
作者Jay Kreps是前LinkedIn的Principle Staff Engineer,現Confluent CEO,在大資料處理領域深耕多年,我感覺這本書還是很好的,雖然只有40多頁,但是我覺得內容挺多的,沒湊字數的廢話,
整理下我個人的takeaway:
對日志的認知
"log"這個詞吃了命名的虧,以為人們習慣把代碼里調錯的各種print當成log,所以沒把它當回事,但事實上log的核心是資料,不應該是給人看的,而是給機器讀的,log記錄的是什么時候發生了什么——而這恰恰就是分布式系統最核心要處理的內容,
log在分布式系統中可以用于兩種場景:
- 一種是state-machine replica,就是類似于pub/sub,寫入一個順序
- 另一種是primary backup,利用log做狀態備份
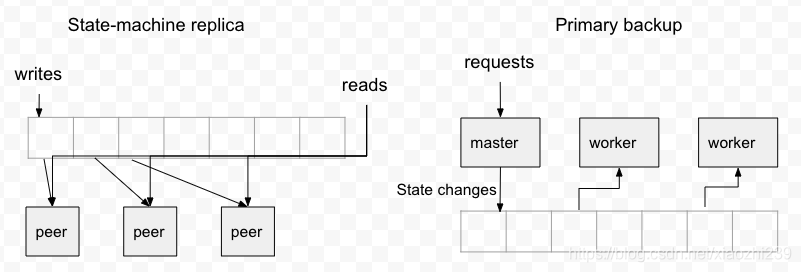
日志服務應該作為一個獨立的服務,并以此可以成為以下系統的基礎:
- 資料整合,比如支持各種各樣團隊不同需求的資料可視化
- 實時資料處理,比如批處理、流處理
- 分布式系統的整體設計,這本書里介紹了如何利用log去對分布式系統架構進行解耦
基于日志服務的系統建設
對日志的需求遵循以下“Maslov需求金字塔”的順序,上層建筑依賴于下層基礎:
- 最底層 Acquisition / Collection:資料采集相關,大部分公司在這層就不行了
- 再上層是 Semantics:統一格式才能有統一處理
- 再上層是 Understanding:如何理解或者幫助人們更好的理解資料,比如一系列的資料分析和可視化,
- 最上層是 Automation: 終極需求是基于資料做自動決策,不需要人的干預

資料整合
如何使用一套資料服務現代公司形形色色各種team的各種各樣的需求?- 使用log結合pub/sub的模式,不同team可以訂閱自己關注的事件,這樣也能實作互相之間的獨立,
批量處理
為了兼顧實時性和資料的完整性,很多人是如下使用一套批處理一套流處理的方式處理資料(http://bit.ly/beat-cap):
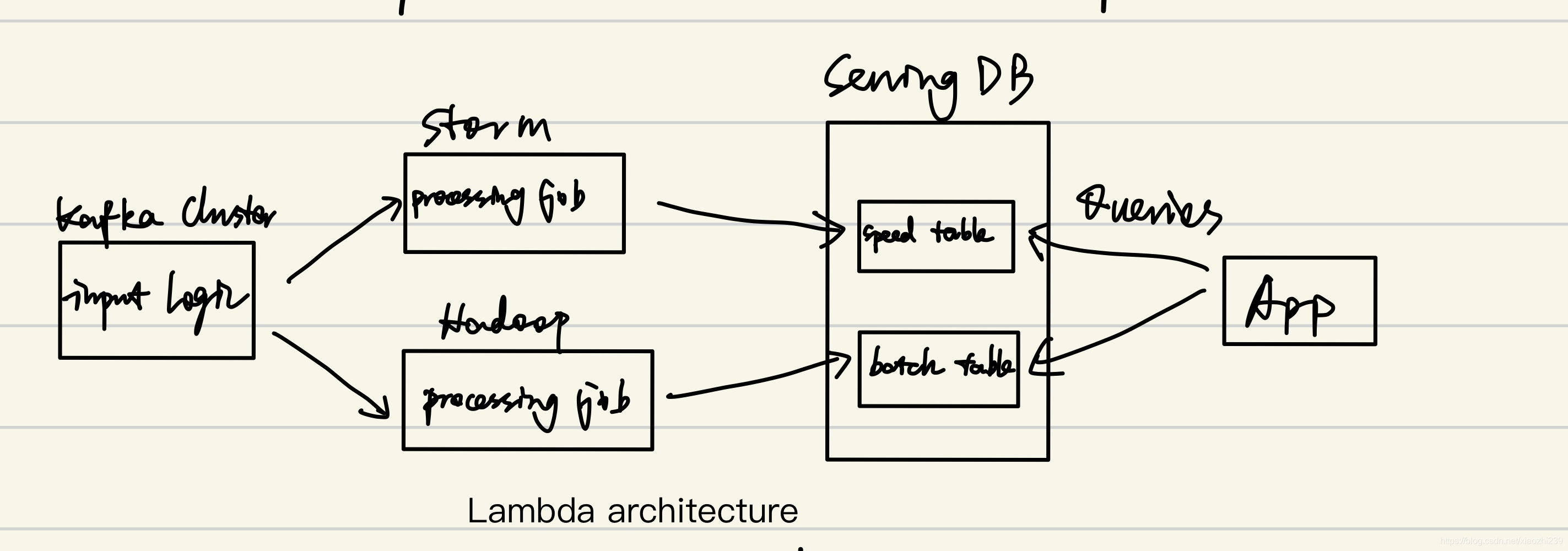
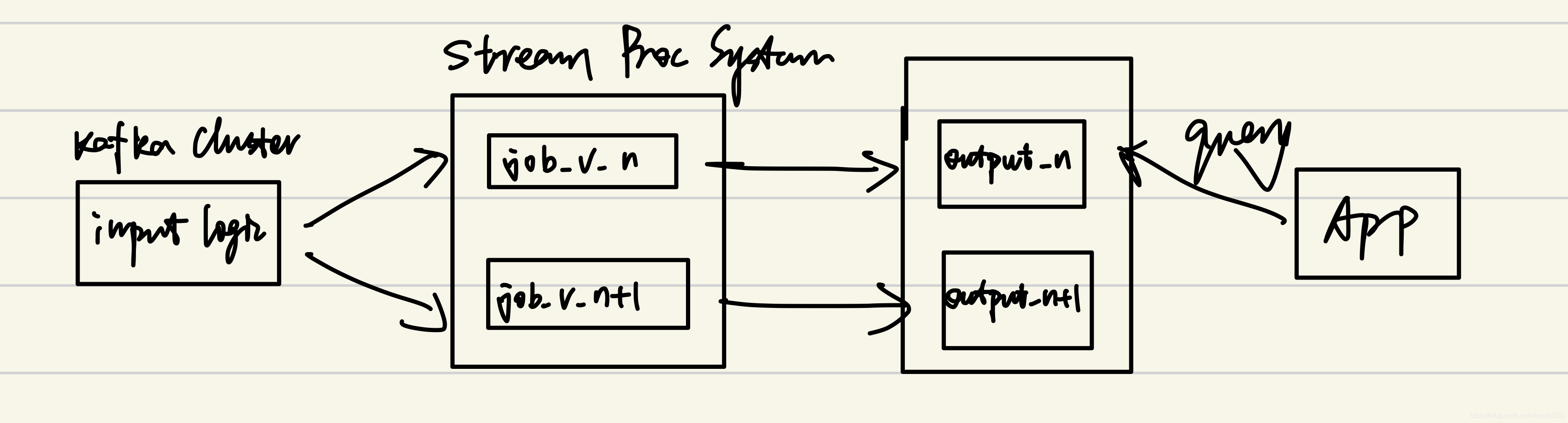
但是這樣維護成本很大,其實可以都使用流的處理方式,如下圖所示,新的一批處理好把請求導向新的,把舊的洗掉就好了(即部署資料如同部署服務一樣?):
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259695.html
標籤:其他
下一篇:Vue回應式原理