目錄
一、什么是快取雪崩
1.1 簡介快取雪崩
1.2 快取雪崩的解決方式
二、什么是快取穿透
2.1 簡介快取穿透
2.2 快取穿透的解決方法
三、什么是快取擊穿
3.1 簡介快取擊穿
3.2 快取擊穿解決方法
一、什么是快取雪崩
1.1 簡介快取雪崩
舉個簡單的例子:我們都知道redis里都是 key-value對,如果所有首頁的Key失效時間都是12小時,中午12點重繪的,我零點有個秒殺活動大量用戶涌入,假設當時每秒 6000 個請求,本來快取在可以扛住每秒 5000 個請求,但是快取當時所有的Key都失效了,此時 1 秒 6000 個請求全部落資料庫,資料庫必然扛不住,它會報一下警,真實情況可能DBA都沒反應過來就直接掛了,此時,如果沒用什么特別的方案來處理這個故障,DBA 很著急,重啟資料庫,但是資料庫立馬又被新的流量給打死了,這就是我理解的快取雪崩,
簡單來說就是,由于大部分的key都在某個時間點全部失效,那么這時候的申請就會直接打到資料庫上(因為redis上的快取失效了),然后資料庫由于扛不住那么大的壓力而掛掉,這就是快取雪崩,
如下圖,左邊是redis的快取還沒失效的情況,而右邊是快取失效,請求直接達到mysql資料庫上的情況:
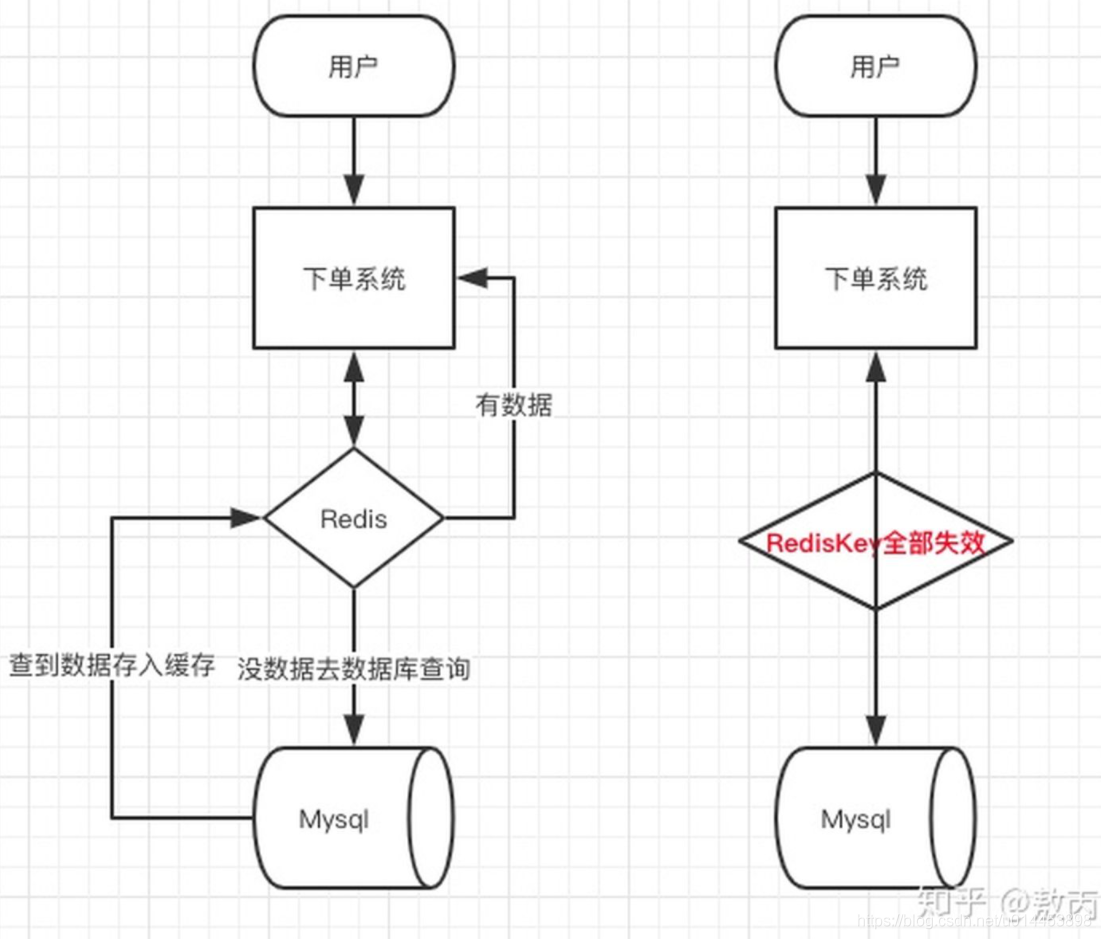
同一時間大面積失效,那一瞬間Redis跟沒有一樣,那這個數量級別的請求直接打到資料庫幾乎是災難性的,你想想如果打掛的是一個用戶服務的庫,那其他依賴他的庫所有的介面幾乎都會報錯,如果沒做熔斷等策略基本上就是瞬間掛一片的節奏,你怎么重啟用戶都會把你打掛,等你能重啟的時候,用戶早就睡覺去了,并且對你的產品失去了信心,什么垃圾產品,
1.2 快取雪崩的解決方式
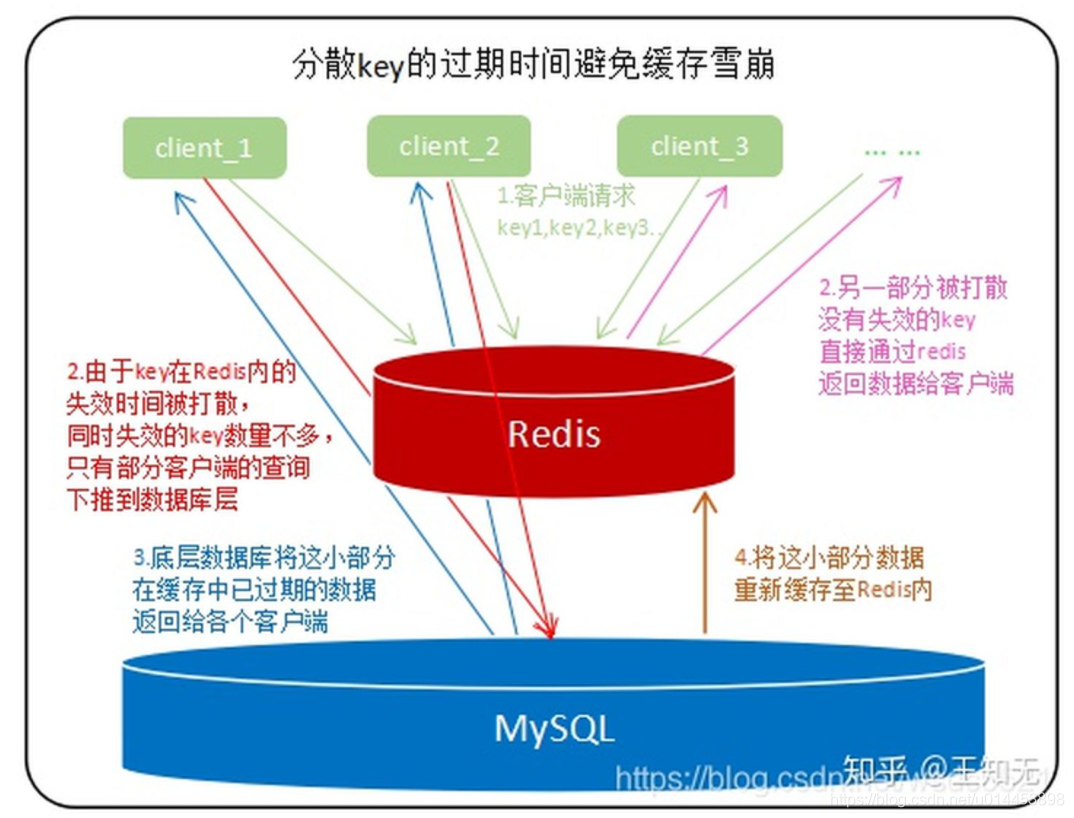
1. 失效時間加個隨機值
處理快取雪崩簡單,在批量往
Redis存資料的時候,把每個Key的失效時間都加個隨機值就好了,這樣可以保證資料不會在同一時間大面積失效
2. 設定熱點快取資料永遠不過期
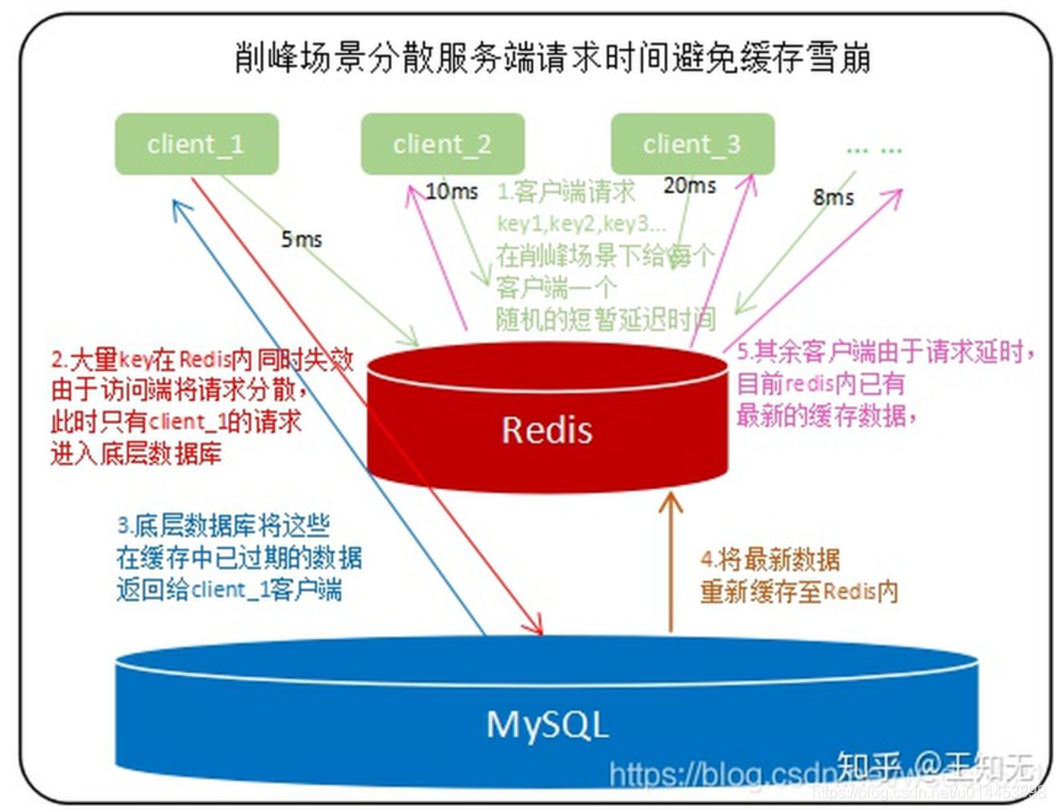
3. 分散請求時間,給每個客戶端一個隨機的短暫延遲時間
二、什么是快取穿透
2.1 簡介快取穿透
快取穿透是指快取和資料庫中都沒有的資料,而用戶不斷發起請求,我們資料庫的 id 都是1開始自增上去的,如發起為id值為 -1 的資料或 id 為特別大不存在的資料,這時的用戶很可能是攻擊者,攻擊會導致資料庫壓力過大,嚴重會擊垮資料庫,
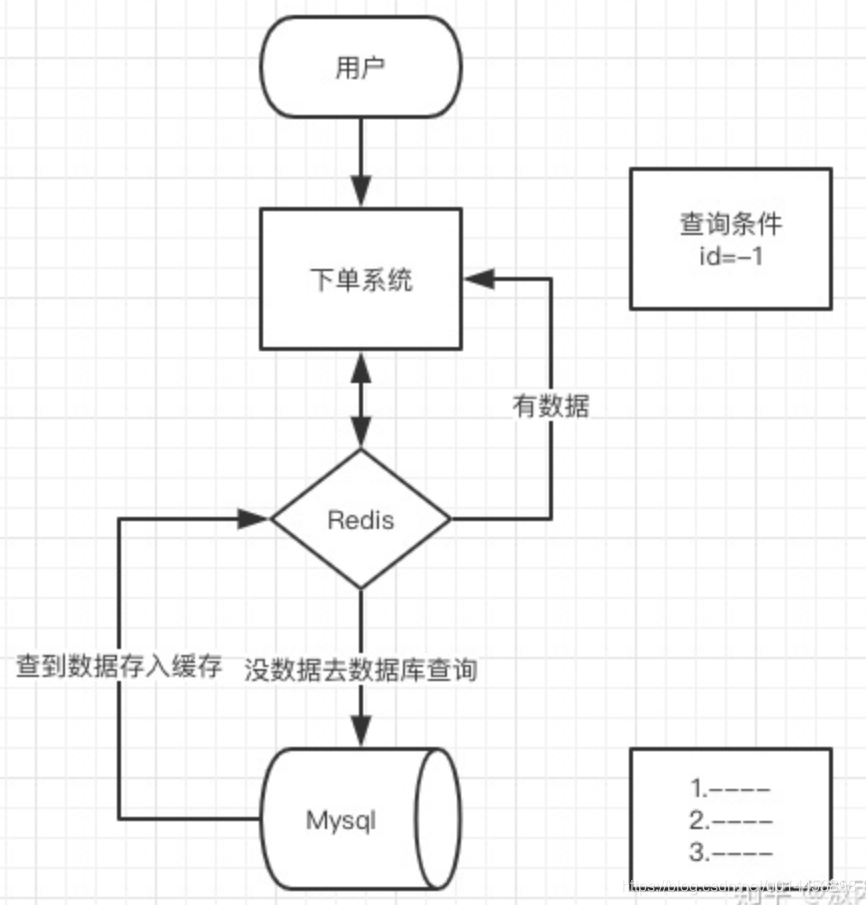
像這種你如果不對引數做校驗,資料庫id都是大于0的,我一直用小于0的引數去請求你,每次都能繞開Redis直接打到資料庫,資料庫也查不到,每次都這樣,并發高點就容易崩掉了,
2.2 快取穿透的解決方法
1. 快取穿透我會在介面層增加校驗
比如引數做校驗,不合法的引數直接代碼Return,比如:id 做基礎校驗,id <=0的直接攔截等,
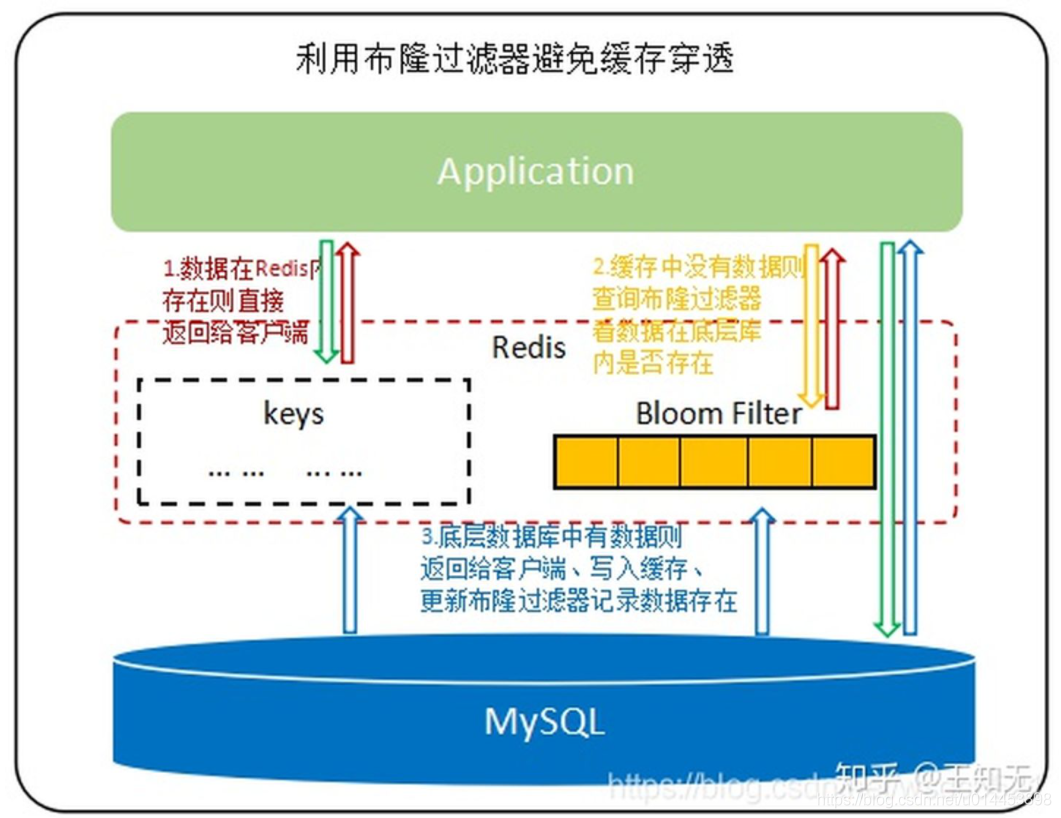
2. 布隆過濾器
他的原理也很簡單就是利用高效的資料結構和演算法快速判斷出你這個Key是否在資料庫中存在,不存在你return就好了,存在你就去查了DB重繪KV再return,
大概原理為:先創建一個長度為n的bitmap,和k個hash函式,當有key加入時,則通過k個hash函式得到k個值,然后把bitmap中對應的位元位設成1,
當判斷某個key是否在集合時,用k個hash函式計算出k個散列值,并查詢陣列中對應的位元位,如果所有的位元位都是1,認為在集合中,
詳細如下鏈接:https://www.cnblogs.com/liyulong1982/p/6013002.html
缺點:無法洗掉key
3. 把在資料庫找不到的key的value暫時設定成null,
從快取取不到的資料,在資料庫中也沒有取到,這時也可以將對應Key的Value對寫為null、位置錯誤、稍后重試這樣的值具體取啥問產品,或者看具體的場景,快取有效時間可以設定短點,如30秒(設定太長會導致正常情況也沒法使用),
三、什么是快取擊穿
3.1 簡介快取擊穿
至于快取擊穿嘛,這個跟快取雪崩有點像,但是又有一點不一樣,快取雪崩是因為大面積的快取失效,打崩了DB,而快取擊穿不同的是快取擊穿是指一個Key非常熱點,在不停的扛著大并發,大并發集中對這一個點進行訪問,當這個Key在失效的瞬間,持續的大并發就穿破快取,直接請求資料庫,就像在一個完好無損的桶上鑿開了一個洞,
3.2 快取擊穿解決方法
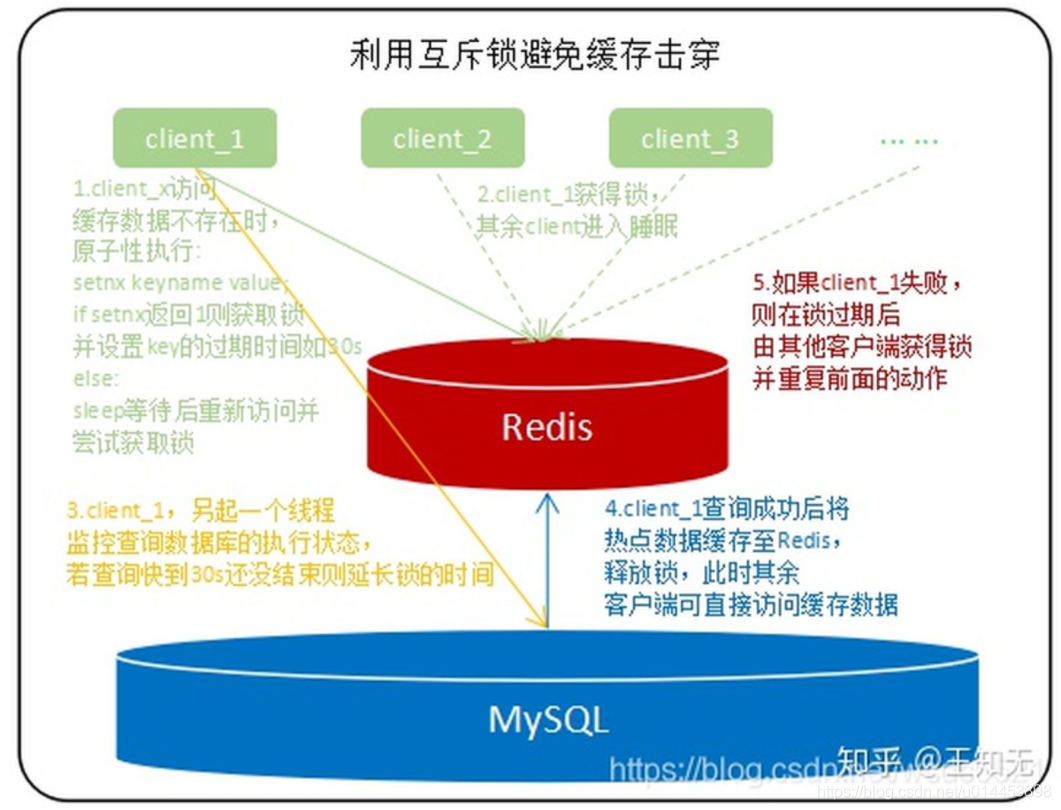
1.快取擊穿的話,設定熱點資料永遠不過期,
2. 采用互斥鎖,保證同一時刻只有一個客戶端可以查詢底層資料庫這個資料,一旦查到資料就快取至redis內,避免其他大量請求同時穿過redis訪問底層資料庫,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259694.html
標籤:其他
上一篇:Kubernetes應用場景