關于C/C++重點知識點匯總,
文章目錄
- C/C++記憶體有哪幾種型別?
- 堆和堆疊的區別?
- 堆和自由存盤區的區別?
- 程式編譯的程序?
- 計算機內部如何存盤負數和浮點數?
- 函式呼叫的程序?
- 左值和右值
- 什么是記憶體泄漏?面對記憶體泄漏和指標越界,你有哪些方法?你通常采用哪些方法來避免和減少這類錯誤?
- C和C++的區別?
- int fun() 和 int fun(void)的區別?
- const 有什么用途
- 在C中用const能定義真正意義上的常量嗎?C++中的const呢?
- 宏和行內(inline)函式的比較?
- C++中有了malloc / free , 為什么還需要 new / delete?
- C和C++中的強制型別轉換?
- static有什么用途
- 類的靜態成員變數和靜態成員函式各有哪些特性?
- 在C++程式中呼叫被C編譯器編譯后的函式,為什么要加extern“C”?
- 頭檔案中的ifndef/define/endif是干什么用的? 該用法和program once的區別?
- 當i是一個整數的時候++i和i++那個更快一點?i++和++i的區別是什么?
- 指標和參考的區別?
- 參考占用記憶體空間嗎?
- 三目運算子
- 指標陣列和陣列指標的區別
- 什么是面向物件(OOP)?面向物件的意義?
- 解釋下封裝、繼承和多型?
- 什么時候生成默認建構式(無參建構式)?什么時候生成默認拷貝建構式?什么是深拷貝?什么是淺拷貝?默認拷貝建構式是哪種拷貝?什么時候用深拷貝?
- 建構式和解構式的執行順序?
- C++的編譯環境
- 說一下static關鍵字的作用?
- 說一下const關鍵字的作用?
- 請說一下extern關鍵字的作用?
- 說一下C++和C的區別
- 說一說 c++ 中四種強轉型別轉換,
- 為什么不使用 C 的強制轉換?
- 請說一下C/C++中指標和參考概念及其區別?
- 請你說一下你理解的 c++ 中的四個智能指標,
- 請回答一下陣列和指標的區別,
- 請你回答一下野指標是什么?
- 請你回答一下智能指標有沒有記憶體泄露的情況
- 請你來說一下智能指標的記憶體泄漏如何解決
- 請你回答一下為什么解構式必須是虛函式?為什么 C++ 默認的解構式不是虛函式(考點: 虛函式 解構式)
- 請你來說一下函式指標
- 請你來說一下 fork 函式
- 請你來說一下C++中解構式的作用
- 請你來說一下靜態函式和虛函式的區別
- 請你來說一說多載和覆寫,
- 請你說一說 strcpy 和 和 strlen,
- 請你來回答一下++i 和 i++,
- 請你說一說你理解的虛函式和多型,
- 請你來說一說++i 和 i++ 的實作,
- 請你來寫個函式在main函式執行前先運行,
- 以下四行代碼的區別是什么?
- 請你來說一下C++里是怎么定義常量的?常量存放在記憶體的哪個位置?
- 請你來說一說隱式型別轉換,
- 請你來說一說 C++函式堆疊空間的最大值
- 請你來說一說 extern "C"
- 請你回答一下 new/delete與 與 malloc/free 的區別,
- * 請你說說你了解的RTTI
- 請你說說虛函式表具體是怎樣實作運行時多型的?
- 請你說說 C 語言中是怎么進行函式呼叫的?
- 請你說說C語言引數壓堆疊順序?
- 請你說說C++如何處理回傳值?
- 請你回答一下C++中拷貝建構式的形參能否進行值傳遞?
- 請你回答一下malloc與new的區別,
- 請你說一說select,
- 請你說說 fork,wait,exec 函式,
- 請你來說一下map和set有什么區別,分別又是怎么實作的?
- 請你來介紹一下STL的allocator(空間配置器)
- 請你講講 STL 有什么基本組成?他們之間的關系是怎樣的?
- 請你說一說STL中map資料的存放形式,
- 請你說說STL中map與unordered_map
- 請你說一說vector和list的區別、應用,越詳細越好
- 請你來說一下一個 C++ 源檔案從文本到可執行檔案經歷的程序?
- 請你來回答一下include頭檔案的順序以及雙引號" "和尖括號< > 的區別,
- 什么是紅黑樹?
C/C++記憶體有哪幾種型別?
- 堆(malloc)
- 堆疊(如區域變數、函式引數)
- 程式代碼區(存放二進制代碼)
- 全域/靜態存盤區(全域變數、static變數)和常量存盤區(常量),此外,C++中有自由存盤區(new)一說,
- 全域變數、static變數會初始化為零,而堆和堆疊上的變數是隨機的,不確定的,
堆和堆疊的區別?
- 堆存放動態分配的物件——即那些在程式運行時分配的物件,比如區域變數,其生存期由程式控制;
- 堆疊用來保存定義在函式內的非static物件,僅在其定義的程式塊運行時才存在;
- 靜態記憶體用來保存static物件,類static資料成員以及定義在任何函式外部的變數,static物件在使用之前分配,程式結束時銷毀;
- 堆疊和靜態記憶體的物件由編譯器自動創建和銷毀,
堆和自由存盤區的區別?
- 總的來說,堆是C語言和作業系統的術語,是作業系統維護的一塊動態分配記憶體;自由存盤是C++中通過new與delete動態分配和釋放物件的抽象概念,他們并不是完全一樣,
- 從技術上來說,堆(heap)是C語言和作業系統的術語,堆是作業系統所維護的一塊特殊記憶體,它提供了動態分配的功能,當運行程式呼叫malloc()時就會從中分配,稍后呼叫free可把記憶體交還,
- 而自由存盤是C++中通過new和delete動態分配和釋放物件的抽象概念,通過new來申請的記憶體區域可稱為自由存盤區,基本上,所有的C++編譯器默認使用堆來實作自由存盤,也即是預設的全域運算子new和delete也許會按照malloc和free的方式來被實作,這時藉由new運算子分配的物件,說它在堆上也對,說它在自由存盤區上也正確,
程式編譯的程序?
- 程式編譯的程序中就是將用戶的文本形式的源代碼(c/c++)轉化成計算機可以直接執行的機器代碼的程序,主要經過四個程序:預處理、編譯、匯編和鏈接,具體示例如下,
- 一個hello.c的c語言程式如下,
- 預處理階段:hello.c–>hello.i
- 編譯階段:hello.i–>hello.s
- 匯編階段:hello.s–>hello.o
- 鏈接階段:hello.o–>hello
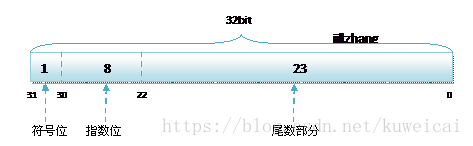
計算機內部如何存盤負數和浮點數?
- 負數比較容易,就是通過一個標志位和補碼來表示,
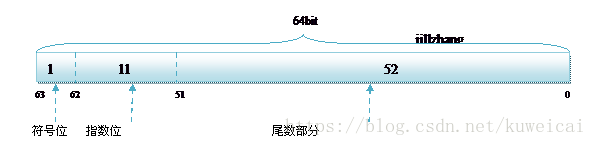
- 對于浮點型別的資料采用單精度型別(float)和雙精度型別(double)來存盤,float資料占用32bit,double資料占用64bit,我們在宣告一個變數float f= 2.25f的時候,是如何分配記憶體的呢?如果胡亂分配,那世界豈不是亂套了么,其實不論是float還是double在存盤方式上都是遵從IEEE的規范的,float遵從的是IEEE R32.24 ,而double 遵從的是R64.53,更多可以參考浮點數表示,
- 無論是單精度還是雙精度在存盤中都分為三個部分:
- 符號位(Sign) : 0代表正,1代表為負
- 指數位(Exponent):用于存盤科學計數法中的指數資料,并且采用移位存盤
- 尾數部分(Mantissa):尾數部分
其中float的存盤方式如下圖所示:
而雙精度的存盤方式如下圖:
函式呼叫的程序?
如下結構的代碼,
int main(void)
{
...
d = fun(a, b, c);
cout<<d<<endl;
...
return 0;
}
呼叫fun()的程序大致如下:
- main()========
- 引數拷貝(壓堆疊),注意順序是從右到左,即c-b-a;
- 保存d = fun(a, b, c)的下一條指令,即cout<<d<<endl(實際上是這條陳述句對應的匯編指令的起始位置);
- 跳轉到fun()函式,注意,到目前為止,這些都是在main()中進行的;
- fun()=====
- 移動ebp、esp形成新的堆疊幀結構;
- 壓堆疊(push)形成臨時變數并執行相關操作;
- return一個值;
- 出堆疊(pop);
- 恢復main函式的堆疊幀結構;
- 回傳main函式;
- main()========
左值和右值
- 不是很嚴謹的來說,左值指的是既能夠出現在等號左邊也能出現在等號右邊的變數(或運算式);右值指的則是只能出現在等號右邊的變數(或運算式),
- 舉例來說我們定義的變數 a 就是一個左值,而malloc回傳的就是一個右值,或者左值就是在程式中能夠尋址的東西,右值就是一個具體的真實的值或者物件,沒法取到它的地址的東西(不完全準確),因此沒法對右值進行賦值,但是右值并非是不可修改的,比如自己定義的class, 可以通過它的成員函式來修改右值,
什么是記憶體泄漏?面對記憶體泄漏和指標越界,你有哪些方法?你通常采用哪些方法來避免和減少這類錯誤?
用動態存盤分配函式動態開辟的空間,在使用完畢后未釋放,結果導致一直占據該記憶體單元即為記憶體泄露,
- 使用的時候要記得指標的長度.
- malloc的時候得確定在那里free.
- 對指標賦值的時候應該注意被賦值指標需要不需要釋放.
- 動態分配記憶體的指標最好不要再次賦值.
- 在C++中應該優先考慮使用智能指標.
C和C++的區別?
- C++是C的超集;
- C是一個結構化語言,它的重點在于演算法和資料結構,C程式的設計首要考慮的是如何通過一個程序,對輸入(或環境條件)進行運算處理得到輸出(或實作程序(事務)控制),而對于C++,首要考慮的是如何構造一個物件模型,讓這個模型能夠契合與之對應的問題域,這樣就可以通過獲取物件的狀態資訊得到輸出或實作程序(事務)控制,
int fun() 和 int fun(void)的區別?
- 這里考察的是c中的默認型別機制,在c中,int fun() 會解讀為回傳值為int(即使前面沒有int,也是如此,但是在c++中如果沒有回傳型別將報錯),輸入型別和個數沒有限制, 而int fun(void)則限制輸入型別為一個void,
- 在c++下,這兩種情況都會解讀為回傳int型別,輸入void型別,
const 有什么用途
- 定義只讀變數,或者常量(只讀變數和常量的區別參考下面一條);
- 修飾函式的引數和函式的回傳值;
- 修飾函式的定義體,這里的函式為類的成員函式,被const修飾的成員函式代表不能修改成員變數的值,因此const成員函式只能呼叫const成員函式;
- 只讀物件,只讀物件只能呼叫const成員函式,
class Screen {
public:
const char cha; //const成員變數
char get() const; //const成員函式
};
const Screen screen; //只讀物件
在C中用const能定義真正意義上的常量嗎?C++中的const呢?
不能,c中的const僅僅是從編譯層來限定,不允許對const 變數進行賦值操作,在運行期是無效的,所以并非是真正的常量(比如通過指標對const變數是可以修改值的),但是c++中是有區別的,c++在編譯時會把const常量加入符號表,以后(仍然在編譯期)遇到這個變數會從符號表中查找,所以在C++中是不可能修改到const變數的,
- c中的區域const常量存盤在堆疊空間,全域const常量存在只讀存盤區,所以全域const常量也是無法修改的,它是一個只讀變數,
- 這里需要說明的是,常量并非僅僅是不可修改,而是相對于變數,它的值在編譯期已經決定,而不是在運行時決定,
- c++中的const 和宏定義是有區別的,宏是在預編譯期直接進行文本替換,而const發生在編譯期,是可以進行型別檢查和作用域檢查的,
- c語言中只有enum可以實作真正的常量,
- c++中只有用字面量初始化的const常量會被加入符號表,而變數初始化的const常量依然只是只讀變數,
- c++中const成員為只讀變數,可以通過指標修改const成員的值,另外const成員變數只能在初始化串列中進行初始化,
下面我們通過代碼來看看區別,同樣一段代碼,在c編譯器下,列印結果為*pa = 4, 4;在c++編譯下列印的結果為 *pa = 4, 8
int main(void)
{
const int a = 8;
int *pa = (int *)&a;
*pa = 4;
printf("*pa = %d, a = %d", *pa, a);
return 0;
}
另外值得一說的是,由于c++中const常量的值在編譯期就已經決定,下面的做法是OK的,但是c中是編譯通不過的,
int main(void)
{
const int a = 8;
const int b = 2;
int array[a+b] = {0};
return 0;
}
宏和行內(inline)函式的比較?
- 首先宏是C中引入的一種預處理功能;
- 行內(inline)函式是C++中參考的一個新的關鍵字;C++中推薦使用行內函式來替代宏代碼片段;
- 行內函式將函式體直接擴展到呼叫行內函式的地方,這樣減少了引數壓堆疊,跳轉,回傳等程序;
- 由于行內發生在編譯階段,所以行內相較宏,是有引數檢查和回傳值檢查的,因此使用起來更為安全;
- 需要注意的是, inline會向編譯期提出行內請求,但是是否行內由編譯期決定(當然可以通過設定編譯器,強制使用行內);
- 由于行內是一種優化方式,在某些情況下,即使沒有顯示的宣告行內,比如定義在class內部的方法,編譯器也可能將其作為行內函式,
- 行內函式不能過于復雜,最初C++限定不能有任何形式的回圈,不能有過多的條件判斷,不能對函式進行取地址操作等,但是現在的編譯器幾乎沒有什么限制,基本都可以實作行內,
C++中有了malloc / free , 為什么還需要 new / delete?
-
malloc與free是C++/C語言的標準庫函式,new/delete是C++的運算子,它們都可用于申請動態記憶體和釋放記憶體,
-
對于非內部資料型別的物件而言,光用maloc/free無法滿足動態物件的要求,物件在創建的同時要自動執行建構式,物件在消亡之前要自動執行解構式,
-
由于malloc/free是庫函式而不是運算子,不在編譯器控制權限之內,不能夠把執行建構式和解構式的任務強加于malloc/free,因此C++語言需要一個能完成動態記憶體分配和初始化作業的運算子new,以一個能完成清理與釋放記憶體作業的運算子delete,注意new/delete不是庫函式,最后補充一點體外話,new 在申請記憶體的時候就可以初始化(如下代碼), 而malloc是不允許的,另外,由于malloc是庫函式,需要相應的庫支持,因此某些簡易的平臺可能不支持,但是new就沒有這個問題了,因為new是C++語言所自帶的運算子,
int *p = new int(1);
- 特別的,在C++中,如下的代碼,用new創建一個物件(new 會觸發建構式, delete會觸發解構式),但是malloc僅僅申請了一個空間,所以在C++中引入new和delete來支持面向物件,
#include <cstdlib>
class Test
{
...
}
Test* pn = new Test;
Test* pm = (Test*)malloc(sizeof(Test));
C和C++中的強制型別轉換?
C中是直接在變數或者運算式前面加上(小括號括起來的)目標型別來進行轉換,一招走天下,操作簡單,但是由于太過直接,缺少檢查,因此容易發生編譯檢查不到錯誤,而人工檢查又及其難以發現的情況;而C++中引入了下面四種轉換:
- static_cast
- 用于基本型別間的轉換
- 不能用于基本型別指標間的轉換
- 用于有繼承關系類物件間的轉換和類指標間的轉換
- dynamic_cast
- 用于有繼承關系的類指標間的轉換
- 用于有交叉關系的類指標間的轉換
- 具有型別檢查的功能
- 需要虛函式的支持
- reinterpret_cast
- 用于指標間的型別轉換
- 用于整數和指標間的型別轉換
- const_cast
- 用于去掉變數的const屬性
- 轉換的目標型別必須是指標或者參考
在C++中,普通型別可以通過型別轉換建構式轉換為型別別,那么類可以轉換為普通型別嗎?答案是肯定的,但是在工程應用中一般不用型別轉換函式,因為無法抑制隱式的呼叫型別轉換函式(型別轉換建構式可以通過explicit來抑制其被隱式的呼叫),而隱式呼叫經常是bug的來源,實際工程中替代的方式是定義一個普通函式,通過顯式的呼叫來達到型別轉換的目的,
class test{
int m_value;
...
public:
operator int() //型別轉換函式
{
return m_value;
}
int toInt() //顯示呼叫普通函式來實作型別轉換
{
return m_value
}
};
int main()
{
...
test a(5);
int i = a;
...
return 0;
}
static有什么用途
- 靜態(區域/全域)變數
- 靜態函式
- 類的靜態資料成員
- 類的靜態成員函式
類的靜態成員變數和靜態成員函式各有哪些特性?
- 靜態成員變數
- 靜態成員變數需要在類內宣告(加static),在類外初始化(不能加static),如下例所示;
- 靜態成員變數在類外單獨分配存盤空間,位于全域資料區,因此靜態成員變數的生命周期不依賴于類的某個物件,而是所有類的物件共享靜態成員變數;
- 可以通過物件名直接訪問公有靜態成員變數;
- 可以通過類名直接呼叫公有靜態成員變數,即不需要通過物件,這一點是普通成員變數所不具備的,
class example{
private:
static int m_int; //static成員變數
};
int example::m_int = 0; //沒有static
cout<<example::m_int; //可以直接通過類名呼叫靜態成員變數
- 靜態成員函式
- 靜態成員函式是類所共享的;
- 靜態成員函式可以訪問靜態成員變數,但是不能直接訪問普通成員變數(需要通過物件來訪問);需要注意的是普通成員函式既可以訪問普通成員變數,也可以訪問靜態成員變數;
- 可以通過物件名直接訪問公有靜態成員函式;
- 可以通過類名直接呼叫公有靜態成員函式,即不需要通過物件,這一點是普通成員函式所不具備的,
class example{
private:
static int m_int_s; //static成員變數
int m_int;
static int getI() //靜態成員函式在普通成員函式前加static即可
{
return m_int_s; //如果回傳m_int則報錯,但是可以return d.m_int是合法的
}
};
cout<<example::getI(); //可以直接通過類名呼叫靜態成員變數
在C++程式中呼叫被C編譯器編譯后的函式,為什么要加extern“C”?
C++語言支持函式多載,C語言不支持函式多載,函式被C++編譯器編譯后在庫中的名字與C語言的不同,假設某個函式原型為:
void foo(int x, int y);
該函式被C編譯器編譯后在庫中的名字為 _foo, 而C++編譯器則會產生像: _foo_int_int 之類的名字,為了解決此類名字匹配的問題,C++提供了C鏈接交換指定符號 extern “C”,
頭檔案中的ifndef/define/endif是干什么用的? 該用法和program once的區別?
相同點:它們的作用是防止頭檔案被重復包含,
不同點:
- ifndef 由語言本身提供支持,但是program once一般由編譯器提供支持,也就是說,有可能出現編譯器不支持的情況(主要是比較老的編譯器),
- 通常運行速度上 ifndef 一般慢于program once,特別是在大型專案上,區別會比較明顯,所以越來越多的編譯器開始支持program once,
- fndef 作用于某一段被包含(define 和 endif 之間)的代碼, 而 program once 則是針對包含該陳述句的檔案, 這也是為什么 program once 速度更快的原因,
- 如果用 ifndef 包含某一段宏定義,當這個宏名字出現“撞車”時,可能會出現這個宏在程式中提示宏未定義的情況(在撰寫大型程式時特性需要注意,因為有很多程式員在同時寫代碼),相反由于program once 針對整個檔案, 因此它不存在宏名字“撞車”的情況, 但是如果某個頭檔案被多次拷貝,program once 無法保證不被多次包含,因為program once 是從物理上判斷是不是同一個頭檔案,而不是從內容上,
當i是一個整數的時候++i和i++那個更快一點?i++和++i的區別是什么?
答:理論上++i更快,實際與編譯器優化有關,通常幾乎無差別,
//i++實作代碼為:
int operator++(int)
{
int temp = *this;
++*this;
return temp;
}//回傳一個int型的物件本身
// ++i實作代碼為:
int& operator++()
{
*this += 1;
return *this;
}//回傳一個int型的物件參考
i++和++i的考點比較多,簡單來說,就是i++回傳的是i的值,而++i回傳的是i+1的值,也就是++i是一個確定的值,是一個可修改的左值,如下使用:
cout << ++(++(++i)) << endl;
cout << ++ ++i << endl;
可以不停的嵌套++i,這里有很多的經典筆試題,一起來觀摩下:
int main()
{
int i = 1;
printf("%d,%d\n", ++i, ++i); //3,3
printf("%d,%d\n", ++i, i++); //5,3
printf("%d,%d\n", i++, i++); //6,5
printf("%d,%d\n", i++, ++i); //8,9
system("pause");
return 0;
}
首先是函式的引數入堆疊順序從右向左入堆疊的,計算順序也是從右往左計算的,不過都是計算完以后再進行的壓堆疊操作:
- 對于第1個printf,首先執行++i,回傳值是i,這時i的值是2,再次執行++i,回傳值是i,得到i=3,將i壓入堆疊中,此時i為3,也就是壓入3,3;
- 對于第2個printf,首先執行i++,回傳值是原來的i,也就是3,再執行++i,回傳值是i,依次將3,5壓入堆疊中得到輸出結果
- 對于第3個printf,首先執行i++,回傳值是5,再執行i++回傳值是6,依次將5,6壓入堆疊中得到輸出結果
- 對于第4個printf,首先執行++i,回傳i,此時i為8,再執行i++,回傳值是8,此時i為9,依次將i,8也就是9,8壓入堆疊中,得到輸出結果,
上面的分析也是基于VS搞的,不過準確來說函式多個引數的計算順序是未定義的(the order of evaluation of function arguments are undefined),筆試題目的運行結果隨不同的編譯器而異,
指標和參考的區別?
相同點:
- 都是地址的概念;
- 都是“指向”一塊記憶體,指標指向一塊記憶體,它的內容是所指記憶體的地址;而參考則是某塊記憶體的別名;
- 參考在內部實作其實是借助指標來實作的,一些場合下參考可以替代指標,比如作為函式形參,
不同點:
- 指標是一個物體,而參考(看起來,這點很重要)僅是個別名;
- 參考只能在定義時被初始化一次,之后不可變;指標可變;參考“從一而終”,指標可以“見異思遷”;
- 參考不能為空,指標可以為空;
- “sizeof 參考”得到的是所指向的變數(物件)的大小,而“sizeof 指標”得到的是指標本身的大小;
- 指標和參考的自增(++)運算意義不一樣;
- 參考是型別安全的,而指標不是 (參考比指標多了型別檢查)
- 參考具有更好的可讀性和實用性,
參考占用記憶體空間嗎?
如下代碼中對參考取地址,其實是取的參考所對應的記憶體空間的地址,這個現象讓人覺得參考好像并非一個物體,但是參考是占用記憶體空間的,而且其占用的記憶體和指標一樣,因為參考的內部實作就是通過指標來完成的,
比如 Type& name; <===> Type* const name,
int main(void)
{
int a = 8;
const int &b = a;
int *p = &a;
*p = 0;
cout<<a; //output 0
return 0;
}
三目運算子
在C中三目運算子(? :)的結果僅僅可以作為右值,比如如下的做法在C編譯器下是會報錯的,但是C++中卻是可以是通過的,這個進步就是通過參考來實作的,因為下面的三目運算子的回傳結果是一個參考,然后對參考進行賦值是允許的,
int main(void)
{
int a = 8;
int b = 6;
(a>b ? a : b) = 88;
cout<<a; //output 88
return 0;
}
指標陣列和陣列指標的區別
- 陣列指標,是指向陣列的指標,而指標陣列則是指該陣列的元素均為指標,
- 陣列指標,是指向陣列的指標,其本質為指標,形式如下,如
int (*p)[10],p即為指向陣列的指標,()優先級高,首先說明p是一個指標,指向一個整型的一維陣列,這個一維陣列的長度是n,也可以說是p的步長,也就是說執行p+1時,p要跨過n個整型資料的長度,陣列指標是指向陣列首元素的地址的指標,其本質為指標,可以看成是二級指標,
型別名 (*陣列識別符號)[陣列長度]
指標陣列,在C語言和C++中,陣列元素全為指標的陣列稱為指標陣列,其中一維指標陣列的定義形式如下,指標陣列中每一個元素均為指標,其本質為陣列,如int *p[n], []優先級高,先與p結合成為一個陣列,再由int*說明這是一個整型指標陣列,它有n個指標型別的陣列元素,這里執行p+1時,則p指向下一個陣列元素,這樣賦值是錯誤的:p=a;因為p是個不可知的表示,只存在p[0]、p[1]、p[2]…p[n-1],而且它們分別是指標變數可以用來存放變數地址,但可以這樣*p=a; 這里*p表示指標陣列第一個元素的值,a的首地址的值,
型別名 *陣列識別符號[陣列長度]
什么是面向物件(OOP)?面向物件的意義?
- Object Oriented Programming, 面向物件是一種對現實世界理解和抽象的方法、思想,通過將需求要素轉化為物件進行問題處理的一種思想,其核心思想是資料抽象、繼承和動態系結(多型),
- 面向物件的意義在于:將日常生活中習慣的思維方式引入程式設計中;將需求中的概念直觀的映射到解決方案中;以模塊為中心構建可復用的軟體系統;提高軟體產品的可維護性和可擴展性,
解釋下封裝、繼承和多型?
- 封裝:
封裝是實作面向物件程式設計的第一步,封裝就是將資料或函式等集合在一個個的單元中(我們稱之為類),封裝的意義在于保護或者防止代碼(資料)被我們無意中破壞, - 繼承:
繼承主要實作重用代碼,節省開發時間,
子類可以繼承父類的一些東西,- 公有繼承(public)
公有繼承的特點是基類的公有成員和保護成員作為派生類的成員時,它們都保持原有的狀態,而基類的私有成員仍然是私有的,不能被這個派生類的子類所訪問, - 私有繼承(private)
私有繼承的特點是基類的公有成員和保護成員都作為派生類的私有成員,并且不能被這個派生類的子類所訪問, - 保護繼承(protected)
保護繼承的特點是基類的所有公有成員和保護成員都成為派生類的保護成員,并且只能被它的派生類成員函式或友元訪問,基類的私有成員仍然是私有的,
- 公有繼承(public)
- 多型
什么時候生成默認建構式(無參建構式)?什么時候生成默認拷貝建構式?什么是深拷貝?什么是淺拷貝?默認拷貝建構式是哪種拷貝?什么時候用深拷貝?
- 沒有任何建構式時,編譯器會自動生成默認建構式,也就是無參建構式;當類沒有拷貝建構式時,會生成默認拷貝建構式,
- 深拷貝是指拷貝后物件的邏輯狀態相同,而淺拷貝是指拷貝后物件的物理狀態相同;默認拷貝建構式屬于淺拷貝,
- 當系統中有成員指代了系統中的資源時,需要深拷貝,比如指向了動態記憶體空間,打開了外存中的檔案或者使用了系統中的網路介面等,如果不進行深拷貝,比如動態記憶體空間,可能會出現多次被釋放的問題,是否需要定義拷貝建構式的原則是,是類是否有成員呼叫了系統資源,如果定義拷貝建構式,一定是定義深拷貝,否則沒有意義,
建構式和解構式的執行順序?
建構式
- 首先呼叫父類的建構式;
- 呼叫成員變數的建構式;
- 呼叫類自身的建構式,
解構式
對于堆疊物件或者全域物件,呼叫順序與建構式的呼叫順序剛好相反,也即后構造的先析構,對于堆物件,析構順序與delete的順序相關,
C++的編譯環境
如下圖所示,C++的編譯環境由如下幾部分構成:C++標準庫、C語言兼容庫、編譯器擴展庫及編譯模塊,
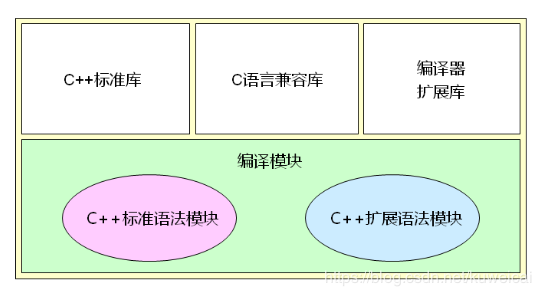
#include<iostream> //C++標準庫,不帶".h"
#include<string.h> //C語言兼容庫,由編譯器廠商提供
值得注意的是,C語言兼容庫功能上跟C++標準庫中的C語言子庫相同,它的存中主要為了兼容C語言編譯器,也就是說如果一個檔案只包含C語言兼容庫(不包含C++標準庫),那么它在C語言編譯器中依然可以編譯通過,
說一下static關鍵字的作用?
- 全域靜態變數
- 在全域變數前加上關鍵字 static,全域變數就定義成一個全域靜態變數,
- 記憶體中位置:靜態存盤區,在整個程式運行期間一直存在,
- 初始化:未經初始化的全域靜態變數會被自動初始化為0(自動物件的值是任意的,除非他被顯式初始化);
- 作用域:全域靜態變數在宣告他的檔案之外是不可見的,準確地說是從定義之處開始,到檔案結尾,
- 區域靜態變數
- 在區域變數之前加上關鍵字static,區域變數就成為一個區域靜態變數,
- 記憶體中的位置:靜態存盤區
- 初始化:未經初始化的區域靜態變數會被自動初始化為0(自動物件的值是任意的,除非他被顯式初始化);
- 作用域:作用域仍為區域作用域,當定義它的函式或者陳述句塊結束的時候,作用域結束,但是當區域靜態變數離開作用域后,并沒有銷毀,而是仍然駐留在記憶體當中,只不過我們不能再對它進行訪問,直到該函式再次被呼叫,并且值不變;
- 靜態函式
- 在函式回傳型別前加static,函式就定義為靜態函式,函式的定義和宣告在默認情況下都是extern的,但靜態函式只是在宣告他的檔案當中可見,不能被其他檔案所用,
- 函式的實作使用static修飾,那么這個函式只可在本cpp內使用,不會同其他cpp中的同名函式引起沖突;
- 注意:不要在頭檔案中宣告static的全域函式,不要在cpp內宣告非static的全域函式,如果你要在多個cpp中復用該函式,就把它的宣告提到頭檔案里去,否則cpp內部宣告需加上static修飾;
- 類的靜態成員
- 在類中,靜態成員可以實作多個物件之間的資料共享,并且使用靜態資料成員還不會破壞隱藏的原則,即保證了安全性,因此,靜態成員是類的所有物件中共享的成員,而不是某個物件的成員,對多個物件來說,靜態資料成員只存盤一處,供所有物件共用,
- 類的靜態函式
- 靜態成員函式和靜態資料成員一樣,它們都屬于類的靜態成員,它們都不是物件成員,因此,對靜態成員的參考不需要用物件名,
在靜態成員函式的實作中不能直接參考類中說明的非靜態成員,可以參考類中說明的靜態成員(這點非常重要),如果靜態成員函式中要參考非靜態成員時,可通過物件來參考,
從中可看出,呼叫靜態成員函式使用如下格式:<類名>::<靜態成員函式名>(<引數表>);
簡潔回答:(推薦)
- 加了static 關鍵字的全域變數只能在本檔案中使用,
- 例如在 a.c 中定義了
static int a=10;那么在 b.c 中用extern int a 是拿不到 a 的值得,a 的作用域只在 a.c 中, - static定義的靜態區域變數分配在資料段上,普通的區域變數分配在堆疊上,會因為函式堆疊幀的釋放而被釋放掉,
- 對一個類中成員變數和成員函式來說,加了 static 關鍵字,則此變數/函式就沒有了 this 指標了,必須通過類名才能訪問
說一下const關鍵字的作用?

請說一下extern關鍵字的作用?
- extern修飾變數的宣告,舉例來說,如果檔案a.c需要參考b.c中變數int v,就可以在a.c中宣告extern int v,然后就可以參考變數v,這里需要注意的是,被參考的變數v的鏈接屬性必須是外鏈接(external)的,也就是說a.c要參考到v,不只是取決于在a.c中宣告extern int v,還取決于變數v本身是能夠被參考到的,這涉及到c語言的另外一個話題--變數的作用域,能夠被其他模塊以extern修飾符參考到的變數通常是全域變數,還有很重要的一點是,extern int v可以放在a.c中的任何地方,比如你可以在a.c中的函式fun定義的開頭處宣告extern int v,然后就可以參考到變數v了,只不過這樣只能在函式fun作用域中參考v罷了,這還是變數作用域的問題,對于這一點來說,很多人使用的時候都心存顧慮,好像extern宣告只能用于檔案作用域似的,
- extern修飾函式宣告,從本質上來講,變數和函式沒有區別,函式名是指向函式二進制塊開頭處的指標,如果檔案a.c需要參考b.c中的函式,比如在b.c中原型是int fun(int mu),那么就可以在a.c中宣告extern int fun(int mu),然后就能使用fun來做任何事情,就像變數的宣告一樣,extern int fun(int mu)可以放在a.c中任何地方,而不一定非要放在a.c的檔案作用域的范圍中,對其他模塊中函式的參考,最常用的方法是包含這些函式宣告的頭檔案,
- 此外,extern修飾符可用于指示C或者C++函式的呼叫規范,比如在C++中呼叫C庫函式,就需要在C++程式中用extern “C”宣告要參考的函式,這是給聯結器用的,告訴聯結器在鏈接的時候用C函式規范來鏈接,主要原因是C++和C程式編譯完成后在目標代碼中命名規則不同,
說一下C++和C的區別
- 設計思想上
- C++是面向物件的語言,而C是面向程序的結構化編程語言,
- 語法上
- C++具有多載、繼承和多型三種特性,
- C++相比C,增加多許多型別安全的功能,比如強制型別轉換,
- C++支持范式編程,比如模板類、函式模板等,
說一說 c++ 中四種強轉型別轉換,
C++中四種型別轉換是:static_cast、dynamic_cast、const_cast、reinterpret_cast,
- const_cast
- 一般用于指標轉換,
- 可以將 const 指標轉為非 const 指標,
- 可以將const參考轉換為非const參考,
- static_cast
- 用于各種隱式轉換,轉換之前,要先將型別轉換為void*,再轉換成其他型別,比如非 const 轉 const,void*轉指標等, static_cast 能用于多型向上轉化,如果向下轉能成功但是不安全,結果未知,因為沒有動態型別檢查;
- dynamic_cast
- 用于動態型別轉換,只能用于含有虛函式的類,用于類層次間的向上和向下轉化,只能轉指標或參考,向下轉化時,如果是非法的對于指標回傳 NULL,對于參考拋例外,
- 向上轉換:指的是子類向基類的轉換
- 向下轉換:指的是基類向子類的轉換
- 它通過判斷在執行到該陳述句的時候變數的運行時型別和要轉換的型別是否相同來判斷是否能夠進行向下轉換,
- reinterpret_cast
- 幾乎什么都可以轉,比如將 int 轉指標,可能會出問題,盡量少用;
為什么不使用 C 的強制轉換?
C的強制轉換表面上看起來功能強大什么都能轉,但是轉化不夠明確,不能進行錯誤檢查,容易出錯,
請說一下C/C++中指標和參考概念及其區別?
- 參考
- 參考就是 C++對 C語言的重要擴充,參考就是某一變數的一個別名,對參考的操作與對變數直接操作完全一樣,
- 參考的宣告方法:型別識別符號 &參考名=目標變數名;
- 參考引入了物件的一個同義詞,定義參考的表示方法與定義指標相似,只是用&代替了*,
- 參考使用注意事項:
- 參考必須被初始化;
- 參考不能改變系結的物件;
- 指標
- 指標利用地址,它的值直接指向存在電腦存盤器中另一個地方的值,由于通過地址能找到所需的變數單元,可以說,地址指向該變數單元,因此,將地址形象化的稱為“指標”,意思是通過它能找到以它為地址的記憶體單元,
- 指標使用注意事項:
- 初始化時要置空;
- 使用時要考慮指向物件邊界問題;
- 不能對未初始化的指標取值或賦值;
- 釋放時要置空;
- 如果回傳動態分配記憶體或物件,必須使用指標;
區別:
- 指標是一個物體,需要分配記憶體空間,參考只是變數的別名,不需要分配記憶體空間;
- 使用 sizeof 看一個指標的大小是 4,而參考則是被參考物件的大小;
- 指標可以被初始化為 NULL,而參考必須被初始化且必須是一個已有物件的參考;
- 作為引數傳遞時,指標需要被解參考才可以對物件進行操作,而直接對參考的修改都會改變參考所指向的物件;
- 指標在使用中可以指向其它物件,但是參考只能是一個物件的參考,不能被改變;
- 指標可以有多級指標(**p),而參考至多一級;
- 指標和參考使用自增運算子的意義不一樣;(指標是指向下一個空間,參考時參考的變數值加1)
- 如果回傳動態記憶體分配的物件或者記憶體,必須使用指標,參考可能引起記憶體泄露,
請你說一下你理解的 c++ 中的四個智能指標,
- C++里面的四個智能指標: auto_ptr、shared_ptr、weak_ptr、unique_ptr(其中后三個是 c++11 支持,第一個已經被 11 棄用)
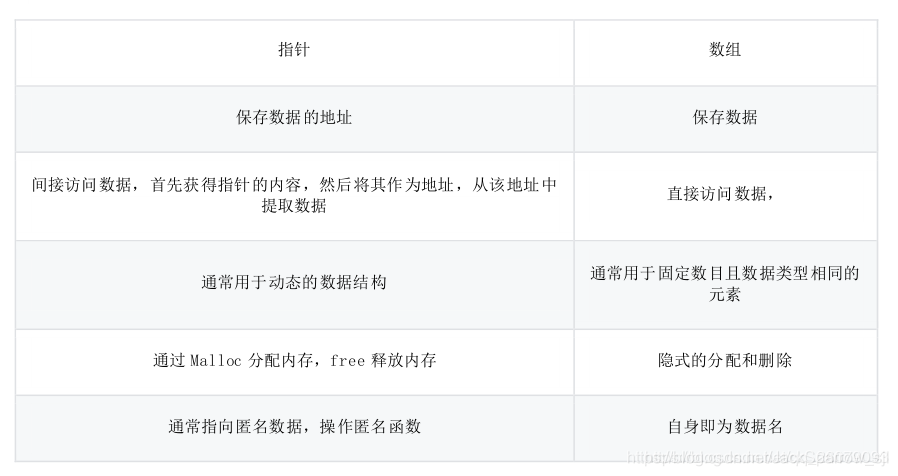
請回答一下陣列和指標的區別,
指標和陣列的主要區別如下:
請你回答一下野指標是什么?
野指標就是指向一個已釋放的記憶體或者無訪問權限的記憶體區域的指標,
請你回答一下智能指標有沒有記憶體泄露的情況
當兩個物件相互使用一個 shared_ptr 成員變數指向對方,會造成回圈參考,使參考計數失效,從而導致記憶體泄漏,
請你來說一下智能指標的記憶體泄漏如何解決
為了解決回圈參考導致的記憶體泄漏,引入了 weak_ptr 弱指標,weak_ptr 的建構式不會修改參考計數的值,從而不會對物件的記憶體進行管理,其類似一個普通指標,但不指向參考計數的共享記憶體,但是其可以檢測到所管理的物件是否已經被釋放,從而避免非法訪問,
請你回答一下為什么解構式必須是虛函式?為什么 C++ 默認的解構式不是虛函式(考點: 虛函式 解構式)
- 一般將基類的解構式設定為虛函式,當我們new一個子類物件,并用基類指標指向子類物件時,避免釋放基類指標后,而未釋放子類物件的空間,防止記憶體泄漏,
- 首先,默認的解構式所在的類一般不會被其他類繼承,而且虛函式需要額外的虛函式表和虛表指標,會占用額外的記憶體,所以默認建構式不是虛函式,
請你來說一下函式指標
- 定義:函式指標是一個指向函式首地址的指標變數,
C在編譯時,每一個函式都有一個人口地址,函式指標指向的就是這個人口地址,有了函式指標,可以通過指標來呼叫函式,就向指標陣列一樣, - 用途:
呼叫函式和做函式的引數,比如回呼函式, - 示例:
char* fun(char * p) {…}; // 普通函式 fun
char* (*pf)(char * p); // 函式指標 pf
pf = fun; // 函式指標 pf 指向函式 fun
pf(p); // 通過函式指標 pf 呼叫函式 fun
請你來說一下 fork 函式
fork:創建一個和當前行程映像一樣的行程可以通過 fork( )系統呼叫;
相關頭檔案:
#include <sys/types.h>
#include <unistd.h>
- 函式原型: pid_t fork(void);
- 成功呼叫 fork( )會創建一個新的行程,它幾乎與呼叫 fork( )的行程一模一樣,這兩個行程都會繼續運行,
回傳值:- 在子行程中,成功的 fork( )呼叫會回傳 0,
- 在父行程中 fork( )回傳子行程的 pid,
- 如果出現錯誤,fork( )回傳一個負值,
- 最常見的 fork( )用法是創建一個新的行程,然后使用 exec( )載入二進制映像,替換當前行程的映像,這種情況下,派生(fork)了新的行程,而這個子行程會執行一個新的二進制可執行檔案的映像,這種“派生加執行”的方式是很常見的,
- 在早期的 Unix 系統中,創建行程比較原始,當呼叫 fork 時,內核會把所有的內部資料結構復制一份,復制行程的頁表項,然后把父行程的地址空間中的內容逐頁的復制到子行程的地址空間中,但從內核角度來說,逐頁的復制方式是十分耗時的,現代的 Unix 系統采取了更多的優化,例如 Linux,采用了寫時復制的方法,而不是對父行程空間行程整體復制,
請你來說一下C++中解構式的作用
- 解構式與建構式對應,當物件結束其生命周期,如物件所在的函式已呼叫完畢時,系統會自動執行解構式,釋放動態開辟的記憶體空間,防止記憶體泄漏,
- 注: 類呼叫解構式順序:1)子類本身的解構式;2)物件成員解構式;3)基類解構式,
請你來說一下靜態函式和虛函式的區別
靜態函式在編譯的時候就已經確定運行時機(即編譯時確定函式的入口地址),虛函式在運行的時候動態系結,虛函式因為用了虛函式表機制,呼叫的時候會增加一次記憶體開銷,
請你來說一說多載和覆寫,
- 多載:其是對于一個類而言的,在類中,兩個函式的函式名相同,引數串列不同(引數型別或個數),回傳值無要求,
- 覆寫:前提是子類繼承父類,在父類中,有一個虛函式,然后在子類中重新定義了這個函式,這就構成了覆寫,
補充:
- 隱藏:前提也是子類繼承父類,分為兩種情況,
- 父類函式和子類函式名相同,但是引數不同,這時父類同名函式有無virtual修飾,都構成隱藏,即子類指標呼叫同名函式,呼叫的是子類的函式,父類函式被隱藏,
- 父類函式和子類函式名相同,引數也相同,且父類同名函式無virtual修飾,
請你說一說 strcpy 和 和 strlen,
- strcpy 是字串拷貝函式,原型:
char *strcpy(char* dest, const char *src); - 從src逐位元組拷貝到dest,直到遇到’\0’結束,因為沒有指定長度,可能會導致拷貝越界,造成緩沖區溢位漏洞,安全版本是 strncpy 函式,
- strlen 函式是計算字串長度的函式,回傳從開始到’\0’之間的字符個數,
請你來回答一下++i 和 i++,
++i先自增1,再回傳,i++先回傳i,再自增1,
請你說一說你理解的虛函式和多型,
- 多型的實作主要分為靜態多型和動態多型,靜態多型主要是多載,在編譯的時候就已經確定,靜態系結;動態多型是用虛
- 函式機制實作的,在運行期間動態系結,
- 舉個栗子:一個父型別別的指標指向一個子類物件時候,使用父類的指標去呼叫子類中重寫了的父類中的虛函式的時候,會呼叫子類重寫過后的函式,在父類中宣告為加了 virtual關鍵字的函式,在子類中重寫時候不需要加 virtual 也是虛函式,
- 虛函式的實作:在有虛函式的類中,類的最開始部分是一個虛函式表的指標,這個指標指向一個虛函式表,表中放了虛函式的地址,實際的虛函式在代碼段(.text)中,當子類繼承了父類的時候也會繼承其虛函式表,當子類重寫父類中虛函式時候,會將其繼承到的虛函式表中的地址替換為重新寫的函式地址,使用了虛函式,會增加訪問記憶體開銷,降低效率,
請你來說一說++i 和 i++ 的實作,
- ++i 的實作
int & int::operator++()
{
*this += 1;
return *this;
}
- i++的實作
const int int::operator(int)
{
int oldvalue = *this;
++(*this);
return oldvalue;
}
請你來寫個函式在main函式執行前先運行,
編譯器:VC++6.0
語言:C
代碼:
#include<stdio.h>
int main()
{
printf("main\n");
return 0;
}
int before_main()
{
printf("before_main\n");
return 0;
}
typedef int func();
#pragma data_seg(".CRT$XIU")//用#pragma data_seg建立一個新的資料段并定義共享資料
static func * before[] = { before_main }; //定義一個函式陣列,陣列放的是函式的入口地址
編譯器:VC++6.0
語言:C++
代碼:
#include<iostream>
using namespace std;
int before_main()
{
cout<<"before_main() called"<<endl;
return 0;
}
int g_Value = before_main();
int main()
{
cout<<"main() called"<<endl;
return 0;
}
以下四行代碼的區別是什么?
const char * arr ="123";
char * brr = "123";
const char crr[] ="123";
char drr[] = "123";
const char * arr = "123";
//字串 123 保存在常量區,const 本來是修飾 arr 指向的值不能通過 arr 去修改,但是字串"123"在常量區,本來就不能改變,所以加不加 const 效果都一樣,
char * brr = "123";
//字串 123 保存在常量區,這個 arr 指標指向的是同一個位置,同樣不能通過 brr 去修改"123"的值,
const char crr[] = "123";
//這里 123 本來是在堆疊上的,但是編譯器可能會做某些優化,將其放到常量區,
char drr[] = "123";
//字串 123 保存在堆疊區,可以通過 drr 去修改,
請你來說一下C++里是怎么定義常量的?常量存放在記憶體的哪個位置?
- 常量在 C++里的定義就是一個const 加上物件型別,常量定義必須初始化,
- 對于區域物件,常量存放在堆疊區,
- 對于全域物件,編譯期一般不分配記憶體,常量存放在全域/靜態存盤區,
- 對于字面值常量,比如字串,存放在常量存盤區,
請你來說一說隱式型別轉換,
首先,對于內置型別,低精度的變數給高精度變數賦值會發生隱式型別轉換,低精度型別會轉化為高精度型別,其次,對于只存在單個引數的建構式的物件構造來說,函式呼叫可以直接使用該引數傳入,編譯器會自動呼叫其建構式生成臨時物件,
請你來說一說 C++函式堆疊空間的最大值
Windows 默認是 2 M,不過可以調整,
Linux 默認是 8M,不過可以調整,
請你來說一說 extern “C”
C++呼叫 C函式需要 extern C,因為 C 語言沒有函式多載,
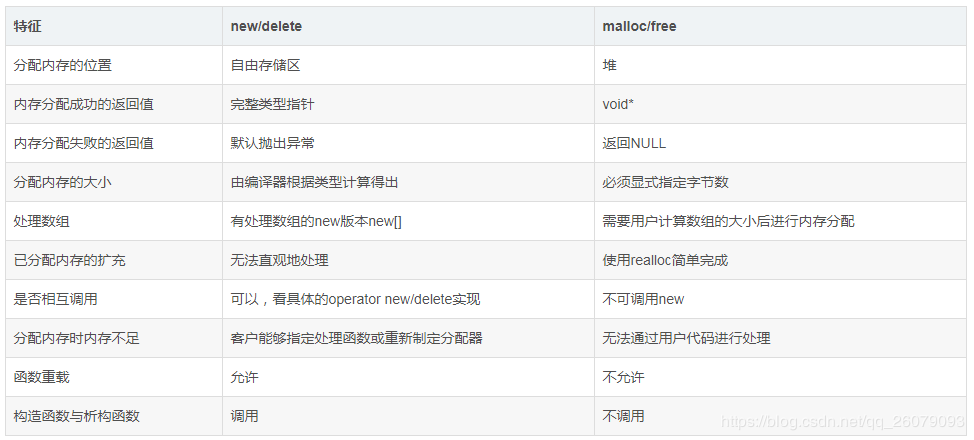
請你回答一下 new/delete與 與 malloc/free 的區別,
首先,new/delete 是 C++的關鍵字,而 malloc/free 是 C語言的庫函式,后者使用必須指明申請記憶體空間的大小,對于型別別的物件,后者不會呼叫建構式和解構式,
* 請你說說你了解的RTTI
RTTI (Run Time Type Identification) 指的是運行時型別識別,程式能夠使用基類的指標或引來檢查這些指標或參考所指的物件的實際派生型別,
RTTI提供了兩個非常有用的運算子:typeid 和 dynamic_cast,
- typeid運算子:回傳指標和參考所指的實際型別,回傳型別為 type_info,
關于 typeid 的注意事項:- typeid 回傳一個 type_info 的物件參考,
- 如果想通過基類的指標指向派生類的資料型別,基類就必須要帶有虛函式,否則,在使用typeid 時,就只能回傳定義時所使用的資料型別,
- typeid 只能獲取物件的實際型別,即便這個類含有虛函式,也只能判斷當前物件是基類還是派生類,而不能判斷當前指標是基類還是派生類,
- dynamic_cast運算子:將基型別別的指標或參考安全地轉換為其派生型別別的指標或參考,
關于 dynamic_cast 的注意事項:- 只能應用與指標和參考的轉換,即只能轉化為某一個型別的指標或某一個型別的參考,而不能是某型別本身,
- 要轉化的型別中必須包含虛函式,如果沒有虛函式,轉換就會失敗,
- 如果轉換成功,回傳子類的地址,如果轉換失敗,回傳NULL,
請你說說虛函式表具體是怎樣實作運行時多型的?
對于存在虛函式的基類的物件,基類物件的頭部存放指向虛函式表的指標,子類若重寫基類的虛函式,對應虛函式表中,該函式的地址會被重寫的子類函式的地址替換,
請你說說 C 語言中是怎么進行函式呼叫的?
每一個函式呼叫都會分配函式堆疊,在堆疊內進行函式執行程序,呼叫前,先把回傳地址壓堆疊,然后把當前函式的堆疊指標(ESP)壓堆疊,
請你說說C語言引數壓堆疊順序?
根據引數串列從右向左依次壓堆疊,
請你說說C++如何處理回傳值?
生成一個臨時變數,把它的參考作為函式引數傳入函式內,
請你回答一下C++中拷貝建構式的形參能否進行值傳遞?
不能,如果是值傳遞的話,呼叫拷貝建構式時,首先將實參傳給形參,這樣又會呼叫拷貝建構式,如此,會造成無限遞回呼叫拷貝建構式,
請你回答一下malloc與new的區別,
malloc:本身是一個函式,需要知道申請記憶體的大小,回傳的指標需要強轉,
new:本身不是函式,是一個關鍵字,不用指定申請記憶體大小,動態開辟空間,回傳指標不用強轉,
請你說一說select,
- 函式原型:int select ( int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout )
- select在使用前,先將需要監控的描述符對應的 bit 位置 1,然后將其傳給 select,當有任何一個事件發生時,select 將會回傳所有的描述符,需要在應用程式自己遍歷去檢查哪個描述符上有事件發生,效率很低,并且其不斷在內核態和用戶態進行描述符的拷貝,開銷很大,
- 補充:select總結
請你說說 fork,wait,exec 函式,
父行程產生子行程使用fork拷貝出來一個父行程的副本,此時只拷貝了父行程的頁表,兩個行程都讀同一塊記憶體,當有行程寫的時候使用寫實拷貝機制分配記憶體,exec 函式可以加載一個 elf 檔案去替換父行程,從此父行程和子行程就可以運行不同的程式了,fork 從父行程回傳子行程的 pid,從子行程回傳 0,呼叫了 wait 的父行程將會發生阻塞,直到有子行程狀態改變,執行成功回傳 0,錯誤回傳-1,exec 執行成功則子行程從新的程式開始運行,無回傳值,執行失敗回傳-1,
請你來說一下map和set有什么區別,分別又是怎么實作的?
實作機制:map 和 set 都是 C++的關聯容器,其底層實作都是紅黑樹(RB-Tree),由于 map 和 set 所開放的各種操作介面,RB-tree 也都提供了,所以幾乎所有的 map 和 set 的操作行為,都只是轉調 RB-tree 的操作行為,
map和set區別在于:
- map 中的元素是 key-value(關鍵字—值)對:關鍵字起到索引的作用,值則表示與索引相關聯的資料;set 與之相對就是關鍵字的簡單集合,set 中每個元素只包含一個關鍵字key,
- set 的迭代器是 const 的,不允許修改元素的值;map 允許修改 value,但不允許修改 key,其原因是因為map 和 set 是根據關鍵字排序來保證其有序性的,
- 對于set,如果允許修改 key 的話,那么首先需要洗掉該鍵,然后調節平衡,再插入修改后的鍵值,調節平衡,如此一來,嚴重破壞了 map 和 set 的結構,導致 iterator 失效,不知道應該指向改變前的位置,還是指向改變后的位置,所以 STL 中將 set 的迭代器設定成 const,不允許修改迭代器的值;
- 對于map,map 的迭代器則不允許修改 key 值,允許修改 value 值,
- map 支持下標操作,set 不支持下標操作,map 可以用 key 做下標,map 的下標運算子[ ]將關鍵碼作為下標去執行查找,如果關鍵碼不存在,則插入一個具有該關鍵碼和 mapped_type 型別默認值的元素至 map 中,因此下標運算子[ ]在 map 應用中需要慎用,const_map 不能用,只希望確定某一個關鍵值是否存在而不希望插入元素時也不應該使用,mapped_type 型別沒有默認值也不應該使用,如果 find 能解決需要,盡可能用 find,
請你來介紹一下STL的allocator(空間配置器)
- STL的空間配置器用于封裝STL容器在記憶體管理上的底層細節,在 C++中,其記憶體配置和釋放如下:
- new運算分兩個階段:
- 呼叫 operator new 配置記憶體;
- 呼叫物件建構式構造物件內容
- delete運算分兩個階段:
- 呼叫物件解構式;
- 呼叫operator delete 釋放記憶體
為了精密分工,STL allocator 將兩個階段操作區分開來:
- 記憶體配置由alloc::allocate()函式負責,記憶體釋放由alloc::deallocate()函式負責;
- 物件構造由::construct()函式負責,物件析構由::destroy()函式負責,
- 同時為了提升記憶體管理的效率,減少申請小記憶體造成的記憶體碎片問題,SGI STL 采用了兩級空間配置器,
- 當分配的空間大小超過 128B 時,會使用第一級空間配置器;
- 當分配的空間大小小于 128B 時,將使用第二級空間配置器,
- 第一級空間配置器直接使用 malloc()、realloc()、free()函式進行記憶體空間的分配和釋放,而第二級空間配置器采用了記憶體池技術,通過空閑鏈表來管理記憶體,
請你講講 STL 有什么基本組成?他們之間的關系是怎樣的?
- STL 主要由:以下六部分組成:
- 容器
- 迭代器
- 仿函式
- 演算法
- 分配器
- 配接器
- 他們之間的關系:
- 分配器:給容器分配存盤空間,
- 演算法:通過迭代器獲取容器中的內容,
- 仿函式:可以協助演算法完成各種操作,
- 配接器:用來套接適配仿函式,
請你說一說STL中map資料的存放形式,
對于map,資料以紅黑樹形式存放,
補充:
對于unordered_map,資料以哈希表形式存放,
請你說說STL中map與unordered_map
- Map映射,map 的所有元素都是pair,同時擁有鍵值(key)和實值(value),pair 的第一元素被視為鍵值,第二元素被視為實值,所有元素都會根據元素的鍵值自動被排序,不允許鍵值重復,
- 底層實作:紅黑樹
- 適用場景:有序鍵值對不重復映射
- Multimap
- 多重映射,multimap 的所有元素都是 pair,同時擁有實值(value)和鍵值(key),pair 的第一元素被視為鍵值,第二元素被視為實值,所有元素都會根據元素的鍵值自動被排序,允許鍵值重復,
- 底層實作:紅黑樹
- 適用場景:有序鍵值對可重復映射
請你說一說vector和list的區別、應用,越詳細越好
- 概念:
- Vector
- 連續存盤的容器,動態陣列,在堆上分配空間,
- 底層實作:陣列
- 兩倍容量增長:
- vector 增加(插入)新元素時,如果未超過當時的容量,則還有剩余空間,那么直接添加到最后(插入指定位置),然后調整迭代器,如果沒有剩余空間了,則會重新配置原有元素個數的兩倍空間,然后將原空間元素通過復制的方式初始化新空間,再向新空間增加元素,最后析構并釋放原空間,之前的迭代器會失效,
- 性能
- 訪問:O(1)
- 插入:在最后插入(空間夠):很快
- 在最后插入(空間不夠):需要記憶體申請和釋放,以及對之前資料進行拷貝,
- 在中間插入(空間夠):記憶體拷貝
- 在中間插入(空間不夠):需要記憶體申請和釋放,以及對之前資料進行拷貝,
- 洗掉:在最后洗掉:很快
- 在中間洗掉:記憶體拷貝
- 適用場景:經常隨機訪問,且不經常對非尾節點進行插入洗掉,
- List
- 動態鏈表,在堆上分配空間,每插入一個元數都會分配空間,每洗掉一個元素都會釋放空間,
- 底層:雙向鏈表
- 性能
- 訪問:隨機訪問性能很差,只能快速訪問頭尾節點,
- 插入:很快,一般是常數開銷
- 洗掉:很快,一般是常數開銷
- 適用場景:經常插入洗掉大量資料
- Vector
- 區別:
- vector 底層實作是陣列;list是雙向鏈表,
- vector 支持隨機訪問,list不支持,
- vector 是順序記憶體,list不是,
- vector 在中間節點進行插入洗掉會導致記憶體拷貝,list不會,
- vector 一次性分配好記憶體,不夠時才進行2倍擴容;list每次插入新節點都會進行記憶體申請,
- vector 隨機訪問性能好,插入洗掉性能差;list 隨機訪問性能差,插入洗掉性能好,
- 應用
- vector 擁有一段連續的記憶體空間,因此支持隨機訪問,如果需要高效的隨即訪問,而不在乎插入和洗掉的效率,使用 vector,
- list 擁有一段不連續的記憶體空間,如果需要高效的插入和洗掉,而不關心隨機訪問,則應使用 list,
請你來說一下一個 C++ 源檔案從文本到可執行檔案經歷的程序?
對于C++源檔案,從文本到可執行檔案一般需要四個程序:
- 預處理階段:對源代碼檔案中檔案包含關系(頭檔案)、預編譯陳述句(宏定義)進行分析和替換,生成預編譯檔案,
相關命令:gcc -E man.c -o main.i - 編譯階段:將經過預處理后的預編譯檔案轉換成特定匯編代碼,生成匯編檔案,
相關命令:gcc -S man.i -o main.s - 匯編階段:將編譯階段生成的匯編檔案轉化成機器碼,生成可重定位目標檔案,
相關命令:gcc -c man.s -o main.o - 鏈接階段:將多個目標檔案及所需要的庫連接成最終的可執行目標檔案,
相關命令:gcc man.o -o main
請你來回答一下include頭檔案的順序以及雙引號" "和尖括號< > 的區別,
對于使用雙引號包含的頭檔案,查找頭檔案路徑的順序為:
- 當前頭檔案目錄→編譯器設定的頭檔案目錄→系統變數指定的頭檔案路徑
對于使用尖括號包含的頭檔案,查找頭檔案的路徑順序為:
- 編譯器設定的頭檔案路徑→系統變數指定的頭檔案路徑
什么是紅黑樹?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/291681.html
標籤:其他
上一篇:buildroot 重新編譯內核