目錄
一本正經的介紹😎
背景介紹
前期準備
Python 的 MapReduce 代碼
Map: mapper.py
詳細步驟(小學生也可以完成的步驟!)
聊天式教學:(🐰小W——>👸小L)的對話
🐰小W:把大象裝進冰箱需要幾步?
一、打開冰箱
mapper.py
reducer.py
二、把大象裝進冰箱
測驗腳本代碼
測驗結束,集群運行!
三、關閉冰箱
hdfs語法合集
加餐案例😉
每文一語
一本正經的介紹😎
背景介紹
在這個實體中, 主要是介紹如何使用 Python 為 Hadoop 撰寫一個簡單的MapReduce 程式,盡管 Hadoop 框架是使用 Java 撰寫的但是我們仍然希望能夠使用像 C++、Python 等語言來實作 Hadoop 程式,
因為 Hadoop 官方網站給的示例程式是使用Jython 撰寫并打包成 Jar 檔案,這樣顯然給未學習過 java 語言的開發人員造成不便, 而且, Hadoop 本身具有很好的跨平臺特性, 所以我們可以使用 Python等其他一些常用平臺與 Hadoop 關聯進行編程, 首先要確認我們需要做的作業,
我們將撰寫一個簡單的 MapReduce 程式,使用的是 C-Python,而不是Jython 撰寫后打包成 jar 包的程式,這個例子就是要實作 WordCount 并且通過使用 Python 來實作,例子通過讀取文本檔案來統計出單詞的出現次數,結果也以文本形式輸出,每一行包含一個單詞和單詞出現的次數,兩者中間使用制表符來進行間隔,
前期準備
撰寫這個程式之前,你學要架設好 Hadoop 集群,這樣才能不會在后期作業難受,如果是使用的是學校的機房,請按照這個步驟,直接暴力復制,一點都不需要改動,也可以直接運行!
Python 的 MapReduce 代碼
使用 Python 撰寫 MapReduce 代碼的技巧就在于我們使用了 HadoopStreaming來幫助我們在 Map 和 Reduce 間通過 STDIN (標準輸入)和 STDOUT (標準輸出)來傳遞資料.我們使用 Python 的 sys.stdin 來輸入資料,使用 sys.stdout 輸出資料,這樣做是因為 HadoopStreaming 會幫我們辦好其他事,
Map: mapper.py
將寫好的代碼保存在/usr/local/hadoop/mapper.py 中,他將從 STDIN 讀取資料并將單詞成行分隔開,生成一個串列映射單詞與發生次數的關系:注意:要確保這個腳本有足夠權限(chmod +x mapper.py),
詳細步驟(小學生也可以完成的步驟!)
感覺好枯燥啊,這么多的文字,絕望了![]() ,就知道感覺到絕望了哈
,就知道感覺到絕望了哈
聊天式教學:(🐰小W——>👸小L)的對話
🐰小W:把大象裝進冰箱需要幾步?
👸小L:不是三步嗎,這么簡單的問題還想要考我
🐰小W:哈哈哈,真聰明喲,三步帶你感受編程的快樂哈
一、打開冰箱
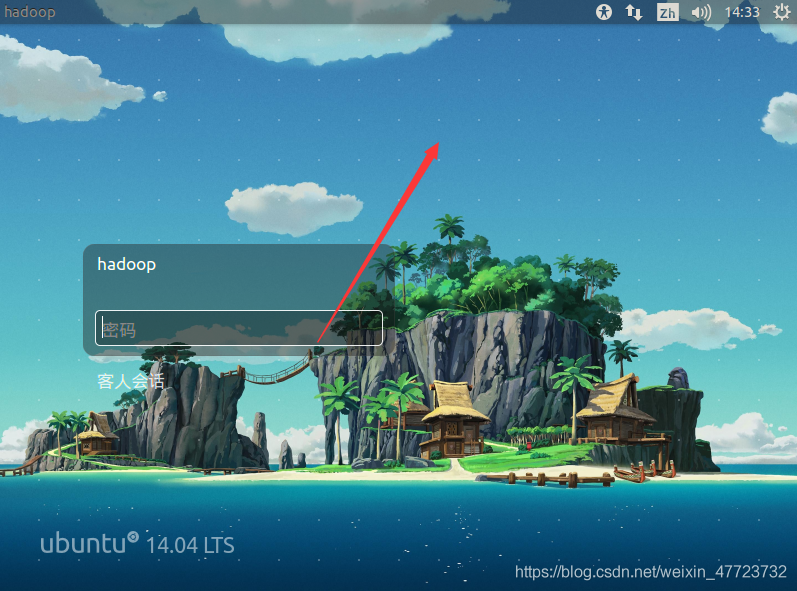
🐰小W:打開我們的虛擬機,點擊圖示,然后點擊hadoopvm,進入我們的另外一臺機器

輸入密碼:hadoop
👸小L:好了,但是這個虛擬機的桌面也太小了吧,看的我眼睛都哭了😩
🐰小W:怎么會很小了,看看下面的操作,瞬間變大!
點擊這里進入全屏模式

🐰小W:然后準備好我們的mapper.py和reducer.py代碼
👸小L:這個我知道,不就是創建兩個檔案夾嗎,看我操作:
首先在Windows桌面新建兩個檔案,因為Windows使用起來非常方便,寫好之后就可以直接復制到Ubuntu里面了,這樣是最方便的喲,哈哈哈

🐰小W:不是的,這樣做就錯啦,而且錯的讓你無法相信這個世界還有真理!!!哈哈哈
因為:在win下編輯的時候,換行結尾是\n\r , 而在linux下 是\n,所以才會有 多出來的\r
sed -i 's/\r$//' build.sh
要記住喲,在Linux和Windows一些檔案的操作是不一樣的,兩個作業系統有各自的規則,并不是在Windows下面方便操作,就可以操作哈
🐰小W:這里給出兩種方法😎
(一)、最簡單的操作:我覺得這個方法最適合你,所以還是先介紹這個吧😂
①、新建一個屬于自己檔案夾

②、新建兩個Python檔案,檔案名:mapper.py reducer.py
③.將下面的代碼復制到這個檔案里面,按住:Ctrl+S 保存就好了!!!
對應的代碼就在下面,點擊旁邊的復制按鈕就可以復制了
(二)、稍微帶一點點的技術操作,脫離滑鼠的控制,速度賊快
進入你的檔案目錄:cd ljw
使用vi命令自動創建檔案,然后編輯寫入內容,一步到位
vi mapper.py

至于reduce.py 也是這樣操作
👸小L:好,明白了![]()
mapper.py
#!/usr/bin/env python
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
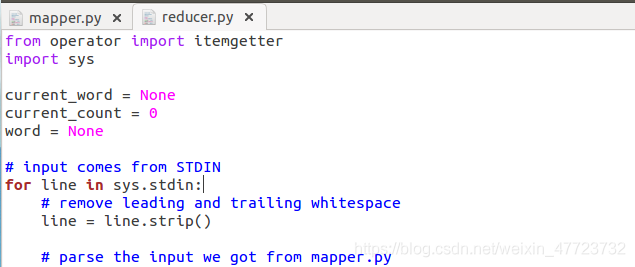
reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)有小伙伴發現:Python代碼竟然用的2版本的,本來是要用3的,但是這篇文章本來就是:合為時而作!!!要適合他們的才是最好的!
二、把大象裝進冰箱
🐰小W:將剛剛的兩個檔案,放在虛擬機里面,路徑如下:
首先要在這里新建一個mapreduce
/home/hadoop/ljw🐰小W:測驗腳本是否可以運行
切換到該路徑下:
cd /home/hadoop/ljw測驗代碼如下:
echo "foo foo quux labs foo bar quux" |./mapper.py | sort |./reducer.py
🐰小W:這里需要添加權限,為確保程式可以執行:這里的 +x 表示可以讓它變成可執行的檔案程式
👸小L:為什么呀?太多的疑問了![]()
🐰小W:對于chmod +x file 來說就是將file改為可執行狀態,在linux因高亮語法,會讓file檔案顯示綠色,對于灰色的檔案來說,沒有可執行的權限,這是若我們給它chmod +x后它將會變為可執行的綠色檔案,
👸小L:但是有的時候他們用的chmod 777 file 是什么意思呀?
🐰小W:其實吧,在操作檔案的權限的時候可以使用數字,也可以使用- + = ,也可以使用數字:4 2 1,下面詳細介紹一下,全面復習一下:
u User,即檔案或目錄的擁有者
g Group,即檔案或目錄的所屬群組
o Other,除了檔案或目錄擁有者或所屬群組之外,其他用戶皆屬于這個范圍
a All,即全部的用戶,包含擁有者,所屬群組以及其他用戶
mode : 權限設定字串,格式如下 : [ugoa…][[±=][rwxX]…][,…]
其中+ : 表示增加權限、- 表示取消權限、= 表示唯一設定權限,
r 讀取權限,數字代號為“4”;w 寫入權限,數字代號為“2”;x 執行或切換權限,數字代號為“1”;- 不具任何權限,數字代號為“0”;
s 特殊功能說明:變更檔案或目錄的權限
命令中各選項的含義為:
-c : 若該檔案權限確實已經更改,才顯示其更改動作
-f : 若該檔案權限無法被更改也不要顯示錯誤訊息
-v : 顯示權限變更的詳細資料
-R : 對目前目錄下的所有檔案與子目錄進行相同的權限變更(即以遞回的方式逐個變更)
--help : 顯示輔助說明
--version : 顯示版本
操作物件who可是下述字母中的任一個或者它們的組合:
u 表示“用戶(user)”,即檔案或目錄的所有者,
g 表示“同組(group)用戶”,即與檔案屬主有相同組ID的所有用戶,
o 表示“其他(others)用戶”,
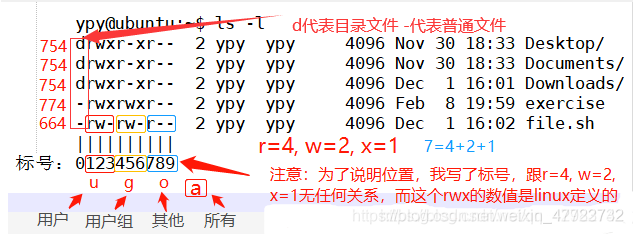

綠色檔案: 可執行檔案,可執行的程式
紅色檔案:壓縮檔案或者包檔案
藍色檔案:目錄
白色檔案:一般性檔案,如文本檔案,組態檔,原始碼檔案等
淺藍色檔案:鏈接檔案,主要是使用ln命令建立的檔案
紅色閃爍:表示鏈接的檔案有問題
黃色:表示設備檔案
灰色:表示其他檔案
chmod 777的語法為:chmod abc file
其中a,b,c各為一個數字,分別表示User、Group、及Other的權限,
r=4,w=2,x=1
若要rwx屬性則4+2+1=7;
若要rw-屬性則4+2=6;
若要r-x屬性則4+1=5
案例:
chmod a=rwx file 和chmod 777 file效果相同
chmod ug=rwx,o=x file和chmod 771 file效果相同
若用chmod 4755 filename可使此程式具有root的權限
綜上chmod +x 是將檔案狀態改為可執行,而chmod 777 是改變檔案讀寫權限
👸小L:好像懂了,這得消化一下,哈哈哈,太多的知識點了
🐰小W:接下里復制代碼,改權限吧
chmod +x reducer.pychmod +x mapper.py
測驗腳本代碼
🐰小W:首先測驗一下mapper.py這個檔案,是否是我們所需要的執行效果
echo "foo foo quux labs foo bar quux" | ./mapper.py這里首先使用Linux里面的命令 :echo 將文本列印,然后使用 | 管道符的命令 ./ 是表示執行檔案
👸小L:又遇到知識盲區了.......
🐰小W:echo 可以列印字串,就像我們的Python:print('hello word!'),其次這個 | 叫做管道符,它所代表的就是前面一個陳述句的結果輸出作為后面一條陳述句的輸入,這個就是管道符,使用管道符有利于我們程式的結構化執行
🐰小W:" ./ “ 的方式類似于新建了一個shell, 在這個新建的shell中去執行腳本中的程式,類似于新建了一個子行程,但這個子行程不繼承父行程的所有非export型別的變數,并且腳本中對非export環境變數的創建或修改不會反饋到外部呼叫shell中,感覺說的有點太專業了,簡單點就是執行這個程式
🐰小W:當然我覺得有必要補充一下,其他的相關知識
linux 中在shell中使用 " . " 和 " ./ " 執行的區別:
1. 如果使用" ./ " 執行,可以理解為程式運行在一個全新的shell中,不繼承當前shell的環境變數的值, 同時若在程式中改變了當前shell中的環境變數(不使用export),則當前shell的環境變數值不變,
2. 如果使用” . "執行,則程式繼承當前shell中的環境變數,同時,若在程式中改變了當前shell中的環境變數(不使用export),則當前shell中該環境變數的值也會改變
另外一個區別點在于, “ ./ "只能用于擁有執行權限的檔案, 而 ” . " 則可以暫時提升
👸小L:原來如此啊,懂了懂了😉
🐰小W:這個是執行結果,看看你的執行結果是否一樣
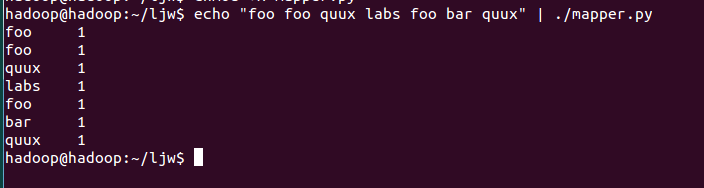
🐰小W:再去執行一下下面的代碼,看看reduce.py是不是可以運行成功
echo "foo foo quux labs foo bar quux" |./mapper.py | sort |./reducer.py
👸小L:好像沒有問題給🐮👍
測驗結束,集群運行!
🐰小W:剛剛是為了測驗這些腳本的準確性和正確性,下面就開始在hadoop的集群運行了,準備了一個文本檔案(西游記讀物)別名:book.txt
一切準備就緒,我們將在運行Python MapReduce job 在Hadoop集群上,像我上面所說的,我們使用的是HadoopStreaming 幫助我們傳遞資料在Map和Reduce間并通過STDIN和STDOUT,進行標準化輸入輸出,
👸小L:那怎么做呢?
🐰小W:首先將這個檔案從復制到Ubuntu的檔案夾
👸小L:好了,然后應該怎么做呢?😳
🐰小W:然后就看我的操作哈😀😀😀😀
最重要的第一步:start-all.sh,開啟集群,不然在hdfs 操作的時候,會拒接連接!
1.使用命令:cat book.txt 查看檔案內容
![]()

2.上傳這個檔案到hdfs分布式檔案
首先在hdfs里面建一個存放資料的檔案夾
hdfs dfs -mkdir ljw上傳
hdfs dfs -copyFromLocal book.txt ljw
查看
hdfs dfs -ls ljw
資料準備好了,然后就是撰寫一個執行檔案了
👸小L:等等,我看老師發我的就是沒執行檔案,為什么要撰寫一個執行檔案了?
🐰小W:你想一下如果真的在實際操作程序中,在終端修改代碼那豈不是很麻煩,寫一個獨立的檔案是比較好的選擇,
1.首先新建一個檔案:run.sh
2.配置引數
🐰小W:首先找到Hadoop的檔案路徑
sudo find / -name hadoop-stream*
🐰小W:run.sh 里面的內容如下,直接復制到里面即可!!!
hadoop jar '/home/hadoop/hadoop-2.7.3/share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar' \
-mapper 'python mapper.py' \
-file /home/hadoop/ljw/mapper.py \
-reducer 'python reducer.py' \
-file /home/hadoop/ljw/reducer.py \
-input hdfs:/user/hadoop/ljw/book.txt \
-output /ljw/result👸小L:這個里面的一些代碼具體是什么含義呀?
🐰小W:第一行是告訴 Hadoop 運行 Streaming 的 Java 程式,接下來的是引數:這里的mapper 后面跟的其實是一個命令,也就是說,-mapper 和 -reducer 后面跟的檔案名不需要帶上路徑,而 -file 后的引數需要帶上路徑,為了讓 Hadoop 將程式分發給其他機器,需要-file 引數指明要分發的程式放在哪里,
🐰小W:注意:如果你在 mapper 后的命令用了引號,加上路徑名反而會報錯說找不到這個程式,(因為 -file 選項會將對應的本地引數檔案上傳至 Hadoop Streaming 的作業路徑下,所以再執行 -mapper 對應的引數命令能直接找到對應的檔案,
🐰小W:-input 和 -output 后面跟的是 HDFS 上的路徑名,這里的 input/book.txt 指的是input 檔案夾下剛才上傳的文本檔案,注意 -output 后面跟著的需要是一個不存在于 HDFS 上的路徑,在產生輸出的時候 Hadoop 會幫你創建這個檔案夾,如果已經存在的話就會產生沖突,因此每次執行 Hadoop Streaming 前可以通過腳本命令 hadoop fs -rmr 清除輸出路徑,
🐰小W:由于 mapper 和 reducer 引數跟的實際上是命令,所以如果每臺機器上 python 的環境配置不一樣的話,會用每臺機器自己的配置去執行 python 程式,
👸小L:看來這個概念還要好好學習一下😉
🐰小W:對滴喲😛
下面來看看效果吧

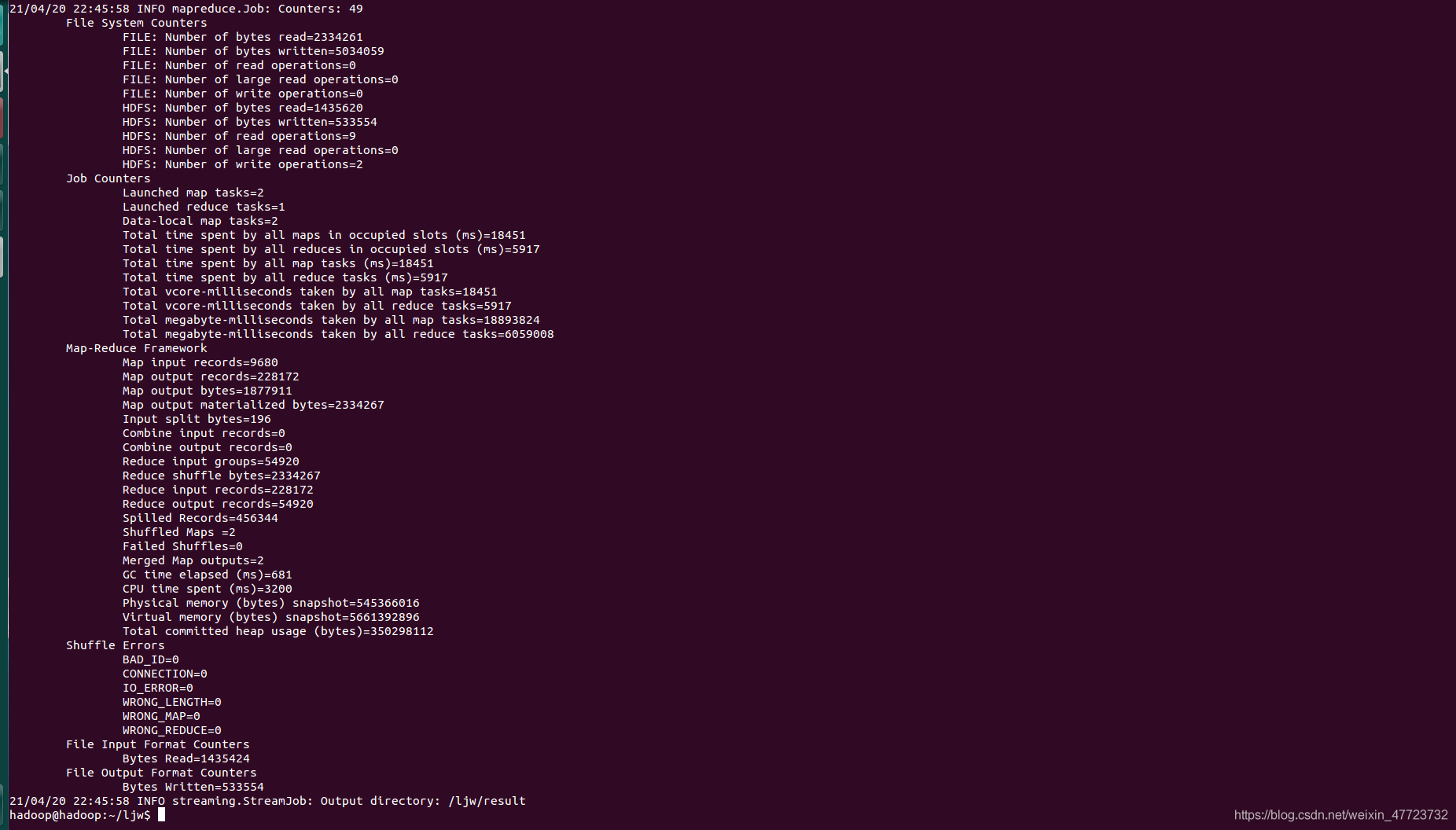
👸小L:這是已經成功了嗎?
🐰小W:對滴哈,下面看看結果
🐰小W: 查看命令
hdfs dfs -ls /ljw/result/
hdfs dfs -cat /ljw/result/part-00000

👸小L:終于出來了!!!!太棒啦😀
🐰小W:這里有幾個需要特別強調的,感覺在這個問題上面花了很久時間😭
🐰小W:首先在配置執行檔案:run.sh的時候,我們的路徑一定不要寫錯了,其次我們的輸入檔案是hdfs里面的路徑,但是我們最開始新建的時候直接使用mkdir ljw 其實自動創建在/usr/hadoop/路徑下面的,具體問題可以看看這個文章:點擊此處查看!
🐰小W:注意輸出的檔案是在hdfs里面的,是不需要創建的,如果創建了會起沖突的,所以只需要寫一個檔案就好了,會自動創建,比如ljw下面的result,
三、關閉冰箱
🐰小W:關閉冰箱就非常簡單了,注意我們每次在自己的虛擬機啟動集群之后需要關閉,使用命令:stop-all.sh
👸小L:好的,我記住了
🐰小W:這個使用Python實作Hadoop MapReduce程式,你應該會了吧,哈哈哈😉
👸小L:會了,感覺要好好看了
🐰小W:👍
👸小L:那我去看了哈
🐰小W:還沒有完喲,下面有一系列的hdfs語法案例操作,也可以看看
hdfs語法合集
🐰小W:dfs基本命令總結:
一、啟動Hadoop:
🐰小W:start-all.sh
二,hdfs命令
1、統一格式:
🐰小W:hdfs dfs -命令 檔案路徑
2、查看目錄下的檔案或檔案夾:
🐰小W:hdfs dfs -ls /
3、 將本地檔案上傳到hdfs上:
🐰小W:hdfs dfs -put 本地檔案路徑 遠程路徑
🐰小W:hdfs dfs -moveFromLocal 本地檔案路徑 遠程路徑
🐰小W:hdfs dfs -copyFromLocal 本地檔案路徑 遠程路徑
4、 在hdfs上創建檔案
🐰小W:hdfs dfs -touchz 檔案名
5, 在hdfs上創建檔案夾:
🐰小W:hdfs dfs -mkdir 檔案夾名
6、從hdfs檔案系統上下載檔案到本地檔案系統:
🐰小W:hdfs dfs -get 遠程路徑 本地路徑
7、 在hdfs檔案系統中更改檔案名與移動檔案位置:
🐰小W:hdfs dfs -mv 遠程路徑1 遠程路徑2
🐰小W:hdfs dfs -mv 檔案名1 檔案名2
8、在hdfs檔案系統中復制檔案:
🐰小W:hdfs dfs -cp 遠程路徑1 遠程路徑2
9、 hdfs檔案系統中洗掉檔案或目錄:
🐰小W:hdfs dfs -rm 檔案名或目錄名
10、查看hdfs檔案系統中的檔案:
🐰小W:hdfs dfs -cat 檔案名
11、向hdfs檔案系統中的檔案追加資訊:
🐰小W:hdfs dfs -appendToFile 檔案1 檔案2
解釋:向檔案2中寫入資訊:在本地系統先創建一個檔案,寫入資訊,在使用該命令,將資訊加入檔案2,
12、 將hdfs上的同名檔案,進行合并,再下載到本地檔案系統:
🐰小W:hdfs dfs -getmerge 遠程路徑 本地路徑
🐰小W:這些是常見的hdsf命令操作!!!
👸小L:好多啊,感覺要記住很多給
🐰小W:其實都是有規律,記住使用hdfs的時候:開頭一定是:hdfs dfs - 然后就是Linux里面的命令了,還有就是在使用hdfs的時候,一定要啟動集群喲
👸小L:好😀

加餐案例😉
🐰小W:這里還有一些案例操作,你也可以看看😉
🐰小W:安全模式,查看當前的狀態:hdfs dfsadmin -safemode get
🐰小W:進入安全模式:hdfs dfsadmin -safemode enter
🐰小W:強制離開安全模式:hdfs dfsadmin -safemode leave
🐰小W:一直等待直到安全模式結束:hdfs dfsadmin -safemode wait
🐰小W:在hdfs里面輸入命令,與Linux里面類似,只是需要在命令列開頭加-
🐰小W:查看該目錄下的子檔案,遞回查詢:hdfs dfs -ls -R /home
🐰小W:移動檔案夾或者檔案:hdfs dfs -mv 源檔案的位置 目標位置(如果是目錄檔案夾需要在后面加入/ 如果是檔案則不需要)
🐰小W:遞回洗掉home目錄下的子檔案或者子目錄:hdfs dfs -rm -r /home/檔案
🐰小W:洗掉目錄需要把引數改為d即可
🐰小W:創建多級檔案夾需要加-P引數,如果父目錄不存在,則創建父目錄
🐰小W:新建檔案:hdfs dfs -touchz /whw/whw.txt 然后我們可以利用:hdfs dfs ls -R /whw 查看
🐰小W:上傳檔案:首先要在本地上面創建一個檔案,注意這個時候不需要再touch后加z,我們創建好之后,利用:hdfs dfs -put 本地檔案位置 hdfs目標位置,也可以利用:hdfs dfs -copyFromLocal 本地檔案位置 hdfs目標位置
🐰小W:移動檔案:hdfs dfs -moveFromLocal 本地檔案位置 hdfs目標位置
🐰小W:將hdfs上的檔案下載到本地位置:hdfs dfs -get hdfs的位置 本地目標位置/重命名,也可以用hdfs dfs -copyToLocal hdfs的位置 本地目標位置
🐰小W:查看檔案:hdfs dfs -cat 檔案位置
🐰小W:追寫檔案:hdfs dfs -appendToFile 本地檔案 hdfs檔案(兩者都是相同的檔案型別)
🐰小W:hdfs里面的檔案復制:hdfs dfs -cp 源檔案 復制檔案 引數:-f 如果目標檔案存在則強制覆寫,-p保留檔案的屬性,移動檔案(改名檔案):hdfs dfs -mv 源檔案 目標檔案
🐰小W:hdfs中的目錄下的檔案(不包含子目錄)合并后在下載到本地:hdfs dfs -getmerge 本地檔案(位置默認,不需要添加)
😉😉😉😉😉😉😉😉😉😉😉😉😉
關于Hadoop里面的一些坑,你還知道哪些?歡迎留言評論區,幫助👸小L快樂的學習喲😀
每文一語
有一種快樂叫做和你一起😛😉
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/278909.html
標籤:其他