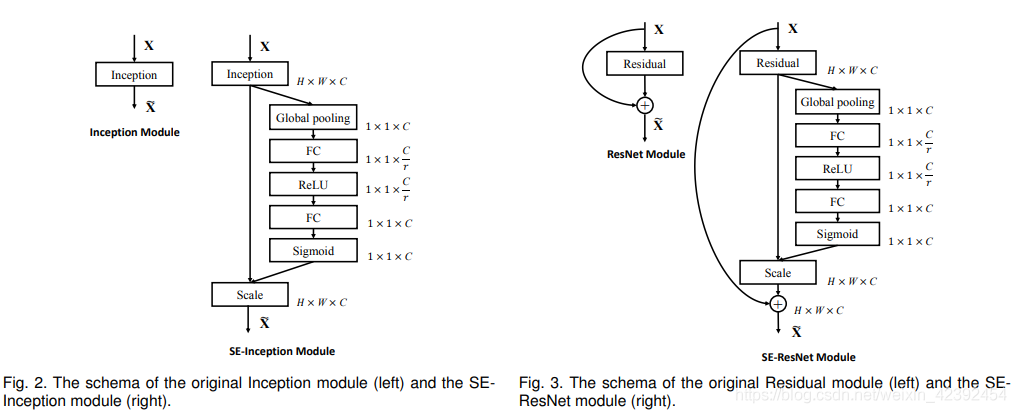
上圖左邊是將SE模塊嵌入到Inception結構的一個示例,
這里的Global pooling對應著Squeeze操作,它將輸入特征層的維度壓縮至1 x 1 x C,緊接著兩個全連接層組成一個Bottleneck結構去建模通道間的相關性,并且最終輸出的維度資訊保持不變,為1 x 1 x C,
我們可以看到第一個全連接層使用了ReLU作為激活函式,第二個層采用了Sigmoid的作為激活函式,而我們知道Sigmoid會變數映射到0,1之間,也就是說有用的特征通過SE模塊讓他更偏向于1了,同時無用的特征也更接近0了,那么通過最后Scale操作,將輸出權重與原始特征的每個通道逐乘也就增益了原始通道有用的特征,抑制了無用特征,
為什么采用兩個全連接層而不是一個的原因在于:
- 通過ReLU可以獲得更多的非線性
- 引入r引數可以減少引數量和計算量
除此之外,SE模塊也可以嵌入到含有跨層連接的網路中去,上圖右邊就是將SE嵌入到模塊中的一個例子,原理、操作基本和SE-Inception一樣,只不過是在最后的Addition前對分支上Residual的特征進行重標定,
目前大多數的主流網路都是基于這兩種類似的單元通過 repeat 方式疊加來構造的,由此可見,SE 模塊可以嵌入到現在幾乎所有的網路結構中,通過在原始網路結構的 building block 單元中嵌入 SE 模塊,我們可以獲得不同種類的 SENet,如 SE-BN-Inception、SE-ResNet、SE-ReNeXt、SE-Inception-ResNet-v2 等等,
3、實驗結果
論文中給出了ResNet、ResNeXt等在當時比較常見的網路對比結果,深度學習經過幾年的發展,在資料增強上也有了新的突破,為了公平起見,作者將網路又重新實作了一遍并且采用了同樣的資料增強方式,結果如下圖所示:
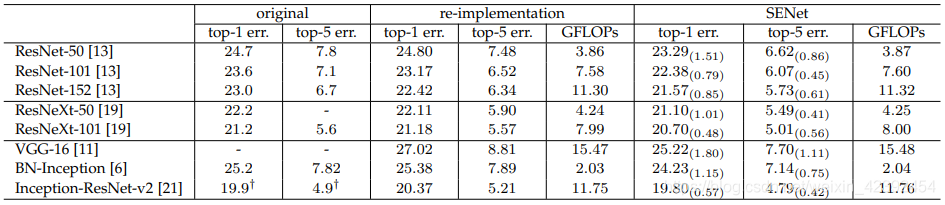
結合試驗結果和上面的介紹來看,我們可以發現SENet的構造非常簡單,不需要引入新的函式或層,對比原來的網路,僅僅只需要增加2%-10%的引數,就能將誤差降低0.4-1.1左右,
4、更多的嘗試
引數r的調節
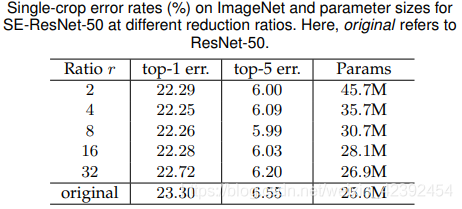
我們在第一個全連接中引入了引數r,使得第一個全連接層的通道數減少,整體呈現一個瓶頸狀的結構,作者的試驗結果發現r=8時會有一個比較好的效果,
Pooling的方式
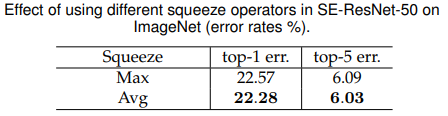
對于空間維度的壓縮方式,作者嘗試了Global Max Pooling和Global Average Pooling兩種方式,無論是top-1還是top-5,結果都表明,AvgPool效果會更好,
激活函式的選擇
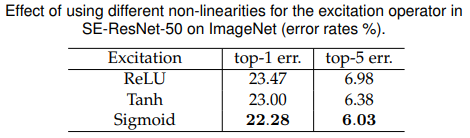
接下來是最后一個全連接層激活函式的選擇,用tanh替換sigmoid會略微惡化性能,而使用ReLU會顯著惡化,實際上會導致SE-ResNet-50的性能低于ResNet-50基線,這表明,為了使SE塊有效,激活函式的選擇是很重要的,
SE Block添加的位置
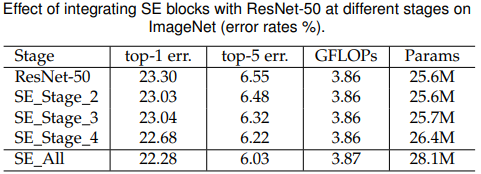
作者還對SE模塊添加的位置做了對比,在top-5上在越靠后的Stage上填加SE模塊比在越靠前的Stage上添加效果要好,當然如果在所有Stage都添加效果是最好的,
SE的四種結構
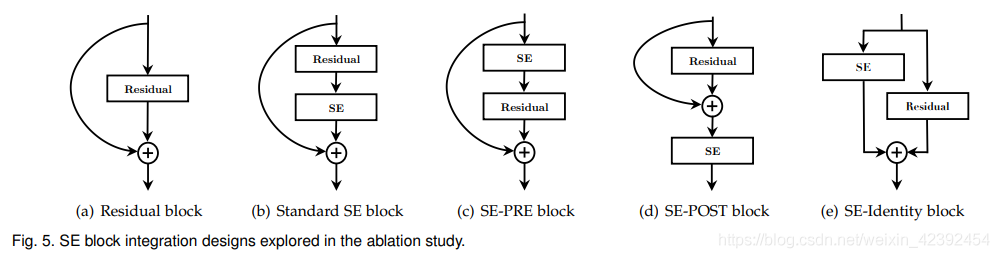
最后是對SE模塊的結構進行了對比:
? (a) 普通的殘差
? (b) 標準的SE模塊
? ? 先進行SE再進行殘差
? (d) 先完成殘差計算再進行SE模塊計算
? (e) 在跨層連接上完成SE模塊計算
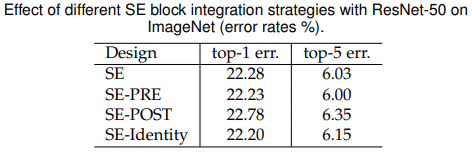
從結果上看,是SE-PRE的結構略勝一籌,但個人覺得只是在ResNet-50上對比了一下還不具有說服力,但是無論是什么結構都會提高ResNet的準確率,說明SE模塊是有起作用的,
5、總結
SENet作為ImageNet競賽的最后一屆影像識別冠軍,作者是付出了很多的時間,在網路架構上做了大量的嘗試和實驗,論文中還有些細節沒有在本文中展開解釋,讀者可以下載論文詳細閱讀,作者開源的代碼是基于caffe的,筆者自己也嘗試在keras和tf2上進行復現,比較直觀的效果是分類的置信度比原本ResNet要高很多,可能是因為在SE-ResNet中進行了多次sigmoid函式激活,
- Keras-SEResNet
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/255886.html
標籤:其他
上一篇:前端之H5與App互動總結
下一篇:關于年度述職報告總結雜語